 電子發燒友App
電子發燒友App


前言
直接上代碼是最有效的學習方式。這篇教程通過由一段簡短的 python 代碼實現的非常簡單的實例來講解 BP 反向傳播算法。
?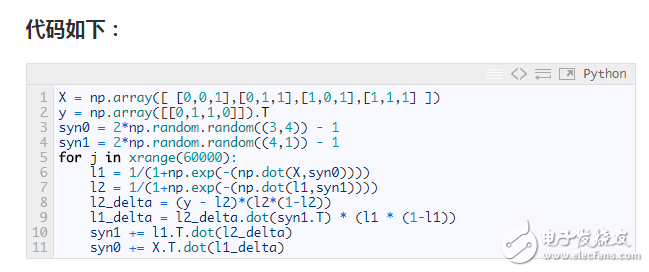
當然,上述程序可能過于簡練了。下面我會將其簡要分解成幾個部分進行探討。
第一部分:一個簡潔的神經網絡
一個用 BP 算法訓練的神經網絡嘗試著用輸入去預測輸出。
?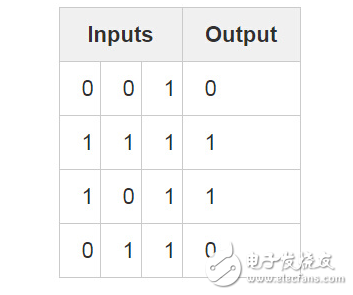
考慮以上情形:給定三列輸入,試著去預測對應的一列輸出。我們可以通過簡單測量輸入與輸出值的數據來解決這一問題。這樣一來,我們可以發現最左邊的一列輸入值和輸出值是完美匹配/完全相關的。直觀意義上來講,反向傳播算法便是通過這種方式來衡量數據間統計關系進而得到模型的。下面直入正題,動手實踐。
2 層神經網絡:
?
[[ 0.00966449]
[ 0.00786506]
[ 0.99358898]
[ 0.99211957]]
變量 定義說明
X 輸入數據集,形式為矩陣,每 1 行代表 1 個訓練樣本。
y 輸出數據集,形式為矩陣,每 1 行代表 1 個訓練樣本。
l0 網絡第 1 層,即網絡輸入層。
l1 網絡第 2 層,常稱作隱藏層。
Syn 第一層權值,突觸 0 ,連接 l0 層與 l1 層。
0
* 逐元素相乘,故兩等長向量相乘等同于其對等元素分別相乘,結果為同等長度的向量。
– 元素相減,故兩等長向量相減等同于其對等元素分別相減,結果為同等長度的向量。
x.dot(y) 若 x 和 y 為向量,則進行點積操作;若均為矩陣,則進行矩陣相乘操作;若其中之一為矩陣,則進行向量與矩陣相乘操作。
正如在“訓練后結果輸出”中看到的,程序正確執行!在描述具體過程之前,我建議讀者事先去嘗試理解并運行下代碼,對算法程序的工作方式有一個直觀的感受。最好能夠在 ipython notebook 中原封不動地跑通以上程序(或者你想自己寫個腳本也行,但我還是強烈推薦 notebook )。下面是對理解程序有幫助的幾個關鍵地方:
· 對比 l1 層在首次迭代和最后一次迭代時的狀態。
· 仔細察看 “nonlin” 函數,正是它將一個概率值作為輸出提供給我們。
· 仔細觀察在迭代過程中,l1_error 是如何變化的。
· 將第 36 行中的表達式拆開來分析,大部分秘密武器就在這里面。
· 仔細理解第 39 行代碼,網絡中所有操作都是在為這步運算做準備。
下面,讓我們一行一行地把代碼過一遍。
建議:用兩個屏幕來打開這篇博客,這樣你就能對照著代碼來閱讀文章。在博客撰寫時,我也正是這么做的。
第 1 行:這里導入一個名叫 numpy 的線性代數工具庫,它是本程序中唯一的外部依賴。
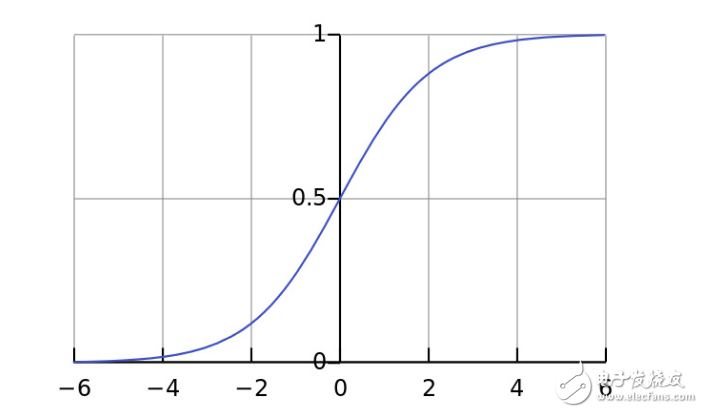
第 4 行:這里是我們的“非線性”部分。雖然它可以是許多種函數,但在這里,使用的非線性映射為一個稱作 “sigmoid” 的函數。Sigmoid 函數可以將任何值都映射到一個位于 0 到 1 范圍內的值。通過它,我們可以將實數轉化為概率值。對于神經網絡的訓練, Sigmoid 函數也有其它幾個非常不錯的特性。
?
