 電子發燒友App
電子發燒友App


機器之心編輯部
之前,OpenAI GPT-2 因為太能生成假新聞而不提供開源。而最近,華盛頓大學和艾倫人工智能研究所的研究者表示,要想對抗假新聞,用對應的假新聞生成器是最好的方法。研究者通過大量實驗表示,最了解假新聞缺點、假新聞“造假水平”的會是原本的生成器。因此想要判別 GPT-2 生成的假新聞,還是需要先開源 GPT-2 大模型。
自然語言生成領域近期的進展令人喜憂參半。文本摘要和翻譯等應用的影響是正面的,而其底層技術可以生成假新聞,且假新聞可以模仿真新聞的風格。
現代計算機安全依賴謹慎的威脅建模:從攻擊者的角度確定潛在威脅和缺陷,并探索可行的解決方案。同樣地,開發對假新聞的穩健防御技術也需要我們認真研究和確定這些模型的風險。
來自華盛頓大學和艾倫人工智能研究所的研究人員近期的一項研究展示了一個可控文本生成模型 Grover。給出標題“Link Found Between Vaccines and Autism”,Grover 可以生成文章內容,且 Grover 生成的內容比人類寫的假消息看起來更加可信。
圖 1:該研究介紹了一個能夠檢測和生成假新聞的模型 Grover。
開發對抗 Grover 等生成器的穩健驗證技術非常重要。該研究發現,當目前最好的判別器能夠獲取適量訓練數據時,其辨別假新聞和人類所寫真新聞的準確率為 73%。
而對 Grover 最好的防御就是 Grover 本身,它可以達到 92% 的準確率,這表明開源強大生成器的重要性。研究人員進一步研究了這些結果,發現數據偏差(exposure bias)和緩解其影響的采樣策略都會留下相似判別器能夠察覺的缺陷。最后,該研究還討論了這項技術的倫理問題,研究人員計劃開源 Grover,幫助更好地進行假新聞檢測。
Grover 生成文章示例

圖 8:上圖是同樣標題的兩篇文章,一篇是人類書寫的,另一篇則是 Grover 生成的,標題來自《衛報》。右下角為人類評分者給出的分數。

針對假新聞,該研究做了什么?
在本文中,研究人員力圖在假新聞大量出現前去理解并解決這一問題。他們認為這一問題屬于依賴計算機安全領域,依賴于威脅建模:分析系統的潛在威脅和缺陷,并探索穩健的防御措施。
為了嚴謹地研究這一問題,研究人員提出了新模型 Grover。Grover 能夠可控并高效地生成完整的新聞文章,不僅僅是新聞主體,也包括標題、新聞源、發布日期和作者名單,這有助于站在攻擊者的角度思考問題(如圖 1 所示)。
人類評分表明他們認為 Gover 生成的假消息是真實可信的,甚至比人工寫成的假消息更可信。因此,開發對抗 Grover 等生成器的穩健驗證技術非常重要。研究人員假設了一種情景:一個判別器可以獲得 Grover 生成的 5000 條假新聞和無限條真實新聞。
在這一假設下,目前最好的假新聞判別器(深度預訓練語言模型)可達到 73% 的準確率 (Peters et al., 2018; Radford et al., 2018; 2019; Devlin et al., 2018)。而使用 Grover 作為判別器時,準確率更高,可達到 92%。這一看似反直覺的發現說明,最好的假新聞生成器也是最好的假新聞判別器。
本文研究了深度預訓練語言模型怎樣分辨真實新聞和機器生成的文本。研究發現,由于數據偏差,在假新聞生成過程中引入了關鍵缺陷:即生成器是不完美的,所以根據其分布進行隨機采樣時,文本長度增加會導致生成結果落在分布外。然而,緩解這些影響的采樣策略也會引入強大判別器能夠察覺的缺陷。
該研究同時探討了倫理問題,以便讀者理解研究者在研究假新聞時的責任,以及開源此類模型的潛在不良影響 (Hecht et al., 2018)。由此,該研究提出一種臨時的策略,關于如何發布此類模型、為什么開源此類模型更加安全,以及為什么迫切需要這么做。研究人員認為其提出的框架和模型提供了一個堅實的初步方案,可用于應對不斷變化的 AI 假新聞問題。
具體方法
下圖 2 展示了利用 Grover 生成反疫苗文章的示例。指定域名、日期和標題,當 Grover 生成文章主體后,它還可以進一步生成假的作者和更合適的標題。

