 電子發燒友App
電子發燒友App


第二,愈來愈寬的數據池與越來越強大的計算機運算功能的出現和發展協同機器學習和深度學習(與更多的數據和計算功能)的發展,將會影響全行業的所有公司;
第三, AI即服務(AI-as-a-service)的發展將會打開一個全新的市場;
第四,高盛認為,一個公司若能很好的運用AI。它將會獲得有利的競爭優勢;
人工智能將帶來變革
從人類告訴計算機如何去做,到計算機自己學會去做,人工智能不斷發展。它對全行業都有著深遠影響。也許在下一個冬天(AI Winter)到來之前,我們并不知道這究竟是希望還是失望。但起碼,這些投資與新技術可以讓我們享有機器學習所帶來的效率提升與經濟益處。
過去幾年,人工智能、機器人、無人駕駛汽車成了熱詞。我們認為,這是一個轉折點,而不是一個失敗嘗試的開始。其中既有較為明顯的原因(如更多的數據、更快的計算機運算能力),也有些沒那么容易察覺、比較細微的原因(如深度學習的跨越式發展、專用硬件、開源服務的增加)。
人工智能的運用并不僅僅局限于遠在天邊的技術界,其商業化運用比比皆是,從蘋果公司的Siri(自然語言處理),亞馬遜的Alexa(自然語言處理),到谷歌的識圖技術(計算機視覺與圖像識別)。隨著技術的發展,這些產品與服務的質量也越來越高。當大數據與強大技術結合,新的增值點與競爭力就這樣誕生了。許多例子皆可佐證這一論據,在醫療行業中,圖像識別技術可以提高癌癥診斷的準確率。在農業中,農民可采用深度學習技術來提高稻物產量。在能源行業中,勘探效率得以提升。在金融服務業,分析的成本降低了,也更快了。雖然AI還在其發展的初期,但隨著通過云端服務的逐漸普及,我們相信一波新的創新潮流即將到來,未來便可見,在每個行業中,誰是贏家,誰是輸家。
我們也認為,人工智能的廣泛使用會提高效率并促進全球經濟;對美國而言,經濟滯脹將會停止。如同在90年代一般,AI技術的迸發,將促使大公司投入更多資本到資本和勞動密集型項目中,以此推動經濟增長;企業的利潤率以及股票皆會提升。
人工智能是一門讓機器或電腦軟件可以學習、解決一些,通常需要人類智慧才能學習或解決的知識和問題的科學和工程。人工智能也是在描述計算機試圖模擬一種智能行為;比如說試圖模擬像人類一般的“知識”,“常識”,“學習技能”以及“決策分析”。傳統意義上說,這包含自然語言處理和翻譯、視覺感知、模式識別以及決策技能,不過因為隨著人工智能的領域愈來愈寬,人工智能的內涵也越來越復雜了。
在本報告中,我們的關注重點是人工智能中的機器學習和深度學習(機器學習的一部分):
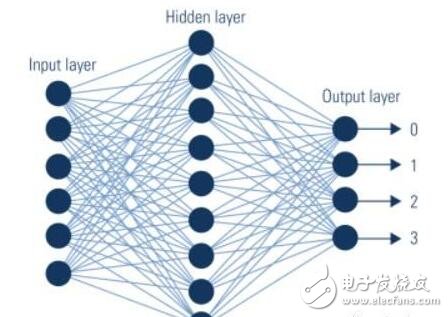
1.簡單來說,機器學習(machine learning)是一種從案例和經驗(如數據組)中學習,而非通過已編程好或已定義好的規則的一種算法。換句話說,如果是“非機器學習”,程序員需要“告訴”一個程序如何鑒別蘋果和橙子,而機器學習的方式則是被“喂養”(訓練)數據并自我學習如何鑒別蘋果和橙子。現實生活中,網飛(Netflix)就通過大量的用戶數據來引導機器學習,從而為用戶推薦定制化的推薦劇集與產品;神經網絡(neural network),則是一種模擬人類大腦神經網絡學習方式的一種機器學習架構,就如同下圖顯示的:
2. 當今人工智能的拐點(AI inflection)是深度學習(這是一種通過交錯復雜的神經網絡的深度層互相分工,聚焦一個大問題的不同層面,在協同解決完一個個小問題后,把大問題解決)。在許多傳統的機器學習訓練方法中,特征(即可被預測的“輸入”或“特性”)是人類設計的。而“特征工程”(feature engineering)其實是一個較難突破的瓶頸,因為它需要極強的專業知識。在非監督深度學習(監督式和非監督式學習的區別可以用如下例子表述,前者可能是被“喂養”一系列“關鍵詞”,而當檢測到這些詞匯時,它們將被標注成“垃圾郵件”,而后者可能不會被給予有關的信息,而要機器自己去摸索并識別出規律[pattern])中,重要的特征并不是人類預先設計好的,而是由算法自我產生并學習的。
最后,我們想強調一點,我們關注的是能夠量化的、可以快速產生經濟效益的相關人工智能技術,而非那種可以像人類一般思考的強人工智能(即使AlphaGo擊敗圍棋冠軍算是這一領域的重大突破)。
理清其他概念
1.什么是有監督學習(supervised learning)與無監督學習(unsupervisedlearning)?