第 5 行: 注意,通過 “nonlin” 函數體還能得到 sigmod 函數的導數(當形參 deriv 為 True 時)。Sigmoid 函數優異特性之一,在于只用它的輸出值便可以得到其導數值。若 Sigmoid 的輸出值用變量 out 表示,則其導數值可簡單通過式子 out *(1-out) 得到,這是非常高效的。
若你對求導還不太熟悉,那么你可以這樣理解:導數就是 sigmod 函數曲線在給定點上的斜率(如上圖所示,曲線上不同的點對應的斜率不同)。有關更多導數方面的知識,可以參考可汗學院的導數求解教程。
第 10 行:這行代碼將我們的輸入數據集初始化為 numpy 中的矩陣。每一行為一個“訓練實例”,每一列的對應著一個輸入節點。這樣,我們的神經網絡便有 3 個輸入節點,4 個訓練實例。
第 16 行:這行代碼對輸出數據集進行初始化。在本例中,為了節省空間,我以水平格式( 1 行 4 列)定義生成了數據集。“.T” 為轉置函數。經轉置后,該 y 矩陣便包含 4 行 1 列。同我們的輸入一致,每一行是一個訓練實例,而每一列(僅有一列)對應一個輸出節點。因此,我們的網絡含有 3 個輸入, 1 個輸出。
第 20 行:為你的隨機數設定產生種子是一個良好的習慣。這樣一來,你得到的權重初始化集仍是隨機分布的,但每次開始訓練時,得到的權重初始集分布都是完全一致的。這便于觀察你的策略變動是如何影響網絡訓練的。
第 23 行:這行代碼實現了該神經網絡權重矩陣的初始化操作。用 “syn0” 來代指 “零號突觸”(即“輸入層-第一層隱層”間權重矩陣)。由于我們的神經網絡只有 2 層(輸入層與輸出層),因此只需要一個權重矩陣來連接它們。權重矩陣維度為(3,1),是因為神經網絡有 3 個輸入和 1 個輸出。換種方式來講,也就是 l0 層大小為 3 , l1 層大小為 1 。因此,要想將 l0 層的每個神經元節點與 l1 層的每個神經元節點相連,就需要一個維度大小為(3,1)的連接矩陣。:)
同時,要注意到隨機初始化的權重矩陣均值為 0 。關于權重的初始化,里面可有不少學問。因為我們現在還只是練習,所以在權值初始化時設定均值為 0 就可以了。
另一個認識就是,所謂的“神經網絡”實際上就是這個權值矩陣。雖然有“層” l0 和 l1 ,但它們都是基于數據集的瞬時值,即層的輸入輸出狀態隨不同輸入數據而不同,這些狀態是不需要保存的。在學習訓練過程中,只需存儲 syn0 權值矩陣。
第 25 行:本行代碼開始就是神經網絡訓練的代碼了。本 for 循環迭代式地多次執行訓練代碼,使得我們的網絡能更好地擬合訓練集。
第 28 行:可知,網絡第一層 l0 就是我們的輸入數據,關于這點,下面作進一步闡述。還記得 X 包含 4 個訓練實例(行)吧?在該部分實現中,我們將同時對所有的實例進行處理,這種訓練方式稱作“整批”訓練。因此,雖然我們有 4 個不同的 l0 行,但你可以將其整體視為單個訓練實例,這樣做并沒有什么差別。(我們可以在不改動一行代碼的前提下,一次性裝入 1000 個甚至 10000 個實例)。
第 29 行:這是神經網絡的前向預測階段。基本上,首先讓網絡基于給定輸入“試著”去預測輸出。接著,我們將研究預測效果如何,以至于作出一些調整,使得在每次迭代過程中網絡能夠表現地更好一點。
(4 x 3) dot (3 x 1) = (4 x 1)
