 電子發燒友App
電子發燒友App


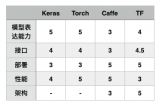
總體來講keras這個深度學習框架真的很“簡易”,它體現在可參考的文檔寫的比較詳細,不像caffe,裝完以后都得靠技術博客,keras有它自己的官方文檔(不過是英文的),這給初學者提供了很大的學習空間。
這個文檔必須要強推!英文nice的可以直接看文檔,我這篇文章就是用中文來講這個事兒。
Keras官方文檔
首先要明確一點:我沒學過Python,寫代碼都是需要什么百度什么的,所以有時候代碼會比較冗余,可能一句話就能搞定的能寫很多~
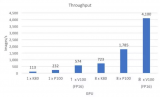
論文引用——3.2 測試平臺
項目代碼是在Windows 7上運行的,主要用到的Matlab R2013a和Python,其中Matlab用于patch的分割和預處理,卷積神經網絡搭建用到了根植于Python和Theano的深度學習框架Keras。Keras是基于Theano的一個深度學習框架,它的設計參考了Torch,用Python語言編寫,是一個高度模塊化的神經網絡庫,支持GPU和CPU,用起來特別簡單,適合快速開發。
基于Theano的深度學習(Deep Learning)框架Keras學習隨筆-12-核心層
基于Theano的深度學習(Deep Learning)框架Keras學習隨筆-13-卷積層
1. 直接上卷積神經網絡構建的主函數
def create_model(data):
model = Sequential()
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’, input_shape=data.shape[-3:]))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Convolution2D(32, 3, 3, border_mode=‘valid’))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3, border_mode=‘valid’))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512, init=‘normal’))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Dense(LABELTYPE, init=‘normal’))
model.add(Activation(‘softmax’))
sgd = SGD(l2=0.0, lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=‘categorical_crossentropy’, optimizer=sgd, class_mode=“categorical”)
return model
這個函數相當的簡潔清楚了,輸入訓練集,輸出一個空的神經網絡,其實就是卷積神經網絡的初始化。model = Sequential()是給神經網絡起了頭,后面的model.add()是一直加層,像搭積木一樣,要什么加什么,卷積神經網絡有兩種類型的層:1)卷積,2)降采樣,對應到代碼上是:
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’))
# 加一個卷積層,卷積個數64,卷積尺寸5*5
model.add(MaxPooling2D(pool_size=(2, 2)))
# 加一個降采樣層,采樣窗口尺寸2*2
1.1 激活函數
注意:每個卷積層后面要加一個激活函數,就是在教科書上說的這個部分

它可以將卷積后的結果控制在某一個數值范圍內,如0~1,-1~1等等,不會讓每次卷積完的數值相差懸殊
對應到代碼上是這句:
model.add(Activation(‘relu’))
這個激活函數(Activation)keras提供了很多備選的,我這兒用的是ReLU這個,其他還有
tanh
sigmoid
hard_sigmoid
等等,keras庫是不斷更新的,新出來的論文里面用到的更優化的激活函數里面也會有收錄,比如:
LeakyReLU
PReLU
ELU
等等,都是可以替換的,美其名曰“優化網絡”,其實就只不過是改一下名字罷了哈哈,內部函數已經都幫你寫好了呢。注意一下:卷積神經網絡的最后一層的激活函數一般就是選擇“softmax”。我這兒多說一嘴這些激活函數應該怎么去選擇吧,一句話

參考的是這篇文章
原因分別是

導致梯度消失,不是零中心

導致梯度消失

x《0時梯度沒了

我知道Leaky ReLU已經有現成的了,但是暫時還沒有用,現在還用的是ReLU這個,別問我為什么:)
1.2 Dropout層
棄權(Dropout):針對“過度擬合”問題