a. 在有監督學習中,機器通過不斷學習“正確答案”來提高預測準確率,比如說垃圾郵件的檢測(每當有特定字符出現時,系統便將他們標記為“垃圾郵件”);
b. 而無監督學習更多的是被給予一系列無標簽的例子(也沒有正確答案),并要求系統自己發現一種規律。例子:將消費者以某種特征進行分類(比如說:購買頻次)。
2.機器學習的一些類別是什么?
a. 分類(Classification):垃圾郵件分類、欺詐識別、臉部識別、語音識別等。
b. 聚類(Clustering):比較圖片、文本或尋找類似事物,判斷異常的“類別”。
c. 預測(Predictive):根據可穿戴設備的數據預測健康問題,根據網絡活動來推測顧客、雇員的人員調整更替率。
3. 什么是強人工智慧(General/Strong/True Artificial Intelligence)
強人工智能指的是可以完全像人類一樣獨立思考和決策的機器智能。雖然現在已經有全腦模擬(Whole Brain Emulation),但因為這種技術所需的計算量實在太過龐大,已然超出現有技術的水平;目前仍處于理論階段。
人工智能簡史

高盛認為,有四大因素:數據、人才、基礎設施、硅元素。
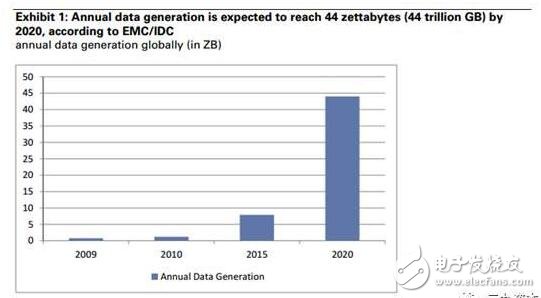
1. 高盛認為,數據是最關鍵的要素。數據的增多可以有效提高準確性(參考哈佛醫學院與馬薩諸塞總醫院放射學有關CT圖片診斷準確性的報告)。目前的深度學習都是有人類參與監管的,即使是所謂的“半監督式學習”,依然需要人類供應大量的數據(其中至少有一些,是有標簽印記的)。而完全不需要人類的自主學習,是現在深度學習追求的“圣杯”,還沒能實現。不過,現在已經有大量數據了,他們也會增加的更多。全世界的數據的年復合總增長率在2020年將會在36%,總量到達440億GB的量級。我們相信,電子健康記錄、天氣、地理數據會成為下一個二十年推動利潤池的力量。
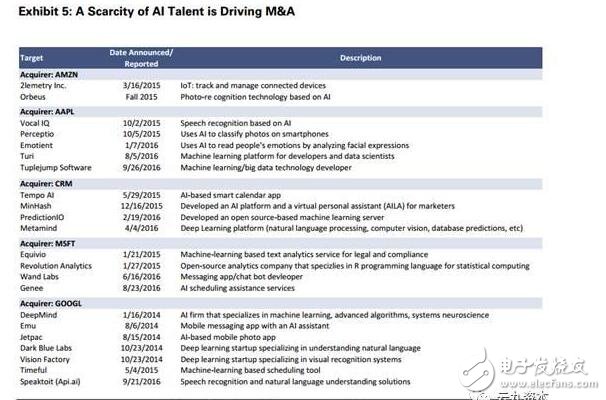
2. 人才短缺是制約人工智能,尤其是深度學習的關鍵因素。這也導致了過去幾年間各公司間收購頻繁(圖表5),我們發現,隨著技術的發展,這一因素對人工智能的發展的制約效應會變得稍微弱些,因為品類繁多的大量數據才將會是推進人工智能行業發展的關鍵要素。
3. 人工智能的發展非常依賴于硬件和基礎設施,隨著后兩者的完善,人工智能將會極速發展。這里我們提供兩個洞察。其一,云計算的提供商已經準備好為人工智能提供服務;其二,諸如TensorFlow, Caffe, Spark等開源平臺已經像雨后春筍般升騰而起,已經成為推動人工智能軟件創新的中堅力量。
4.硅元素:機器學習的算法是件資源密集型的事情,這通常是通過GPU(圖形處理器)系統完成。目前,對于機器學習中的特有運算模式Inference,已經有眾多公司提供相應的解決方案(特種硅FPGA和ASIC; Field Programmable Gate Array and ASICs Application SpecificIntegrated Circuit),比如說谷歌的Tensor處理器單元,就是ASIC型特種人工智能芯片,而微軟公司則是FPGA芯片。Xilinx,一家從1980年底就開始專注于FPGA芯片商用的領先公司,則說道未來的云計算和線下數據中心是未來新的營收增長點。
為什么人工智能的發展突然加速了?