本行代碼包含兩個步驟。首先,將 l0 與 syn0 進行矩陣相乘。然后,將計算結果傳遞給 sigmoid 函數。具體考慮到各個矩陣的維度:
(4 x 3) dot (3 x 1) = (4 x 1)
矩陣相乘是有約束的,比如等式靠中間的兩個維度必須一致。而最終產生的矩陣,其行數為第一個矩陣的行數,列數則為第二個矩陣的列數。
由于裝入了 4 個訓練實例,因此最終得到了 4 個猜測結果,即一個(4 x 1)的矩陣。每一個輸出都對應,給定輸入下網絡對正確結果的一個猜測。也許這也能直觀地解釋:為什么我們可以“載入”任意數目的訓練實例。在這種情況下,矩陣乘法仍是奏效的。
第 32 行:這樣,對于每一輸入,可知 l1 都有對應的一個“猜測”結果。那么通過將真實的結果(y)與猜測結果(l1)作減,就可以對比得到網絡預測的效果怎么樣。l1_error 是一個有正數和負數組成的向量,它可以反映出網絡的誤差有多大。
第 36 行:現在,我們要碰到干貨了!這里就是秘密武器所在!本行代碼信息量比較大,所以將它拆成兩部分來分析。
第一部分:求導
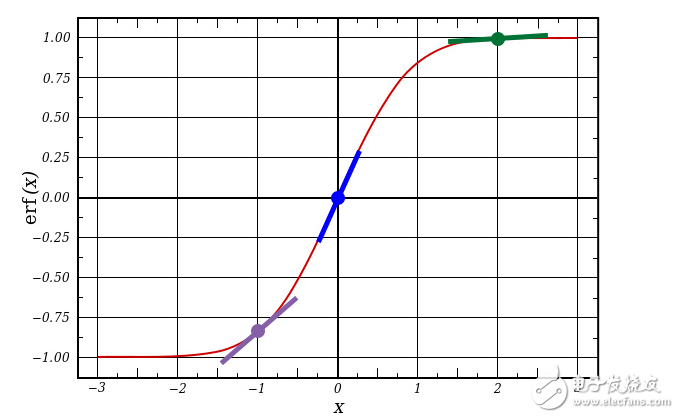
nonlin(l1,True)
如果 l1 可表示成 3 個點,如下圖所示,以上代碼就可產生圖中的三條斜線。注意到,如在 x=2.0 處(綠色點)輸出值很大時,及如在x=-1.0 處(紫色點)輸出值很小時,斜線都非常十分平緩。如你所見,斜度最高的點位于 x=0 處(藍色點)。這一特性非常重要。另外也可發現,所有的導數值都在 0 到 1 范圍之內。
?
整體認識:誤差項加權導數值
?
當然,“誤差項加權導數值”這個名詞在數學上還有更為嚴謹的描述,不過我覺得這個定義準確地捕捉到了算法的意圖。 l1_error 是一個(4,1)大小的矩陣,nonlin(l1,True)返回的便是一個(4,1)的矩陣。而我們所做的就是將其“逐元素地”相乘,得到的是一個(4,1)大小的矩陣 l1_delta ,它的每一個元素就是元素相乘的結果。
當我們將“斜率”乘上誤差時,實際上就在以高確信度減小預測誤差。回過頭來看下 sigmoid 函數曲線圖!當斜率非常平緩時(接近于 0),那么網絡輸出要么是一個很大的值,要么是一個很小的值。這就意味著網絡十分確定是否是這種情況,或是另一種情況。然而,如果網絡的判定結果對應(x = 0.5,y = 0.5)附近時,它便就不那么確定了。對于這種“似是而非”預測情形,我們對其做最大的調整,而對確定的情形則不多做處理,乘上一個接近于 0 的數,則對應的調整量便可忽略不計。
第 39 行:現在,更新網絡已準備就緒!下面一起來看下一個簡單的訓練示例。
?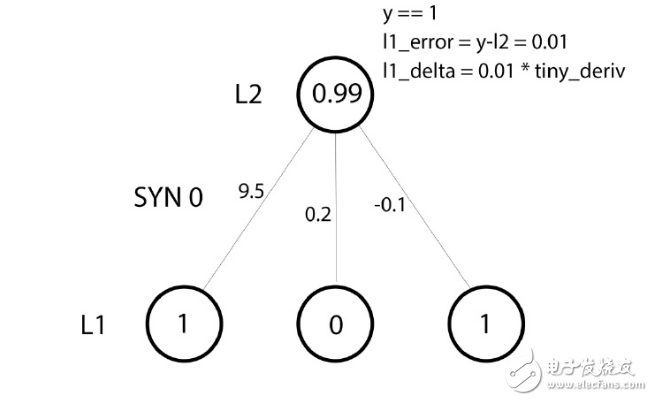
在這個訓練示例中,我們已經為權值更新做好了一切準備。下面讓我們來更新最左邊的權值(9.5)。
權值更新量 = 輸入值 * l1_delta
對于最左邊的權值,在上式中便是 1.0 乘上 l1_delta 的值。可以想得到,這對權值 9.5 的增量是可以忽略不計的。為什么只有這么小的更新量呢?是因為我們對于預測結果十分確信,而且預測結果有很大把握是正確的。誤差和斜率都偏小時,便意味著一個較小的更新量。考慮所有的連接權值,這三個權值的增量都是非常小的。
?
