K-means 算法是典型的基于距離的聚類算法,采用距離作為相似性的評價指標,兩個對象的距離越近,其相似度就越大。而簇是由距離靠近的對象組成的,因此算法目的是得到緊湊并且獨立的簇。
2022-07-18 09:19:13 1772
1772 
K-Means的主要優點是什么?K-Means的主要缺點是什么?
2021-06-10 06:14:37
什么是K-均值聚類法?K均值聚類算法的MATLAB怎么實現?
2021-06-10 10:01:25
什么是S參數測量?S參數插補算法是什么?介紹一種防止級聯的S參數出現相位假信號的具體算法
2021-04-30 07:00:01
k-近鄰算法簡述k-近鄰算法(kNN)采用測量不同特征值之間的距離方法進行分類。工作原理:首先存在一個樣本數據集合(訓練樣本集),并且樣本集中每個數據都存在標簽(監督學習)。所謂的標簽就是樣本集每
2018-10-10 10:32:43
k-近鄰算法簡述k-近鄰算法(kNN)采用測量不同特征值之間的距離方法進行分類。工作原理:首先存在一個樣本數據集合(訓練樣本集),并且樣本集中每個數據都存在標簽(監督學習)。所謂的標簽就是樣本集每
2022-01-04 14:03:43
目前新開發出的RLE_X3差分還原算法,已經能夠支持最小1K的內存空間,目前有MDK默認編譯器的ARM系列的庫,歡迎進群索取。介紹:...
2022-01-20 06:59:23
包含SVPWM的算法介紹,基本原理,以及詳細的公式推導,詳細的圖表示意,是初學FOC,準備自己手寫FOC庫或者理解FOC算法的工程師的有利手冊,手冊中也簡單介紹了SVPWM與SPWM的內在聯系與區別。讀者可自行推導公式后與手冊結果進行對照。
2023-10-07 09:13:05
山東大學機器學習(實驗六內容)—— K-Means
2019-08-28 09:25:58
關于ADPCM壓縮算法流程介紹
2021-06-03 06:44:13
介紹一種比較簡單的四線電阻觸摸屏校準算法,本算法已在實際工程中使用,效果不錯,大家放心使用!
2019-07-11 07:30:17
使用Weka進行K-近鄰算法和K-均值算法的使用
2019-05-24 12:02:15
聚類。這些集群圍繞著質心分組,使它們成為球形,并具有相似的大小。 對于初學者來說,這是我們推薦的一種算法,因為它很簡單,而且足夠靈活,可以為大多數問題獲得合理的結果。 優點:K-Means算法是最流行
2019-09-22 08:30:00
用單片機做了一個數據采集系統,采集的數據波動很大,想通過一些算法是數據平穩變化,一些簡單的算法,大家推薦一下,比如平均和濾波,謝謝
2013-12-15 22:26:35
幾個元素的節點,不考慮最好,不然容易導致過擬。3、能對非離散數據和不完整數據進行處理。該算法適用于臨床決策、生產制造、文檔分析、生物信息學、空間數據建模等領域。二、K平均算法K平均算法(k-means algorithm)是一個聚類算法,把n個分類對象根據它們的屬性分為k類(k
2018-11-06 17:02:30
過長,甚至可能達不到學習的目的。8、K-Means聚類關于K-Means聚類的文章,鏈接:機器學習算法-K-means聚類。關于K-Means的推導,里面有著很強大的EM思想。優點算法簡單,容易實現
2016-09-27 10:48:01
DIY圖像壓縮——機器學習實戰之K-means 聚類圖像壓縮:色彩量化
2019-08-19 07:07:18
無監督學習算法中,我們沒有目標或結果變量來預測。 通常用于不同群體的群體聚類。無監督學習的例子:Apriori 算法,K-means。0.3 強化學習 工作原理: 強化學習(reinforcement
2018-10-23 14:31:12
[源碼和文檔分享]JAVA實現基于k-means聚類算法實現微博輿情熱點分析系統
