 電子發(fā)燒友App
電子發(fā)燒友App


在之前講到的人臉測試后,提取出人臉來,并且保存下來,以供訓(xùn)練或識別是用,提取人臉的代碼如下:
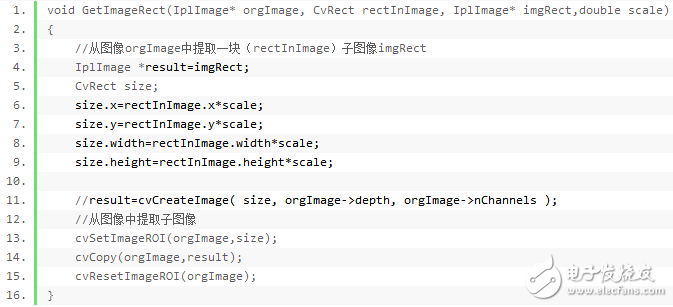
人臉預(yù)處理
現(xiàn)在你已經(jīng)得到一張人臉,你可以使用那張人臉圖片進行人臉識別。然而,假如你嘗試這樣簡單地從一張普通圖片直接進行人臉識別的話,你將會至少損失10%的準(zhǔn)確率!
在一個人臉識別系統(tǒng)中,應(yīng)用多種預(yù)處理技術(shù)對將要識別的圖片進行標(biāo)準(zhǔn)化處理是極其重要的。多數(shù)人臉識別算法對光照條件十分敏感,所以假如在暗室訓(xùn)練,在明亮的房間就可能不會被識別出來等等。這個問題可歸于“l(fā)umination dependent”,并且還有其它很多例子,比如臉部也應(yīng)當(dāng)在圖片的一個十分固定的位置(比如眼睛位置為相同的像素坐標(biāo)),固定的大小,旋轉(zhuǎn)角度,頭發(fā)和裝飾,表情(笑,怒等),光照方向(向左或向上等),這就是在進行人臉識別前,使用好的圖片預(yù)處理過濾器十分重要的原因。你還應(yīng)該做一些其它事情,比如去除臉部周圍的多余像素(如用橢圓遮罩,只顯示其內(nèi)部的人臉區(qū)域而不是頭發(fā)或圖片背景,因為他們的變化多于臉部區(qū)域)。
為簡單起見,我展示給你的人臉識別系統(tǒng)是使用灰度圖像的特征臉方法。所以我將向你說明怎樣簡單地把彩色圖像轉(zhuǎn)化為灰度圖像,并且之后簡單地使用直方圖均衡化(Histogram Equalization)作為一種自動的標(biāo)準(zhǔn)化臉部圖像亮度和對比度的方法。為了得到更好的結(jié)果,你可以使用彩色人臉識別(color face recognition,ideally with color histogram fitting in HSV or another color space instead of RGB),或者使用更多的預(yù)處理,比如邊緣增強(edge enhancement),輪廓檢測(contour detection),手勢檢測(motion detection),等等。
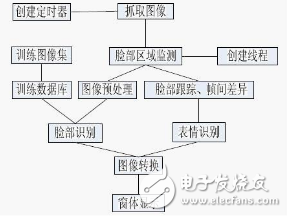
PCA原理
現(xiàn)在你已經(jīng)有了一張經(jīng)過預(yù)處理后的臉部圖片,你可以使用特征臉(PCA)進行人臉識別。OpenCV自帶了執(zhí)行PCA操作的”cvEigenDecomposite()”函數(shù),然而你需要一個圖片數(shù)據(jù)庫(訓(xùn)練集)告訴機器怎樣識別當(dāng)中的人。
所以你應(yīng)該收集每個人的一組預(yù)處理后的臉部圖片用于識別。比如,假如你想要從10人的班級當(dāng)中識別某個人,你可以為每個人存儲20張圖片,總共就有200張大小相同(如100×100像素)的經(jīng)預(yù)處理的臉部圖片。
特征臉的理論在Servo Magazine的兩篇文章(Face Recognition with Eigenface)中解釋了,但我仍會在這里嘗試著向你解釋。
我們使用“主元分析”把你的200張訓(xùn)練圖片轉(zhuǎn)換成一個代表這些訓(xùn)練圖片主要區(qū)別的“特征臉”集。首先它將會通過獲取每個像素的平均值,生成這些圖片的“平均人臉圖片”。然后特征臉將會與“平均人臉”比較。第一個特征臉是最主要的臉部區(qū)別,第二個特征臉是第二重要的臉部區(qū)別,等……直到你有了大約50張代表大多數(shù)訓(xùn)練集圖片的區(qū)別的特征臉。