然而,由于采取的是“整批”訓練的機制,因此上述更新步驟是在全部的 4 個訓練實例上進行的,這看上去也有點類似于圖像。那么,第 39 行做了什么事情呢?在這簡單的一行代碼中,它共完成了下面幾個操作:首先計算每一個訓練實例中每一個權值對應的權值更新量,再將每個權值的所有更新量累加起來,接著更新這些權值。親自推導下這個矩陣相乘操作,你便能明白它是如何做到這一點的。
重點結論:
現在,我們已經知曉神經網絡是如何進行更新的。回過頭來看看訓練數據,作一些深入思考。 當輸入和輸出均為 1 時,我們增加它們間的連接權重;當輸入為 1 而輸出為 0 時,我們減小其連接權重
?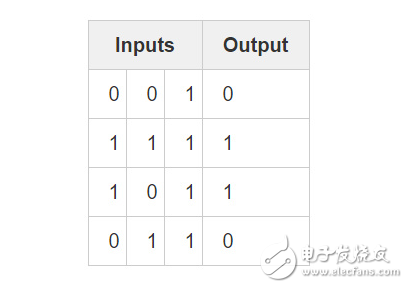
因此,在如下 4 個訓練示例中,第一個輸入結點與輸出節點間的權值將持續增大或者保持不變,而其他兩個權值在訓練過程中表現為同時增大或者減小(忽略中間過程)。這種現象便使得網絡能夠基于輸入與輸出間的聯系進行學習。
第二部分:一個稍顯復雜的問題
?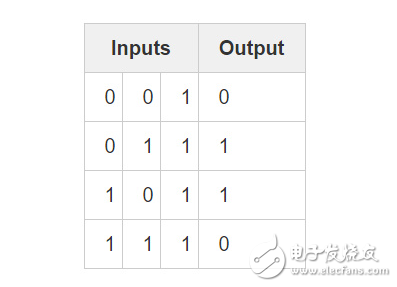
考慮如下情形:給定前兩列輸入,嘗試去預測輸出列。一個關鍵點在于這兩列與輸出不存在任何關聯,每一列都有 50% 的幾率預測結果為 1 ,也有 50% 的幾率預測為 0 。
那么現在的輸出模式會是怎樣呢?看起來似乎與第三列毫不相關,其值始終為 1 。而第 1 列和第 2 列可以有更為清晰的認識,當其中 1 列值為1(但不同時為 1 !)時,輸出便為 1 。這邊是我們要找的模式!
以上可以視為一種“非線性”模式,因為單個輸入與輸出間不存在一個一對一的關系。而輸入的組合與輸出間存在著一對一的關系,在這里也就是列 1 和列 2 的組合。
?