2020-06-04 08:21:55
【python】調用sklearn使用k-means模型
2020-06-12 13:33:22
針對聚類算法在金融領域廣泛應用的實際情況,基于銀行客戶數據集,對DBSCAN, K-means和X-means 3種聚類算法在執行效率、可擴展性、異常點檢測能力等方面進行對比分析,并提出將X-mea
2009-04-06 08:50:12 22
22 分析了常見的社團發現算法的特點,以及譜二分法在實際應用中必須不斷迭代才能完成多社團發現的不足,并提出了基于Laplace圖譜和K-Means聚類算法的多社團發現方法,該方法是一個
2009-04-20 09:49:2822 異常檢測是入侵檢測中防范新型攻擊的基本手段,本文應用增強的K-means 算法對檢測數據進行聚類分類。計算機仿真結果說明了該方法對入侵檢測是有
2009-09-03 10:21:3714 針對k-means算法存在的不足,提出了一種改進算法。 針對目前供電企業CRM系統的特點提出了用聚類分析方法進行客戶群細分模型設計,通過實驗驗證了本文提出的k-means改進算法的高效性
2010-03-01 15:28:5115 Web文檔聚類中k-means算法的改進
介紹了Web文檔聚類中普遍使用的、基于分割的k-means算法,分析了k-means算法所使用的向量空間模型和基于距離的相似性度量的局限性,從而
2009-09-19 09:17:03965 
介紹了K-means 聚類算法的目標函數、算法流程,并列舉了一個實例,指出了數據子集的數目K、初始聚類中心選取、相似性度量和距離矩陣為K-means聚類算法的3個基本參數。總結了K-means聚
2012-05-07 14:09:1427 2015-08-24 21:12:233 基于最小生成樹的層次K_means聚類算法_賈瑞玉
2017-01-03 15:24:455 基于改進K_means算法的海量數據分析技術研究_李歡
2017-01-07 18:39:170 基于聚類中心優化的k_means最佳聚類數確定方法_賈瑞玉
2017-01-07 18:56:130 混合細菌覓食和粒子群的k_means聚類算法_閆婷
2017-01-07 19:00:390 基于K_means和圖割的腦部MRI分割算法_田換
2017-01-08 11:13:291 K_means算法的改進及應用_王剛勇
2017-03-19 11:27:340 基于Canopy的K_means多核算法_邱榮太
2017-03-19 11:33:110 基于k_means的改進粒子群算法求解TSP問題_易云飛
2017-03-18 09:43:453 基于SVD的K_means聚類協同過濾算法_王偉
2017-03-17 08:00:000 基于改進K_means聚類的欠定盲分離算法_柴文標
2017-03-17 10:31:390 傳統kmeans算法由于初始聚類中心的選擇是隨機的,因此會使聚類結果不穩定。針對這個問題,提出一種基于離散量改進k-means初始聚類中心選擇的算法。算法首先將所有對象作為一個大類,然后不斷從對象
2017-11-20 10:03:232 挖掘其聚類關系,選取初始聚類中心,避免了傳統k-means算法對隨機選取初始聚類中心的敏感性,減少了k-means算法的迭代次數。又結合MapReduce框架將算法整體并行化,并通過Partition、Combine等機制加強了并行化程度和執行效率。實驗表明,該算法不僅提高了聚
2017-11-24 14:24:322 針對受均勻效應的影響,當前K-means型軟子空間算法不能有效聚類不平衡數據的問題,提出一種基于劃分的不平衡數據軟子空間聚類新算法。首先,提出一種雙加權方法,在賦予每個屬性一個特征權重的同時,賦予