在上面這些示例圖片中你可以看到平均人臉和第一個以及最后一個特征臉。注意到,平均人臉顯示的是一個普通人的平滑臉部結(jié)構(gòu),排在最前的一些特征臉顯示了一些主要的臉部特征,而最后的特征臉(比如Eigenface 119)主要是圖像噪聲。你可以在下面看到前32張?zhí)卣髂槨?/p>
簡單地說,特征臉方法(Principal Component Analysis)計算出了訓(xùn)練集中圖片的主要區(qū)別,并且用這些“區(qū)別”的組合來代表每幅訓(xùn)練圖片。
比如,一張訓(xùn)練圖片可能是如下的組成:
(averageFace) + (13.5% of eigenface0) – (34.3% of eigenface1) + (4.7% of eigenface2) + … + (0.0% of eigenface199)。
一旦計算出來,就可以認(rèn)為這張訓(xùn)練圖片是這200個比率(ratio):
{13.5, -34.3, 4.7, …, 0.0}。
用特征臉圖片分別乘以這些比率,并加上平均人臉圖片 (average face),從這200個比率還原這張訓(xùn)練圖片是完全可以做到的。但是既然很多排在后面的特征臉是圖像噪聲或者不會對圖片有太大作用,這個比率表可以被降低到只剩下最主要的,比如前30個,不會對圖像質(zhì)量有很大影響。所以現(xiàn)在可以用30個特征臉,平均人臉圖片,和一個含有30個比率的表,來代表全部的200張訓(xùn)練圖片。
在另一幅圖片中識別一個人,可以應(yīng)用相同的PCA計算,使用相同的200個特征臉來尋找200個代表輸入圖片的比率。并且仍然可以只保留前30個比率而忽略其余的比率,因為它們是次要的。然后通過搜索這些比率的表,尋找在數(shù)據(jù)庫中已知的20個人,來看誰的前30個比率與輸入圖片的前30個比率最接近。這就是尋找與輸入圖片最相似的訓(xùn)練圖片的基本方法,總共提供了200張訓(xùn)練圖片。
訓(xùn)練圖片
創(chuàng)建一個人臉識別數(shù)據(jù)庫,就是訓(xùn)練一個列出圖片文件和每個文件代表的人的文本文件,形成一個facedata.xml“文件。
比如,你可以把這些輸入一個名為”trainingphoto.txt”的文本文件:
joke1.jpg
joke2.jpg
joke3.jpg
joke4.jpg
lily1.jpg
lily2.jpg
lily3.jpg
lily4.jpg
它告訴這個程序,第一個人的名字叫“joke,而joke有四張預(yù)處理后的臉部圖像,第二個人的名字叫”lily”,有她的四張圖片。這個程序可以使用”loadFaceImgArray()”函數(shù)把這些圖片加載到一個圖片數(shù)組中。
為了從這些加載好的圖片中創(chuàng)建一個數(shù)據(jù)庫,你可以使用OpenCV的”cvCalcEigenObjects()”和”cvEigenDecomposite()”函數(shù)。
獲得特征空間的函數(shù):
void cvCalcEigenObjects( int nObjects, void* input, void* output, int ioFlags, int ioBufSize, void* userData,CvTermCriteria* calcLimit, IplImage* avg, float* eigVals )
nObjects:目標(biāo)的數(shù)目,即輸入訓(xùn)練圖片的數(shù)目。
input:輸入訓(xùn)練的圖片。
output:輸出特征臉,總共有nEigens
ioFlags、ioBufSize:默認(rèn)為0
userData:指向回調(diào)函數(shù)(callback function)必須數(shù)據(jù)結(jié)構(gòu)體的指針。