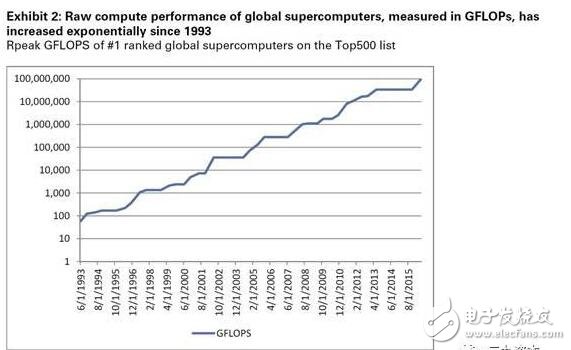
深度學習的跨越發展促使人工智能快速發展到接近拐點。神經網絡,深度學習的底層框架,早已問世許多年。在過去十年間,真正在推動深度學習的是,高盛認為,是下列因素:更多的數據(如大量新設備接入物聯網所產生數據;2020年數據預計將是2015年的4倍;圖1)、更快的硬件(GPU、CPU性能大大提升:從 1993 年開始超級計算機的原計算能力有了極大發展;一塊2016年的高端英偉達顯卡即可2002年前的一臺超級計算機的運轉(圖2),且相關價格更是連年走低[每一單位“運算”的價格](圖3))以及有更多質量卓越的算法可供選擇(大量優質的開源算法可以協助促進人工智能的發展,如Berkeley’sCaffe,谷歌的TensorFlow)。
對公司、和經濟的影響
人工智能的主要影響集中在四方面:生產率,先進技術、競爭優勢、新公司的誕生。
1.生產率:AI與機器學習將促使企業節省一些勞工相關開支,并真正的把預算花在開發產品和完善服務上(高盛首席經濟學家Jan Hatzius);宏觀上說,社會效率得到提升,經濟將會發展。
2.高端技術:AI與機器學習使得建造數據中心變得不那么昂貴,這將顛覆相關硬軟件與硬軟件服務公司的市場份額。舉個例子,同樣是GPU計算請求,使用 AI 優化過的GPU需要0.9美元/小時,現在通過亞馬遜云服務,僅需0.0065美元/小時即可達成。
3.競爭優勢:若不能及時采用AI與機器學習來指導商業發展,競爭對手就搶得先機了:戰略性情報、生產率提升、還有資本有效利用率(在即將到來的“下篇“,我們會特別討論人工智能在醫療、能源、零售、金融與農業行業中所帶來的變革)。
4.新公司的誕生:風險投資、創業家、與技術家將共同推動AI技術的發展,創造新價值。下一個“AI谷歌、臉書”也許就要到來。
對消費者的影響
消費者可以享受到更加智能的搜索優化(如谷歌新使用的RankBain人工智能搜索系統),發現搜索引擎變得更加聰明了(如亞馬遜DSSTNE引擎和網飛皆采用人工智能系統以協助決定推薦何種電影、產品、歌曲給用戶)、自己的臉變得更加易于被識別了(臉部識別-如谷歌的FaceNet和臉書的DeepFace已經可以達到近乎100%的臉部識別準確率了)。
人工智能與生產力
美國生產力增長近年已進入遲緩狀態,而我們相信人工智能的發展可以改變這一現狀,不僅是美國的,更是全球的,就好像1990年代互聯網科技所做出的改變一樣。
我們發現,在不同的行業中,我們觀察到自動化已然平均減少了0.5%-1.0%的工人工時,而人工智能、機器學習的效率提升可以在2025年前會帶來+51-154bps(基點)的效率提升。不過這主要影響到的低薪資任務;早期的影響將是低工資任務的自動化,即以更少的勞動時間推動類似的產出增長水平。