2017-11-25 11:33:370 針對傳統的K-means算法無法預先明確聚類數目,對初始聚類中心選取敏感且易受離群孤點影響導致聚類結果穩定性和準確性欠佳的問題,提出一種改進的基于密度的K-means算法。該算法首先基于軌跡數據分布
2017-11-25 11:35:380 K-means算法是最簡單的一種聚類算法。算法的目的是使各個樣本與所在類均值的誤差平方和達到最小(這也是評價K-means算法最后聚類效果的評價標準)
2017-12-01 14:07:3319659 
人工魚群是一種隨機搜索優化算法,具有較快的收斂速度,對問題的機理模型與描述無嚴格要求,具有廣泛的應用范圍。本文在該算法的基礎上,結合傳統的K-means聚類方法,提出了一種新的人工魚群混合聚類算法
2017-12-04 16:18:150 傳統的k-means算法采用的是隨機數初始化聚類中心的方法,這種方法的主要優點是能夠快速的產生初始化的聚類中心,其主要缺點是初始化的聚類中心可能會同時出現在同一個類別中,導致迭代次數過多,甚至陷入
2017-12-05 18:32:540 穩定、收斂速度快等優點,提出了一種簡單有效的人臉識別方法,主要包含三個部分:卷積濾波器學習、非線性處理和空間平均值池化。具體而言,首先在訓練圖像中提取局部圖像塊,預處理后,使用K-means算法快速學習濾波器,每個濾波器與
2017-12-06 15:54:370 方法進行改進,將傳統譜聚類算法(NJW-SC)中的基于歐氏距離的相似性測度換為基于流行距離的相似性測度,在此基礎上對樣本對象集進行聚類。之后將新提出來的算法同K-Means算法、傳統譜聚類算法、模糊C均值聚類算法在人工數據集
2017-12-07 14:53:033 任務調度是云計算中的一個關鍵問題,遺傳算法是一種能較好解決優化問題的算法。本論文針對遺傳算法在任務調度過程中隨著任務調度問題復雜度增加,算法的性能出現下降的現象,引入K-means聚類算法,提出一種
2017-12-07 15:16:100 k-means算法自提出50多年來,在聚類分析中得到了廣泛應用,但是,k-means算法存在一個突出的問題,即需要預先設定聚類數目。所以,本文針對如何自動獲取k-means的聚類數目進行了研究
2017-12-13 10:49:440 針對原始K-means聚類算法受初始聚類中心影響過大以及容易陷入局部最優的不足,提出一種基于改進布谷鳥搜索(cs)的K-means聚類算法(ACS-K-means)。其中,自適應CS( ACS)算法
2017-12-13 17:24:063 在基于視角加權的多視角聚類中,每個視角的權重取值對聚類結果的精度都有著重要的影V向。針對此問題,提出熵加權多視角核K-means( EWKKM)算法,通過給每個視角分配一個合理的權值來降低噪聲視角
2017-12-17 09:57:111 針對大數據環境下K-means聚類算法聚類精度不足和收斂速度慢的問題,提出一種基于優化抽樣聚類的K-means算法(OSCK)。首先,該算法從海量數據中概率抽樣多個樣本;其次,基于最佳聚類中心的歐氏
2017-12-22 15:47:180 聚類中的主題詞。在新浪微博數據集上進行實驗發現,與k-means算法和基于加權語義和貝葉斯的中文短文本增量聚類算法(ICST-WSNB)相比,基于話題標簽和轉發關系的微博聚類算法的準確率比k-means算法提高了18.5%,比ICST-WSNB提高了6.48%,召回率以及F-值也有
2017-12-23 10:55:580 數據挖掘常用的十大算法包括: C4.5 ,K-means算法 3.SVM 4.Apriori ,EM:最大期望值法,pagerank:是google算法的重要內容,Adaboost: 迭代算法 ,KNN 最簡單的機器學習方法之一,Naive Bayes Cart:分類與回歸。下面我將一一介紹
