 電子發燒友App
電子發燒友App


引子
系統的學習機器學習課程讓我覺得受益匪淺,有些基礎問題的認識我覺得是非常有必要的,比如機器學習算法的類別。
為什么這么說呢?我承認,作為初學者,可能無法在初期對一個學習的對象有全面而清晰的理解和審視,但是,對一些關鍵概念有一個初步并且較為清晰的認識,有助于讓我們把握對問題的認識層次,說白了,就是幫助我們有目的的去學習新的知識,帶著問題去學習,充滿對解決問題的動力去實驗,我覺得這種方式是有益并且良性的。
之前,我遇到過很多這方面的問題,可能出于對問題分析不夠,在尋找解決的問題的方法或者模型的時候,有可能不知所措。造成這種情況的原因可能有兩點:1、基礎不深厚,不了解最常用的算法模型;2、學習過程中,缺乏對模型適用的實際問題的了解,缺乏將模型應用于實際問題的經驗。
所以,在學習過程中,要特別注意的不光是深入研究算法的精髓,還要知道該算法的應用場合、適用條件和局限性。如果只是去探究原理,而不懂實際應用,只能是書呆子,只會紙上談兵;如果只想拿來用,不去深究算法精髓,又只能游離在核心技術的邊界,無法真正的領悟。只有結合理論和實踐,才可以達到學習效果的最大化。從這條路徑出發,一定要堅持不懈。
輸入空間、特征空間和輸出空間
輸入空間和輸出空間其實就是輸入和輸出所有可能取值的集合。輸入和輸出空間可以是有限元素的集合,也可以是整個歐式空間。輸入空間和輸出空間可以是一個空間,也可以是不同的空間;通常情況下,輸出空間要遠遠小于輸入空間。
特征空間是所有特征向量存在的空間。特征空間的每一維對應于一個特征。有時假設輸入空間與特征空間為相同的空間,對它們不予區分;有時假設輸入空間與特征空間為不同的空間,將實例從輸入空間映射到特征空間。模型實際上都是定義在特征空間上的。
這就為機器學習算法的分類提供了很好的依據,可以根據輸入空間、特征空間和輸出空間的具體情況的不同,對算法限定的具體條件進行分類。
各種學習型算法的分類
首先聲明一下,下面的分類是我在學習相關課程和自己學習過程中進行的歸納,不盡完善,但是可以概括一定的問題,希望在此能總結一下,以備以后能理清思路并完善。
接下來介紹的算法的分類是根據初學者學習的內容的普遍角度展開的,分類角度從常用的分類方式到相對陌生的分類方式。
以輸出空間的不同作為分類依據
二類分類(binary classification),俗稱是非問題(say YES/NO)。其輸出空間Y={-1,+1}
多類別分類(multiclass classification),輸出空間Y={1,2,...,K}
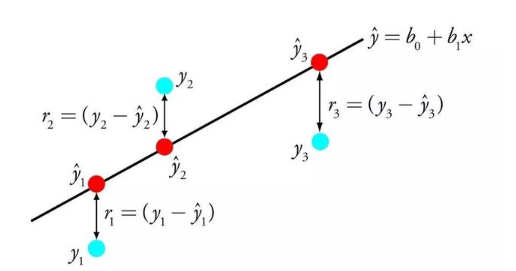
回歸問題(regression),輸出空間Y=R,即實數范圍,輸出是無限種可能
結構學習(structured learning),Y=structures,該學習模型也可以看做是多類別學習的一種,這里可能涉及到數量很大的類別
舉例:
二類分類應用非常廣泛,比如判斷是否為垃圾郵件、廣告投資是否能盈利、學習系統上在下一題答題是否正確。二類分類在機器學習中地位非常重要,是其他算法的基矗
多類別分類的應用,比如根據一張圖片,得出圖片中是蘋果、橘子還是草莓等;還有像Google郵箱,將郵件自動分成垃圾郵件、重要郵件、社交郵件、促銷郵件等。多類別分類在視覺或聽覺的辨識中應用很廣泛。
回歸分析在股票價格預測和天氣氣溫的預測上被廣泛應用。
結構學習(Structured Learning)
在自然語言處理中,自動的詞性標注是很典型的結構學習的例子。比如給定機器一個句子,由于詞語在不同的句子當中可能會有不同的詞性,所以該方法是用來對句子的結構特性的理解。這種學習方法可以被看做是多類別分類,但與多類別分類不同的是,其目標的結構種類可能規模很大,其類別是隱藏在句子的背后的。
這種結構學習的例子還有例如說,生物中蛋白質3D立體結構,自然語言處理方面。
結構學習在有些地方被描述成標注(tagging)問題,標注問題的輸入是一個觀測序列,輸出是一個標記序列或狀態序列。標注問題的目標在于學習一個模型,使它能夠對觀測序列給出標記序列作為預測。
以數據標簽的不同作為分類依據
按照這種分類方法,最常見的類別就是監督學習(supervised learning)、無監督學習(unsupervised learning)和半監督學習(semi-supervised learning)。在上面討論的以輸出空間的不同作為分類依據中,介紹的基本都是監督學習,下面我們來具體看看另外兩個。
無監督學習(unsupervised learning)
聚類(clustering),{x[n]} => cluster(x) , 這里數據的類別是不知道的,根據某種規則得到不同的分類。
它可以近似看做無監督的多類別分類。