calcLimit:終止迭代計算目標(biāo)特征的條件。根據(jù)calcLimit的參數(shù),計算會在前nEigens主要特征目標(biāo)被提取后結(jié)束(這句話有點繞,應(yīng)該就是提取了前nEigens個特征值,),另一種結(jié)束的情況是:目前特征值同最s大特征值的比值降至calcLimit的epsilon值之下。
賦值如下calcLimit = cvTermCriteria( CV_TERMCRIT_ITER, nEigens, 1);
它的類型定義如下:
typedef struct CvTermCriteria
{
int type; int max_iter; //最大迭代次數(shù)
double epsilon; //結(jié)果精確性
}
avg:訓(xùn)練樣本的平均圖像
eigVals:以降序排列的特征值的行向量指針。可以為0。
最后將所得數(shù)據(jù)形成一個facedata.xml“文件保存下來,它可以隨時被重新載入來識別經(jīng)訓(xùn)練過的人。
圖像在特征空間的投影:
void cvEigenDecomposite( IplImage* obj, int nEigObjs, void* eigInput,int ioFlags, void* userData, IplImage* avg, float* coeffs );
obj:輸入圖像,訓(xùn)練或識別圖像
nEigObjs:特征空間的eigen數(shù)量
eigInput:特征空間中的特征臉
ioFlags、userData:默認(rèn)為0
avg:特征空間中的平均圖像
coeffs:這是唯一一個輸出,即人臉在子空間的投影,特征值
識別的過程
1. 讀取用于測試的圖片。
2. 平均人臉,特征臉和特征值(比率)使用函數(shù)“l(fā)oadTrainingData()” 從人臉識別數(shù)據(jù)庫文件(the face recognition database fil)“facedata.xml”載入。
3. 使用OpenCV的函數(shù)“cvEigenDecomposite()”,每張輸入的圖片都被投影到PCA子空間,來觀察哪些特征臉的比率最適合于代表這張圖片。
4. 現(xiàn)在有了特征值(特征臉圖片的比率)代表這張輸入圖片,程序需要查找原始的訓(xùn)練圖片,找出擁有最相似比率的圖片。這些用數(shù)學(xué)的方法在“findNearestNeighbor()”函數(shù)中執(zhí)行,采用的是“歐幾里得距離(Euclidean Distance)”,但是它只是基本地檢查輸入圖片與每張訓(xùn)練圖片的相似性,找到最相似的一張:一張在歐幾里得空間上與輸入圖片距離最近的圖片。就像在 Servo Magazine的文章上提到的那樣,如果使用馬氏距離( the Mahalanobis space,需要在代碼里定義 USE_MAHALANOBIS_DISTANCE),你可以得到更準(zhǔn)確的結(jié)果。
5. 在輸入圖片與最相似圖片之間的距離用于確定可信度(confidence),作為是否識別出某人的指導(dǎo)。1.0的可信度意味著完全相同,0.0或者負(fù)的可信度意味著非常不相似。但是需要注意,我在代碼中用到的可信度公式只是一個非常基本的可信度測量,不是很可靠,但是我覺得多數(shù)人會想要看到一個粗略的可信度值。你可能發(fā)現(xiàn)它對你的圖片給出錯誤的值,所以你可以禁用它(比如:把可信度設(shè)為恒定的1.0)。
一旦指導(dǎo)哪張訓(xùn)練圖片和輸入圖片最相似,并假定可信度值不是太低(應(yīng)該至少是0.6或更高),那么它就指出了那個人是誰,換句話說,它識別出了那個人!











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論