不讓某些神經元興奮
人腦在處理信號的時候并不是所有的神經元都處于興奮狀態的,原因是1) 大腦的能量供給跟不上,2)神經元的特異性,特定的神經元處理特定信號,3) 全部的神經元都激活的話增加了反應時間。所以我們用神經網絡模擬的也要有所取舍,比如把信號強度低于某個值的神經元都抑制下來,這樣能提高了網絡的速度和魯棒性,降低“過擬合”的可能性。額,廢話不說了,反正就是好!體現在代碼上是這個:
model.add(Dropout(0.5))
這個0.5可以改,意思是信號強度排在后50%的神經元都被抑制,就是把他們都扔掉~
1.3 還有點細節
到現在為止對這個網絡初始化的函數應該只有一些小東西不清楚了吧:
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’, input_shape=data.shape[-3:]))
你會發現第一個卷積層代碼比其他的長,原因是它還需要加上訓練集的一些參數,也就是input_shape = data.shape[-3:]這個,它的意思是說明一下訓練集的樣本有幾個通道和每個輸入圖像的尺寸,我這兒是

data.shape[-3:],表示我用了六通道,每個patch的尺寸是24*24像素。
通道的概念就是比如一幅黑白圖,就是一通道,即灰度值;一幅彩色圖就是三通道,即RGB;當然也可以不用顏色作為通道,比如我用的六通道。但是通道內部的機制我并不是很清楚,可能它就是為RGB設置的也說不定。這兒打一個問號?
model.add(Flatten())
model.add(Dense(512, init=‘normal’))
這兒加個一個全連接層,就是這兩句代碼,相當于卷積神經網絡中的這個

512意思就是這個層有512個神經元
沒什么可說的,就是模型里的一部分,可以有好幾層,但一般放在網絡靠后的地方。
sgd = SGD(l2=0.0, lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=‘categorical_crossentropy’, optimizer=sgd, class_mode=“categorical”)
這部分就是傳說中的“梯度下降法”,它用在神經網絡的反饋階段,不斷地學習,調整每一層卷積的參數,即所謂“學習”的過程。我這兒用的是最常見的sgd,參數包括學習速度(lr),,雖然吧其他的參數理論上也能改,但是我沒有去改它們,呵呵。
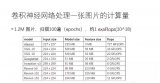
小建議:學習參數一般比較小,我用的是0.01,這個是根據不同的訓練集數據決定的,太小的話訓練的速度很慢,太大的話容易訓練自爆掉,像這樣

圓圈是當前位置,五角星是目標位置,若學習速度過快容易直接跳過目標位置,導致訓練失敗
對于keras提供的其他反饋的方法(Optimizer),我并沒有試過,也不清楚它們各自的優缺點,這兒列舉幾個其他的可選方法:
RMSprop
Adagrad
Adadelta
Adam
Adamax
等等,我猜每一個方法都能對應一篇深度學習的論文吧,代碼keras已經都提供了,想了解詳情就去追溯論文吧。這兒我提一嘴代價函數的事兒,針對“學習緩慢”和“過渡擬合”問題,有提出對代價函數進行修改的方法。道理都懂,具體在keras的哪兒做修改我還在摸索中,先來講一波道理:

由此可見,比較好的代價函數是

找機會把keras內部這一部分的代碼改了
主代碼部分,The End
2. 訓練前期代碼
在開始訓練以前需要做幾個步驟
導入需要的python包
導入數據
瓜分訓練集和測試集
2.1 相關的python包導入
#coding:utf-8
‘’‘
GPU run command:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python cnn.py
CPU run command:
python cnn.py
’‘’
######################################
# 導入各種用到的模塊組件
######################################
# ConvNets的模塊
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.advanced_activations import PReLU, LeakyReLU
import keras.layers.advanced_activations as adact
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax
from keras.utils import np_utils, generic_utils
from six.moves import range
from keras.callbacks import EarlyStopping
# 統計的模塊
from collections import Counter
import random, cPickle
from cutslice3d import load_data
from cutslice3d import ROW, COL, LABELTYPE, CHANNEL
# 內存調整的模塊
import sys
這兒就沒的說了,相當于C語言里面的#include,后面要用到什么就導入什么。對了具體導入哪些包就是去keras安裝的位置看看,我的安裝路徑是
C:UsersAdministratorAnaconda2Libsite-packageskeras
你會看到一個個的.py文件