密度估計(density estimation),{x[n]} => density(x) ,這里的density(x) 可以是一個概率密度函數或者概率函數。
它可以近似看做無監督的有界回歸問題。
異常檢測(outlier detection), {x[n]} => unusual(x) 。
它可以看做近似的無監督二類分類問題。
聚類的例子像是將網絡上各式各樣的文章分成不同的主題,商業公司根據不同的顧客的資料,將顧客分成不同的族群,進而采取不同的促銷策略。
密度估計的典型例子是根據位置的交通情況報告,預測事故危險多發的區域。
異常檢測的例子是,根據網絡的日志的情況,檢測是否有異常入侵行為,這是一個極端的“是非題”,可以用非監督的方法來得出。
半監督學習(Semi-supervised learning)
半監督學習(Semi-supervised Learning)是監督學習與無監督學習相結合的一種學習方法。它主要考慮如何利用少量的標注樣本和大量的未標注樣本進行訓練和分類的問題。半監督學習是利用未標記的大量數據提升機器學習算法的表現效果。
半監督學習的主要算法有五類:基于概率的算法;在現有監督算法基礎上作修改的方法;直接依賴于聚類假設的方法;基于多試圖的方法;基于圖的方法。
半監督學習的例子,比如Facebook上有關人臉照片的識別,可能只有一小部分人臉是被標記的,大部分是沒有被標記的。
增強學習(Reinforce learning)
強化學習是一種以環境反饋作為輸入的、特殊的、適應環境的機器學習方法。所謂強化學習是指從環境狀態到行為映射的學習,以使系統行為從環境中獲得的累積獎賞值最大。該方法不同與監督學習技術那樣通過正例、反例來告知采取何種行為,而是通過試錯(trial-and-error)的方法來發現最優行為策略。
這里的輸出并不一定是你真正想要得到的輸出,而是用過獎勵或者懲罰的方式來告訴這個系統做的好還是不好。
比如一個線上廣告系統,可以看做是顧客在訓練這個廣告系統。這個系統給顧客投放一個廣告,即可能的輸出,而顧客有沒有點或者有沒有因為這個廣告賺錢,這評定了這個廣告投放的好壞。這就讓該廣告系統學習到怎么樣去放更適合的廣告。
以與機器溝通方式的不同作為分類依據
批量學習(batch learning),一次性批量輸入給學習算法,可以被形象的稱為填鴨式學習。
線上學習(online learning),按照順序,循序的學習,不斷的去修正模型,進行優化。
hypothesis 'improves' through receiving data instances sequentially
前兩種學習算法分類可以被看做是被動的學習算法。
主動學習(active learning),可以被看做是機器有問問題的能力,指定輸入x[n],詢問其輸出y[n]
improve hypothesis with fewer labels (hopefully) by asking questions strategically
當label的獲取成本非常昂貴時,會利用此法
很多機器學習大都是批量學習的情況。
線上學習的例子有像是垃圾郵件過濾器中,郵件并不是一下子全部拿來訓練并且辨識的,而是呈序列形式,一封一封的到來,這樣子循序學習的方式不斷更新。
主動學習的一個簡單例子是,像QQ空間中,有好友照片的標注,即機器向人提問問題。
以輸入空間的不同作為分類依據
具體特征(concrete features),輸入X的每一維特征都被人類進行的整理和分析,這種分析常常是與專業領域關聯的
原始特征(raw features),需要人或者機器進行轉化,將原始特征轉化成為具體的特征,在機器視覺和聲音信號的辨識都是屬于該類
抽象特征(abstract features),
抽象特征的例子,比如在一個在線教學系統中學生的編號信息,還有廣告系統中廣告的編號ID。使用它們都需要更多特征抽取的動作。
原始特征的補充
這里要補充一下raw features中有關時興的深度學習(deep learning)的有關知識。
深度學習是通過機器自動的進行特征提取的。它需要有大量的資料或者非監督式學習的方式去學習如何從中抽取出非常具體的特征。
深度學習通過組合低層特征形成更加抽象的高層表示屬性類別或特征,以發現數據的分布式特征表示。
以上是我在初學階段針對學習型算法的類別簡述,可能有失準確的地方,還需要讀者自行分析判斷。最后,我還想對自己說一下,我在學習的過程中,不必追求將記錄的內容表述的盡可能的細致全面,而是要在記錄書寫文字的過程中真正能加深對問題的理解,不斷的進行自我思考。畢竟,我寫這些內容不是為了出書,而是要靈活的積累學習中的關鍵內容,進行更好的知識管理。當然,如果能幫助到讀者就更好了。




















 工商網監
工商網監
評論