信不信由你,圖像識別也是一種類似的問題。若有 100 張尺寸相同的煙斗圖片和腳踏車圖片,那么,不存在單個像素點位置能夠直接說明某張圖片是腳踏車還是煙斗。單純從統計角度來看,這些像素可能也是隨機分布的。然而,某些像素的組合卻不是隨機的,也就是說,正是這種組合才形成了一輛腳踏車或者是一個人。
我們的策略
由上可知,像素組合后的產物與輸出存在著一對一的關系。為了先完成這種組合,我們需要額外增加一個網絡層。第一層對輸入進行組合,然后以第一層的輸出作為輸入,通過第二層的映射得到最終的輸出結果。在給出具體實現之前,我們來看下這張表格。
?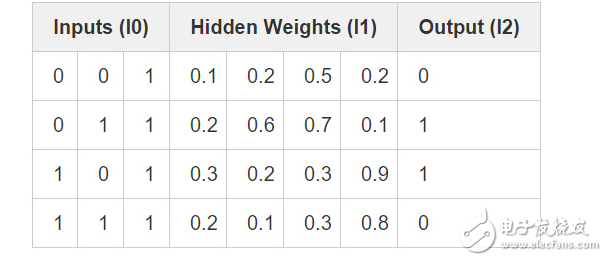
權重隨機初始化好后,我們便得到了層1的隱態值。注意到什么了嗎?第二列(第二個隱層結點)已經同輸出有一定的相關度了!雖不是十分完美,但也可圈可點。無論你是否相信,尋找這種相關性在神經網絡訓練中占了很大比重。(甚至可以認定,這也是訓練神經網絡的唯一途徑),隨后的訓練要做的便是將這種關聯進一步增大。syn1 權值矩陣將隱層的組合輸出映射到最終結果,而在更新 syn1 的同時,還需要更新 syn0 權值矩陣,以從輸入數據中更好地產生這些組合。
注釋:通過增加更多的中間層,以對更多關系的組合進行建模。這一策略正是廣為人們所熟知的“深度學習”,因為其正是通過不斷增加更深的網絡層來建模的。
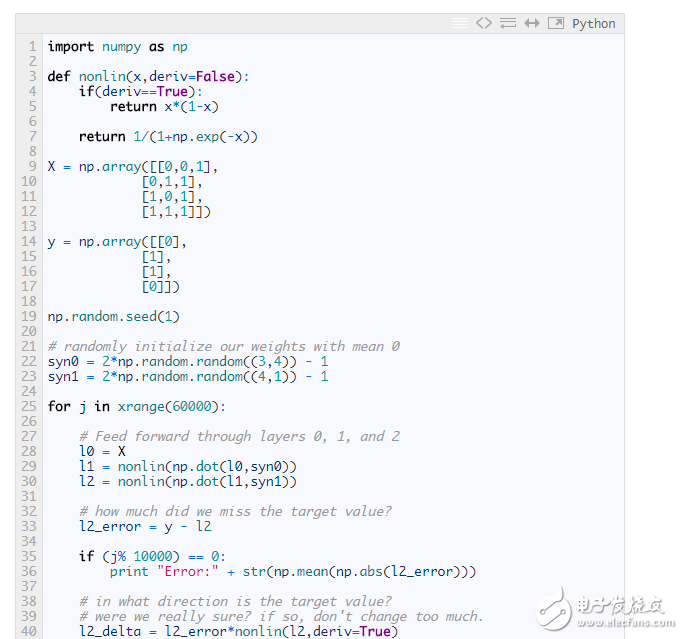
?
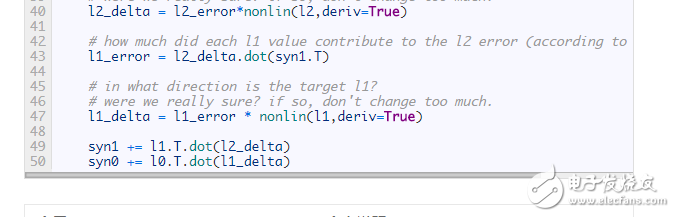
? ? ?

?
一切看起來都如此熟悉!這只是用這樣兩個先前的實現相互堆疊而成的,第一層(l1)的輸出就是第二層的輸入。唯一所出現的新事物便是第 43 行代碼。
第 43 行:通過對 l2 層的誤差進行“置信度加權”,構建 l1 層相應的誤差。為了做到這點,只要簡單的通過 l2 與 l1 間的連接權值來傳遞誤差。這種做法也可稱作“貢獻度加權誤差”,因為我們學習的是,l1 層每一個結點的輸出值對 l2 層節點誤差的貢獻程度有多大。接著,用之前 2 層神經網絡實現中的相同步驟,對 syn0 權值矩陣進行更新。
第三部分:總結?
如果你想認真弄懂神經網絡,給你一點建議:憑借記憶嘗試去重構這個網絡。我知道這聽起來有一些瘋狂,但確實會有幫助的。如果你想能基于新的學術文章創造任意結構的神經網絡,或者讀懂不同網絡結構的樣例程序,我覺得這項訓練會是一個殺手锏。即使當你在使用一些開源框架時,比如 Torch ,Caffe 或者 Theano ,這也會有所幫助的。







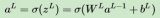









 工商網監
工商網監
評論