科技與生產力
1990年代的科技爆炸促使了經濟的增長,有兩個生產力要素大大提升:一是資本深化指標,二是多元素生產力(Multifactor productivity)。
但在2000年后,資本深化便停滯了。IT運用(電腦硬件、軟件、電信)在貢獻的資本逐漸下降,而工時卻增加了。隨著更加復雜的、更加“消費者版本”的機器學習和人工智能的引入,資本深度可能會提升,并可能可以巨幅提升生產力。不過,當我們在談論生產力的時候,一些“不可觸及”的產出(如線上內容)對于生產力的影響可能被忽略不計了。
人工智能與生產率的悖論:與高盛首席經濟學家JanHatzius的訪談:
在訪談中,Jan Hatzius先生提出幾個觀點(與人工智能主題有關的摘錄如下):
1. 經濟周期性、技術變革放緩、統計學家的統計工具無法精確量化最新技術的進展導致2000年后由科技推動的經濟增長的放緩(至少就數據本身而言是如此的)。
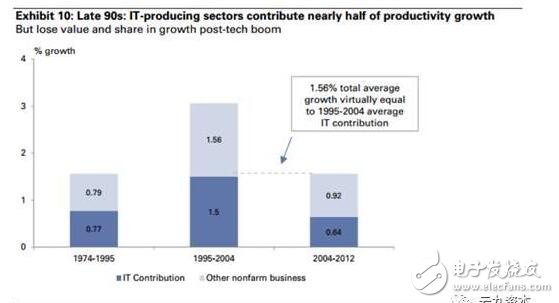
2. 人工智能的引進對于生產力的提高是顯而易見的(見圖13:1990年代的技術革命推動了生產力的增加,軟件公司在1995年到2000年數量激增,直到2000年整合,數量方才減少些),但從人均規模效益而言,可能并不會那么明顯。
3. 類似于人工智能搶走人類工作的憂慮在19世紀工業革命也發生過。短期而言,確實會有更多人失業。但就長期而言,人工智能并不會導致失業率上升。
人工智能“生態系統”:云服務,開源
我們相信人工智能將為影響所有行業,這是新的競爭性優勢;同時,對這一潮流置之不理的管理層將有可能無法在產品創新、勞工效率以及資本杠桿能力上有優勢。所以,我們相信,公司對人工智能的需求將會推動對人工智能的人才、服務、硬件需求
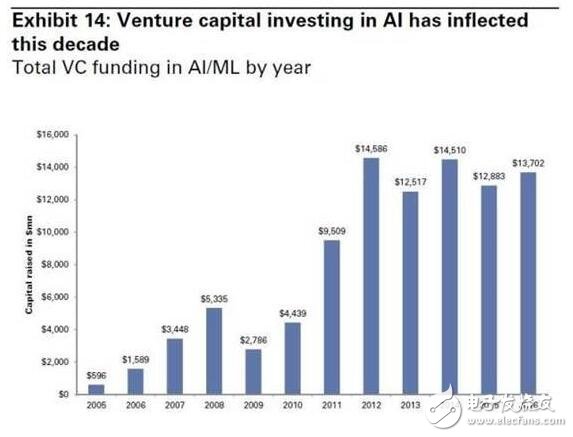
如圖14所示:過去20年,越來越多的風險資本進入人工智能、機器學習的領域。
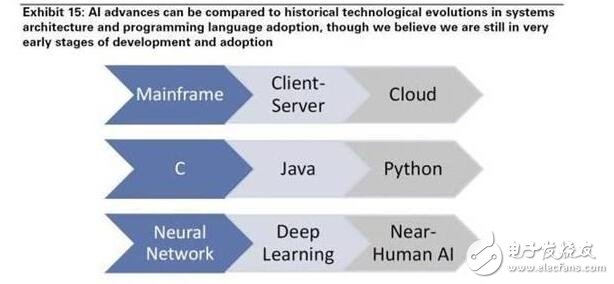
人工智能的概念早已被提出,其中,神經網絡的概念在60年代已被提出,但直到最近,因為計算能力的提升,我們才真正地能夠在實際上運用這些技術;系統架構層面,我們可以看到,從一開始到的大型機,到之后的客戶端,到近來的云端/移動端,包括新編程語言的出現(見圖15),這些都是計算能力、存儲能力,帶寬提升的效果;我們認為,我們仍處在人工智能發展的早期變化,而且各種工具和服務將出現爆炸式增長。
人工智能的促進者