2017-12-29 11:26:3026743 通過對基于K-means聚類的缺失值填充算法的改進,文中提出了基于距離最大化和缺失數據聚類的填充算法。首先,針對原填充算法需要提前輸入聚類個數這一缺點,設計了改進的K-means聚類算法:使用數據
2018-01-09 10:56:560 針對海量遙感影像快速分類的應用需求,提出一種基于K-means算法的遙感影像并行分類方法。該方法結合CPU下進程級與線程級模式的并行特征,設計融合進程級與線程級并行的兩階段數據粒度劃分方法和任務調度
2018-01-10 16:24:540 網絡中的脆弱節點進行補強。仿真實驗結果顯示這種結合K-means和脆弱性分析的拓撲生成算法在生成對意外風險具有較強抗性的電力網絡拓撲方面具有比較好的效果。
2018-02-02 17:05:550 對于K-Means算法,首先要注意的是k值的選擇,一般來說,我們會根據對數據的先驗經驗選擇一個合適的k值,如果沒有什么先驗知識,則可以通過交叉驗證選擇一個合適的k值。
2018-02-12 16:06:508105 
K-means算法的優點是:首先,算法能根據較少的已知聚類樣本的類別對樹進行剪枝確定部分樣本的分類;其次,為克服少量樣本聚類的不準確性,該算法本身具有優化迭代功能,在已經求得的聚類上再次進行迭代修正
2018-02-12 16:27:5931091 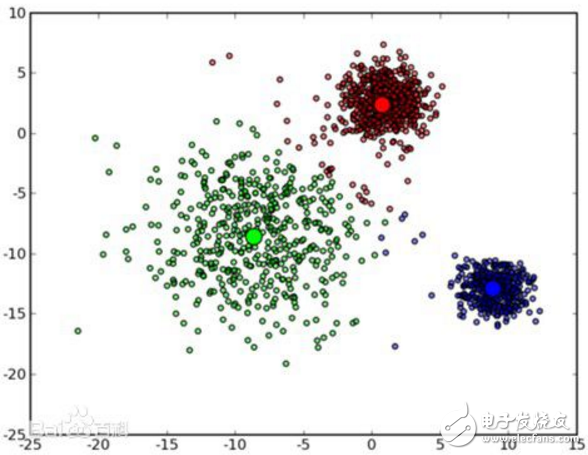
針對譜聚類存在計算瓶頸的問題,提出了一種快速的集成算法,稱為間接譜聚類。它首先運用K-Means算法對數據集進行過分聚類,然后把每個過分簇看成一個基本對象,最后在過分簇的級別上利用標準譜聚類來完成
2018-02-24 14:43:590 針對移動自組網( MANET,mobile ad hoc networks)入侵檢測過程中的攻擊類型多樣性和監測數據海量性問題,提出了一種基于改進k-means算法的MANET異常檢測方法。通過引入
2018-03-06 15:18:500 測試用例集約簡是軟件測試中的重要研究問題之一,目的是以盡量少的測試用例達到測試目標。為此,提出一種新的測試用例集約簡方法。應用二分K-means聚類算法對回歸測試的測試用例集進行約簡,以白盒測試
2018-03-12 15:06:230 這個函數是對矩陣mat填充隨機數,隨機數的產生方式有參數2來決定,如果為參數2的類型為RNG::UNIFORM,則表示產生均一分布的隨機數,如果為RNG::NORMAL則表示產生高斯分布的隨機數。對應的參數3和參數4為上面兩種隨機數產生模型的參數。
2018-04-08 09:49:295863 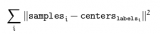
。將故事線看成日期、時間、機構、人物、地點、主題和關鍵詞的聯合概率分布,并考慮新聞時效性。在多個新聞數據集上進行的實驗和評估結果表明,與K-means、LSA等算法相比,該算法模型具有較高的故事線挖掘能力。
2018-04-24 14:51:3218 Content: 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means algorithm 9.3 Optimization
2018-05-01 17:43:0012211 
無監督學習是機器學習技術中的一類,用于發現數據中的模式。本文介紹用Python進行無監督學習的幾種聚類算法,包括K-Means聚類、分層聚類、t-SNE聚類、DBSCAN聚類等。
2018-05-27 09:59:1329728 
同時,k值的選取也會直接影響聚類結果,最優聚類的k值應與樣本數據本身的結構信息相吻合,而這種結構信息是很難去掌握,因此選取最優k值是非常困難的。