keras目錄下就這樣子的
比如你需要導入Sequential()這個函數的話首先得知道它在keras的models.py中定義的,然后就很自然的出來這個代碼
from keras.models import Sequential
# 從keras的models.py中導入Sequential。
你看,代碼簡單的都能直譯了。難點是你根本不知道Sequential()函數在哪兒定義的,這個就需要好好地去系統得看一下keras的文檔了,這么多函數我這兒也不可能逐一舉例。
這部分我個人感覺挺需要python的知識,因為除去keras,很多包都蠻有用的,有了這些函數能省不少事兒。舉例:
from collections import Counter
作用是統計一個矩陣里面的不同元素分別出現的次數,落實到后面的代碼就是
cnt = Counter(A)
for k,v in cnt.iteritems():
print (‘\t’, k, ‘--》’, v)
# 實現了統計A矩陣的元素各自出現的次數
2.2 數據的簡單處理模塊
######################################
# 對于本次試驗的描述
######################################
print(“\n\n\nHey you, this is a trial on malignance and benign tumors detection via ConvNets. I‘m Zongwei Zhou. :)”)
print(“Each input patch is 51*51, cutted from 1383 3d CT & PT images. The MINIMUM is above 30 segment pixels.”)
######################################
# 加載數據
######################################
print(“》》 Loading Data 。。.”)
TrData, TrLabel, VaData, VaLabel = load_data()
######################################
# 打亂數據
######################################
index = [i for i in range(len(TrLabel))]
random.shuffle(index)
TrData = TrData[index]
TrLabel = TrLabel[index]
print(’\tTherefore, read in‘, TrData.shape[0], ’samples from the dataset totally.‘)
# label為0~1共2個類別,keras要求格式為binary class matrices,轉化一下,直接調用keras提供的這個函數
TrLabel = np_utils.to_categorical(TrLabel, LABELTYPE)
這兒我用到了一個load_data()函數,是自己寫的,就是一個數據導入,從.mat文件中分別讀入訓練集和測試集。也就是對于輸入patch的平移,旋轉變換以及訓練集測試集劃分都是在MATLAB中完成的,得到的數據量爆大,截止到4月7日,我的訓練集以及達到了31.4GB的規模,而python端的函數就比較直觀了,是這樣的
def load_data():
######################################
# 從.mat文件中讀入數據
######################################
mat_training = h5py.File(DATAPATH_Training);
mat_training.keys()
Training_CT_x = mat_training[Training_CT_1];
Training_CT_y = mat_training[Training_CT_2];
Training_CT_z = mat_training[Training_CT_3];
Training_PT_x = mat_training[Training_PT_1];
Training_PT_y = mat_training[Training_PT_2];
Training_PT_z = mat_training[Training_PT_3];
TrLabel = mat_training[Training_label];
TrLabel = np.transpose(TrLabel);
Training_Dataset = len(TrLabel);
mat_validation = h5py.File(DATAPATH_Validation);
mat_validation.keys()
Validation_CT_x = mat_validation[Validation_CT_1];
Validation_CT_y = mat_validation[Validation_CT_2];
Validation_CT_z = mat_validation[Validation_CT_3];
Validation_PT_x = mat_validation[Validation_PT_1];
Validation_PT_y = mat_validation[Validation_PT_2];
Validation_PT_z = mat_validation[Validation_PT_3];
VaLabel = mat_validation[Validation_label];
VaLabel = np.transpose(VaLabel);
Validation_Dataset = len(VaLabel);
######################################
# 初始化
######################################
TrData = np.empty((Training_Dataset, CHANNEL, ROW, COL), dtype = “float32”);