1.自己動手型的企業:擁有優秀人才與大量數據的企業應該會自行建立機器學習的團隊。至此,我們可以看到AI堆正在形成,這里面我們認為,包含開源(比如說像Databricks,Cloudera, Hortonworks的供應商)以及云端平臺(比如微軟、谷歌、亞馬遜和百度)提供的服務。
2. 咨詢公司:AI仍是稀缺性資源,故像IBM這樣的企業正通過IBM Watsons建立起橫縱向的產業業務技術優勢。而像Kaggle這樣的公司,則通過數以千計的數據科學家,協助公司解決人工智能的問題。
3. AI即服務(AI-as-a-service, AI-aaS):這是我們自己定義的名詞,意思是說,企業無需自己訓練AI,但是他們可以通過第三方公司,直接使用已經被訓練好的深度學習AI機器。一個例子:創業公司Clarifai和谷歌公司專注圖像API的AI-aaS。另一個例子:Salesforce.com獨有的銷售數據。擁有獨特數據的公司將會很有競爭優勢。
機器學習(尤其是深度學習)是人工智能里較為新穎的領域。而我們相信,這一新穎技術正被互聯網公司,擅長提供特定行業服務的公司、財富五百強等眾多公司所利用。原本人工智能發展的障礙:數據和人才已逐漸被掃除;公司們逐漸學會了通過物聯網進行數據收集,這彌補了之前的數據缺失。而大量修習新興的機器學習專業的畢業生、愈來愈多相關人工智能的咨詢公司,都填補了人才方面的原有的空白。我們相信,大多數大公司(或是中小型的專注于數據的公司)至少,會嘗試機器/深度學習。因為創新速度較慢,要打造一條完整的機器學習產品管道線會比較困難,很多時候,這些發展都是比較“碎片化”的。
藍色是專有供應商,橙色指的是開源,綠色指的云服務(某一些供應商,比如說阿里巴巴和百度,都是專有、云服務共存的)。
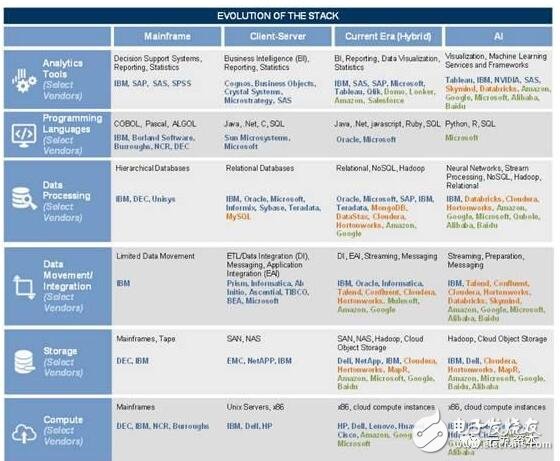
逐漸興起的AI“堆”與之前主機、客戶端都有著類似的工具、語言、存儲。
但AI堆與之前技術的不同點在于,機器學習的產品管道線非常依賴于第三方云端平臺所提供的開源科技和服務。
這一轉變有三大原因,1)機器學習需要持續在線的計算和存儲力來計算、存儲大量的數據 2)微軟、亞馬遜、谷歌對于機器學習的重投資 3大客戶對開源的擁抱態度來防止“反面模式”(vendor lock-in)并削減開支
中國的人工智能情況
根據艾瑞咨詢的分析報告,中國人工智能市場將從2015年的12億人民幣增加到91人民幣。但就2015年來說,就有14億人民幣(較2014年增長76%)的資本流入市場。
中國發改委與其他相關部門在2016年5月發布了《互聯網+人工智能三年行動實施方案》。方案指出六大保障領域:資本支持、體系標準化、知識產權保護、人才培養、國際合作與落地措施;并專注于在2018年完成對建設AI基礎設施與對應創新平臺、匹配的產業體系、創新服務體系與基本的標準化體系。