2018-07-24 17:44:2118878 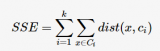
基于迭代框架的主動半監督聚類框架(IASSCF)是一個流行的半監督聚類框架。該框架存在兩個問題:其一,初始先驗信息較少導致迭代初期聚類效果不佳,進而影響后續聚類結果;其二,每次迭代只選擇信息量最大的一個樣本標記,導致運行速度慢性能提升慢。
2018-11-16 11:16:000 字段刪除和部分時段數據過濾三方面的預處理,其次進行地圖匹配,最后利用Spark大數據處理平臺,實現K-Means||算法,分為工作日和休息日的不同時段進行挖掘分析,得到成都市居民出行熱點區域及其時空分布特征,并將單機K-Means算法和K-Means
2018-11-23 16:12:1916 在我們日常生活中所用到的推薦系統、智能圖片美化應用和聊天機器人等應用中,各種各樣的機器學習和數據處理算法正盡職盡責地發揮著自己的功效。本文篩選并簡單介紹了一些最常見算法類別,還為每一個類別列出了一些實際的算法并簡單介紹了它們的優缺點。
2018-11-25 11:44:189851 
針對傳統K-means型算法的“均勻效應”問題,提出一種基于概率模型的聚類算法。首先,提出一個描述非均勻數據簇的高斯混合分布模型,該模型允許數據集中同時包含密度和大小存在差異的簇;其次,推導了非均勻
2018-12-13 10:57:5910 K-means算法是被廣泛使用的一種聚類算法,傳統的-means算法中初始聚類中心的選擇具有隨機性,易使算法陷入局部最優,聚類結果不穩定。針對此問題,引入多維網格空間的思想,首先將樣本集映射
2018-12-13 17:56:551 本文檔的主要內容詳細介紹的是機器學習教程之機器學習10大經典算法的詳細資料講解主要內容包括了:1、C4.5,2、The k-means algorithm3、SVM 4、Apriori算法5、最大
2018-12-14 15:03:5024 在手機、平板電腦等電子媒介的人均持有率大于一的今天,網絡自媒體的傳播達到了前所未有的巔峰。本文通過基于Hadoop平臺的mahout數據挖掘框架,選用經過Canopy算法優化后的K-means
2018-12-19 17:08:4913 聚類分析是將研究對象分為相對同質的群組的統計分析技術,聚類分析的核心就是發現有用的對象簇。K-means聚類算法由于具有出色的速度和良好的可擴展性,一直備受廣大學者的關注。然而,傳統的K-means
2018-12-20 10:28:2910 了和排序、查找、圖論、安全、聚類等相關的 26 個基礎算法,內容涉及冒泡排序、二分查找、廣度優先搜索、哈希函數、迪菲 - 赫爾曼密鑰交換、k-means 算法等。本書沒有枯燥的理論和復雜的公式,而是通過大量的步驟圖幫助讀者加深對數據結構原理和算法執行過程
2019-09-11 08:00:0074 了和排序、查找、圖論、安全、聚類等相關的 26 個基礎算法,內容涉及冒泡排序、二分查找、廣度優先搜索、哈希函數、迪菲 - 赫爾曼密鑰交換、k-means 算法等。本書沒有枯燥的理論和復雜的公式,而是通過大量的步驟圖幫助讀者加深對數據結構原理和算法執行過程
2020-05-08 08:00:004 粗糙K- Means及其衍生算法在處理邊界區域不確定信息時,其邊界區域中的數據對象因與各類簇中心點的距離相差較小,導致難以依據距離、密度對數據點進行區分判斷。提岀一種新的粗糙K- Means算法
2021-03-22 16:40:0013 K- means算法初始中心點選擇的隨機性以及對噪聲點的敏感性,使得聚類結果易陷亼局部最優解,為獲得最佳初始聚類中心,提岀一種基于距離和密度的并行二分K- means算法。計算數據集的平均樣本距離