VaData = np.empty((Validation_Dataset, CHANNEL, ROW, COL), dtype = “float32”);
######################################
# 裁剪圖片,通道輸入
######################################
for i in range(Training_Dataset):
TrData[i,0,:,:]=Training_CT_x[:,:,i];
TrData[i,1,:,:]=Training_CT_y[:,:,i];
TrData[i,2,:,:]=Training_CT_z[:,:,i];
TrData[i,3,:,:]=Training_PT_x[:,:,i];
TrData[i,4,:,:]=Training_PT_y[:,:,i];
TrData[i,5,:,:]=Training_PT_z[:,:,i];
for i in range(Validation_Dataset):
VaData[i,0,:,:]=Validation_CT_x[:,:,i];
VaData[i,1,:,:]=Validation_CT_y[:,:,i];
VaData[i,2,:,:]=Validation_CT_z[:,:,i];
VaData[i,3,:,:]=Validation_PT_x[:,:,i];
VaData[i,4,:,:]=Validation_PT_y[:,:,i];
VaData[i,5,:,:]=Validation_PT_z[:,:,i];
print ’\tThe dimension of each data and label, listed as folllowing:‘
print ’\tTrData : ‘, TrData.shape
print ’\tTrLabel : ‘, TrLabel.shape
print ’\tRange : ‘, np.amin(TrData[:,0,:,:]), ’~‘, np.amax(TrData[:,0,:,:])
print ’\t\t‘, np.amin(TrData[:,1,:,:]), ’~‘, np.amax(TrData[:,1,:,:])
print ’\t\t‘, np.amin(TrData[:,2,:,:]), ’~‘, np.amax(TrData[:,2,:,:])
print ’\t\t‘, np.amin(TrData[:,3,:,:]), ’~‘, np.amax(TrData[:,3,:,:])
print ’\t\t‘, np.amin(TrData[:,4,:,:]), ’~‘, np.amax(TrData[:,4,:,:])
print ’\t\t‘, np.amin(TrData[:,5,:,:]), ’~‘, np.amax(TrData[:,5,:,:])
print ’\tVaData : ‘, VaData.shape
print ’\tVaLabel : ‘, VaLabel.shape
print ’\tRange : ‘, np.amin(VaData[:,0,:,:]), ’~‘, np.amax(VaData[:,0,:,:])
print ’\t\t‘, np.amin(VaData[:,1,:,:]), ’~‘, np.amax(VaData[:,1,:,:])
print ’\t\t‘, np.amin(VaData[:,2,:,:]), ’~‘, np.amax(VaData[:,2,:,:])
print ’\t\t‘, np.amin(VaData[:,3,:,:]), ’~‘, np.amax(VaData[:,3,:,:])
print ’\t\t‘, np.amin(VaData[:,4,:,:]), ’~‘, np.amax(VaData[:,4,:,:])
print ’\t\t‘, np.amin(VaData[:,5,:,:]), ’~‘, np.amax(VaData[:,5,:,:])
return TrData, TrLabel, VaData, VaLabel
讀入.mat中儲存的數據,輸出的就直接是劃分好的訓練集(TrData, TrLabel)和測試集(VaData, VaLabel)啦,比較簡單,不展開說了。關于MATLAB端的數據拓展(Data Augmentation),我將在后續再介紹。說明一下數據拓展的作用也是針對“過度擬合”問題的。
注意一點:我的label為0~1共2個類別,keras要求格式為binary class matrices,所以要轉化一下,直接調用keras提供的這個函數np_utils.to_categorical()即可。
3. 訓練中后期代碼
前面的硬骨頭啃完了,這兒就是向開玩笑一樣,短短幾句代碼解決問題。
print(“》》 Build Model 。。.”)
model = create_model(TrData)
######################################
# 訓練ConvNets模型
######################################
print(“》》 Training ConvNets Model 。。.”)
print(“\tHere, batch_size =”, BATCH_SIZE, “, epoch =”, EPOCH, “, lr =”, LR, “, momentum =”, MOMENTUM)
early_stopping = EarlyStopping(monitor=’val_loss‘, patience=2)
hist = model.fit(TrData, TrLabel, \
batch_size=BATCH_SIZE, \
nb_epoch=EPOCH, \
shuffle=True, \
verbose=1, \
show_accuracy=True, \
validation_split=VALIDATION_SPLIT, \
callbacks=[early_stopping])
######################################