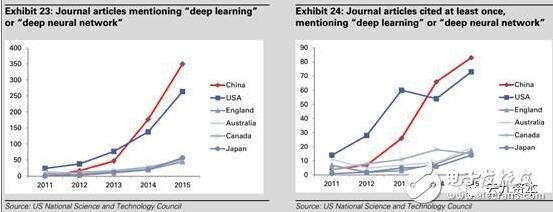
中國在人工智能上已有所突破。在有“深度學習”或“深度神經網絡”關鍵字的被引用論文數量的數據上,中國已經在這一數值上在2014年超過了美國(圖24)。中國的人工智能研究能力也是驚人的(圖23),尤其在語音、視覺識別技術方面。百度在2015年11月發布的Deep Speech 2系統已經可以獲得97%的準確率,甚至被《MIT科技評論》評委2016十大突破性科技之一。香港中文大學開發的DeepID系統在LFW(Labelled Faces in the Wild)中達到了99.15%的臉部識別準確率。
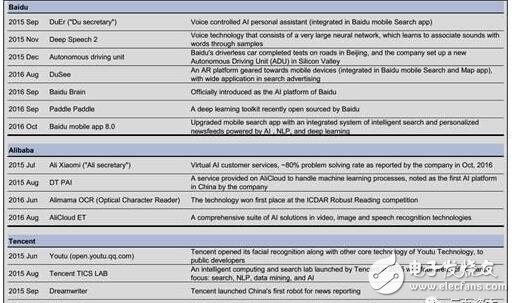
數以百計的中國人工智能公司正滲透到這個行業中,但行業的領軍者仍是百度、阿里巴巴和騰訊(BAT)(各公司產品見下圖;可以看到,百度專注于語音識別(Deep Speech)、自然語言處理、以優化個人語音助理“度秘”、搜索、地圖的運用;百度也有自己的無人車部門;阿里巴巴則開發了人工智能客服、基于云服務的人工智能平臺DT PAI、阿里媽媽光學字符識別、還有阿里云ET人工智能套件;騰訊(優圖)則潛心研究臉部識別技術、搜索、自然語言處理、數據挖掘、人工智能、新聞報道,并與香港科技大學成立人工智能聯合實驗室)。
目前,中國的人工智能主要集中于以下領域:
1. 基礎服務(如數據資源與計算平臺)
2. 硬件產品(如工業機器人和服務機器人)
3. 智能服務(如智能人工服務與商業智能)
4. 技術能力(視覺識別、機器學習)
語音、視覺識別技術在中國人工智能市場的60%和12.5%。
在和人工智能相關的公司中,71%致力應用開發,29%專注于算法。
在專注算法的公司中,55%在研究計算機視覺,13%專注于自然語言處理,9%把精力放在基礎機器學習上。
在我們看眼中,人工智能的領先者會繼續在中國和美國兩國中產生。
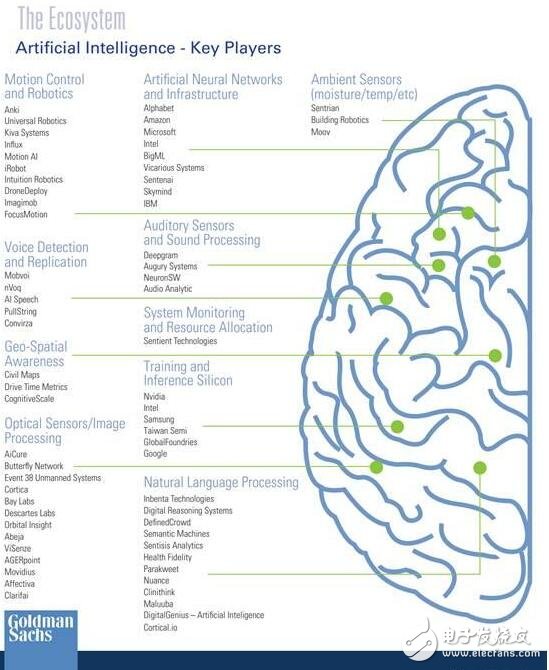
我們列出了在運動控制與機器人、語音識別與復制、地理空間感知、圖像感知與識別、人工神經網絡與基礎設施、聲頻感應與處理、系統監控與資源分配、訓練和Inference硅、自然語言處理、環境感應器(濕度、溫度等)這些領域的領軍者。
Sky9Capital云九資本(www.sky9capital.com)是專注于中國市場的早期創業投資基金品牌,關注創新的互聯網、企業服務和前沿科技行業。










 工商網監
工商網監
評論