2021-03-22 16:44:2217 和樸素貝葉斯等四個門類。 1. 聚類算法:k-means 聚類算法的目標:觀察輸入數據集,并借助數據集中不同樣本的特征差異來努力辨別不同的數據組。聚類算法最強大之處在于,它不需要本文中其他算法所需的訓練過程,您只需簡單地提供數據,告訴算法你想創造多少簇(樣本的組別)
2021-03-24 16:14:315987 現有聚類算法面向高維稀疏數據時多數未考慮類簇可重疊和離群點的存在,導致聚類效果不理想。為此,提出一種可重疊子空間K- Means聚類算法。設計類簇子空間計算策略,在聚類過程中動態更新每個類簇的屬性
2021-03-25 14:07:1013 聚類分析是數據挖掘與分析最重要的方法之一。它把相似的數據對象歸類到一個簇,把不同的數據對象盡可能分到不同的簇。其中k- means聚類算法,由于其簡單性和高效性,被廣泛運用于解決各種現實問題,例如
2021-04-28 16:43:551 為降低并均衡無線傳感器網絡(WSN)中傳感器節點的能量消耗,提出一種基于最優傳輸距離和 K-means聚類的WSN分簇算法。根據層次聚類算法建立聚類特征樹,將聚類特征樹中的葉節點視為一個簇,并使每個
2021-05-26 14:50:172 K-means 是一種聚類算法,且對于數據科學家而言,是簡單且熱門的無監督式機器學習(ML)算法之一。
2022-06-06 11:53:552981 在聚類技術領域中,K-means可能是最常見和經常使用的技術之一。K-means使用迭代細化方法,基于用戶定義的集群數量(由變量K表示)和數據集來產生其最終聚類。例如,如果將K設置為3,則數據集將分組為3個群集,如果將K設置為4,則將數據分組為4個群集,依此類推。
2022-10-28 14:25:21738 我們不用手工選擇 anchor boxes,而是在訓練集的邊界框上的維度上運行 K-means 聚類算法,自動找到良好的 anchor boxes 。 如果我們使用具有歐幾里得距離的標準 K-means,那么較大的框會比較小的框產生更多的誤差。
2023-01-11 15:40:361065 繼續講解! 程序來啦! 最后看一下程序示例!看看如何用K-means算法實現數據聚類的過程。程序很簡單,側重讓大家了解和掌握 K-means算法 聚類的過程! 看代碼吧!程序由三部
2023-02-11 07:20:04272 of Arrival)。不管是什么方式,其技術實現大致是一樣的:都是通過測量接收信號中的某些特征值,比如信號強度、角度、時間等,再采用相關算法來實現對目標的定位。下面分別介紹這三類算法:
2023-05-06 17:56:232352 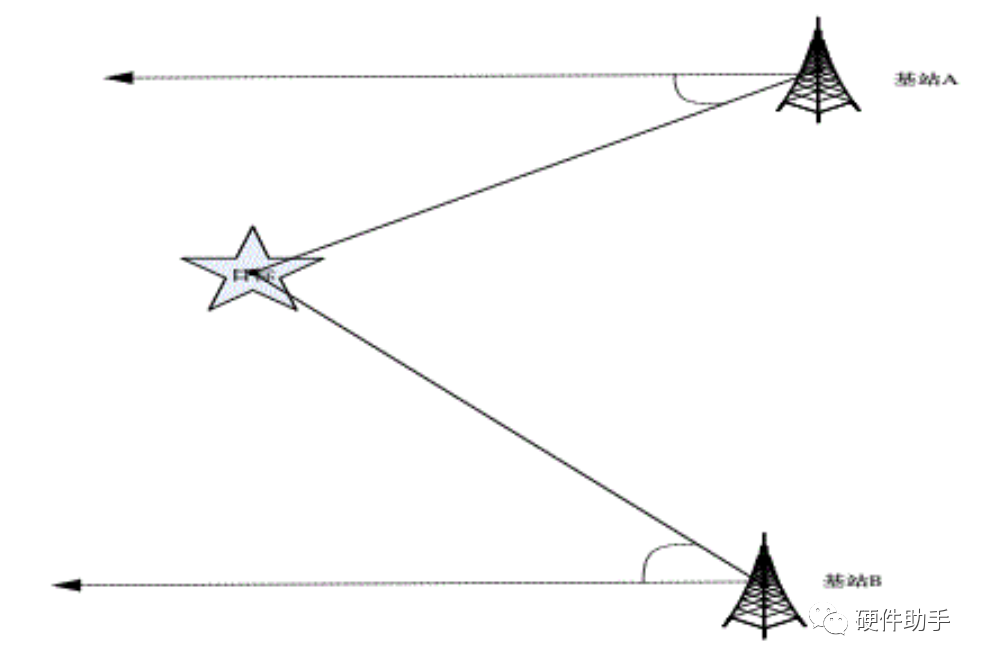
DBSCAN: Density Based Spatial Clustering of Applications with Noise; DBSCAN是基于密度的聚類方法,對樣本分布的適應能力比K-Means更好。
2023-05-09 14:35:56752 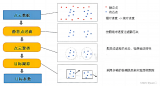
無監督學習算法主要用于聚類和關聯規則挖掘。聚類問題是指將數據集合劃分成相似的組,而關聯規則挖掘問題是指發現數據集合中經常一起出現的數據項。常見的無監督學習算法包括K-means、譜聚類、Apriori等。
2023-08-14 13:51:262264 圖像分割:利用圖像的灰度、顏色、紋理、形狀等特征,把圖像分成若干個互不重疊的區域,并使這些特征在同一區域內呈現相似性,在不同的區域之間存在明顯的差異性。然后就可以將分割的圖像中具有獨特性質的區域提取出來用于不同的研究。
2023-09-07 16:59:04458 
 電子發燒友App
電子發燒友App

















 工商網監
工商網監
評論