# 測試ConvNets模型
######################################
print(“》》 Test the model 。。.”)
pre_temp=model.predict_classes(VaData)
3.1 訓練模型
先調用1. 直接上卷積神經網絡構建的主函數中的函數create_model()建立一個初始化的模型。然后的訓練主代碼就是一句話
hist = model.fit(TrData, TrLabel, \
batch_size=100, \
nb_epoch=10, \
shuffle=True, \
verbose=1, \
show_accuracy=True, \
validation_split=0.2, \
callbacks=[early_stopping])
:)沒錯,就一句話,不過這句話里面的事兒稍微比較多一點。。。我這兒就簡單列舉一下我關注的項:
TrData:訓練數據
TrLabel:訓練數據標簽
batch_size:每次梯度下降調整參數是用的訓練樣本
nb_epoch:訓練迭代的次數
shuffle:當suffle=True時,會隨機打算每一次epoch的數據(默認打亂),但是驗證數據默認不會打亂。
validation_split:測試集的比例,我這兒選了0.2。注意,這和2.2 數據的簡單處理模塊中的測試集不是一個東西,這個測試集是一次訓練的測試集,也就是下次訓練他有可能變成訓練集了。而2.2 數據的簡單處理模塊中的是全局的測試集,對于訓練好的網絡做的最終測試。
early_stopping:是否提前結束訓練,網絡自己判斷,當本次訓練和上次訓練的結果差不多了自動回停止訓練迭代,也就是不一定訓練完nb_epoch(10)次哦
early_stopping的調用在這兒
early_stopping = EarlyStopping(monitor=’val_loss‘, patience=2)
其他的都是和訓練的時候的界面有關,按照我的或者默認的來就可以了:)
提一嘴,如果你想要看每一次的訓練的結果是可以做到的!hist = model.fit()的hist中存放的是每一次訓練完的結果和測試精確度等信息。
再來一嘴,如果你想要看每一層的輸出的啥,也是可以做到的!
這個可以用到卷積神經網絡和其他傳統分類器結合來優化softmax方法的實驗,涉及到比較高級的算法了,我以后再說。這兒先只放上看每一層輸出的代碼:
get_feature = theano.function([origin_model.layers[0].input],origin_model.layers[12].get_output(train=False),allow_input_downcast=False)
feature = get_feature(data)
好吧,再提供一下SVM和Random Forests的Python函數代碼吧,如果大家想做這個實驗可以用哈:
######################################
# SVM
######################################
def svc(traindata,trainlabel,testdata,testlabel):
print(“Start training SVM.。。”)
svcClf = SVC(C=1.0,kernel=“rbf”,cache_size=3000)
svcClf.fit(traindata,trainlabel)
pred_testlabel = svcClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print(“\n》》 cnn-svm Accuracy”)
prt(testlabel, pred_testlabel)
######################################
# Random Forests
######################################
def rf(traindata,trainlabel,testdata,testlabel):
print(“Start training Random Forest.。。”)
rfClf = RandomForestClassifier(n_estimators=100,criterion=’gini‘)
rfClf.fit(traindata,trainlabel)
pred_testlabel = rfClf.predict(testdata)
print(“\n》》 cnn-rf Accuracy”)
prt(testlabel, pred_testlabel)
收~打住。
3.2 測試模型
呼呼,這個最水,也是一句話
pre_temp=model.predict_classes(VaData)
套用一個現有函數predict_classes()輸入測試集VaData,返回訓練完的網絡的預測結果pre_temp。好了,最后把pre_temp和正確的測試集標簽VaLabel對比一下,就知道這個網絡訓練的咋樣了,實驗階段性勝利!發個截圖:

Everybody Happy
3.3 保存模型
訓練一個模型不容易,不但需要調整參數,調整網絡結構,訓練的時間還特別長,所以要學會保存訓練完的網絡,代碼是這樣的:
######################################
# 保存ConvNets模型
######################################
model.save_weights(’MyConvNets.h5‘)
cPickle.dump(model, open(’。/MyConvNets.pkl‘,“wb”))
json_string = model.to_json()
open(W_MODEL, ’w‘).write(json_string)
就保存好啦,是這三個文件

保存的模型文件
當你回頭要調用這個網絡時,用這個代碼就可以了
model = cPickle.load(open(’MyConvNets.pkl’,“rb”))
model中就讀入了pkl文件內存儲的模型啦。



















 工商網監
工商網監
評論