圖 2:如圖展示了三個 Grover 生成文章的例子。在 a 行中,模型基于片段生成文章主體,但作者欄空缺。在 b 行中,模型生成了作者。在 c 行中,模型使用新生成的內容重新生成了一個更真實的標題。
架構
研究者使用了最近較為流行的 Transformer 語言模型 (Vaswani et al., 2017),Grover 的構建基于和GPT-2相同的架構 (Radford et al., 2019)。研究人員考慮了三種模型大校
最小的 Grover-Base 使用了 12 個層,有 1.17 億參數,和 GPT 及 Bert-Base 相同。第二個模型是 Grover-Large,有 24 個層,3.45 億參數,和 Bert-Large 相同。最大的模型 Grover-Mega 有 48 個層和 15 億參數,與 GPT-2 相同。
數據集
研究者創建了 RealNews 大型新聞文章語料庫,文章來自 Common Crawl 網站。訓練 Grover 需要大量新聞文章作為元數據,但目前并沒有合適的語料庫,因此研究人員從 Common Crawl 中抓取信息,并限定在 5000 個 Google News 新聞類別中。
該研究使用名為“Newspaper”的 Python 包來提取每一篇文章的主體和元數據。研究者抓取 2016 年 12 月到 2019 年 3 月的 Common Crawl 新聞作為訓練集,2019 年 4 月的新聞則作為驗證集。去重后,RealNews 語料庫有 120G 的未壓縮數據。
訓練
對于每一個 Grover 模型,研究人員使用隨機采樣的方式從 RealNews 中抽取句子,并將句子長度限定在 1024 詞以內。其他超參數參見論文附錄 A。在訓練 Grover-Mega 時,共迭代了 80 萬輪,批大小為 512,使用了 256 個 TPU v3 核。訓練時間為兩周。
語言建模效果:數據、上下文(context)和模型大小對結果的影響
研究人員使用 2019 年 4 月的新聞作為測試集,對比了 Grover 和標準通用語言模型的效果。測試中使用的模型分別為:通用語言模型,即沒有提供上下文語境作為訓練,且模型必須生成文章主體。另一種則是有上下文語境的模型,即使用完整的元數據進行訓練。在這兩種情況下,使用困惑度(perplexity)作為指標,并只計算文章主體。
圖 3 展示了結果。首先,在提供元數據后,Grover 模型的性能有顯著提升(困惑度降低了 0.6 至 0.9)。其次,當模型大小增加時,其困惑度分數下降。在上下文語境下,Grover-Mega 獲得了 8.7 的困惑度。第三,數據分布依然重要:雖然有 1.17 億參數和 3.45 億參數的 GPT-2 模型分別可以對應 Grover-Base 和 Grover-Large,但在兩種情況下 Grover 模型相比 GPT-2 都降低了超過 5 分的困惑度。這可能是因為 GPT-2 的訓練集 WebText 語料庫含有非新聞類文章。

圖 3:使用 2019 年 4 月的新聞作為測試集,多個語言模型的性能。研究人員使用通用(Unconditional)語言模型(不使用元數據訓練)和有上下文語境(Conditional)的模型(提供所有元數據訓練)。在給定元數據的情況下,所有 Grover 模型都降低了超過 0.6 的困惑度分數。
使用 Nucleus Sampling 限制生成結果的方差
在 Grover 模型中采樣非常直觀,類似于一種從左到右的語言模型在解碼時的操作。然而,選擇解碼算法非常重要。最大似然策略,如束搜索(beam search),對于封閉式結尾的文本生成任務表現良好,其輸出和其語境所含意義相同(如機器翻譯)。
這些方法在開放式結尾的文本生成任務中則會生成質量不佳的文本 (Hashimoto et al., 2019; Holtzman et al., 2019)。然而,正如該研究在第六章展示的結果,限定生成文本的方差依然很重要。
該研究主要使用 Nucleus Sampling 方式(top-p):給出閾值 p,在每個時間步,從累積概率高于 p 的詞語中采樣 (Holtzman et al., 2019)。研究人員同時對比了 top-k 采樣方式,即在每一個時間步取具有最大概率的前 k 個 token (Fan et al., 2018)。
Grover 生成的宣傳文本輕易地騙過了人類
圖 4 中的結果顯示了一個驚人的趨勢:盡管 Grover 生成的新聞質量沒有達到人類的高度,但它擅長改寫宣傳文本。Grover 改寫后,宣傳文本的總體可信度從 2.19 增至 2.42。

圖 4:人工評估結果。對于 Grover 生成的文本,三個人類評分者從風格、內容和整體可信度方面進行評估;每種類別的文章取樣 100 篇。結果顯示,Grover 生成的宣傳文本比人類書寫的原始宣傳文本的可信度更高。
假新聞檢測
假新聞檢測中的半監督假設
雖然網上有大量人類書寫的文本,但大部分都時間久遠。因此對于文本的檢測應當設定在近一段時間。同樣,由攻擊方生成的 AI 假新聞數量可能十分少。因此,研究人員將假新聞檢測問題當做半監督問題。假新聞判別器可以使用從 2016 年 12 月到 2019 年 3 月的大量人工寫成的新聞,即整個 RealNews 訓練集。
但是,判別器被限制獲取近期新聞和 AI 生成的假新聞。研究者使用 2019 年 4 月的 10000 條新聞生成文章主體文本,使用另外 10000 條新聞作為人類寫成的新聞文章。研究人員將這些文章進行分割,其中 10000 條用于訓練(每個標簽 5000),2000 用作驗證集,8000 用作測試集。
研究人員考慮了兩種評價方式。第一種是不成對設置,即判別器僅獲得文章文本,并且需要獨立地判斷文章是人類寫的還是機器生成的。而在成對設置中,模型獲得兩份具備同樣元數據的文章,一份屬于人類完成,一份屬于機器生成。判別器必須給機器生成的文章分配高于人工完成文章的 Machine 概率。研究人員對兩種評價方法的準確率都進行了評估。
判別器評價結果:Grover 在檢測 Grover 生成的假新聞時表現最好
表 1 展示了所有生成器和判別器組合的實驗結果。對每個組合,研究人員展示了使用不同的采樣策略(top-p&top-k)超參數的評價結果(p ∈ {.9, .92, .94, .96, .98, 1.0},k ∈ )。
結果顯示了幾種趨勢:首先,成對生成器、判別器相比非成對設置總體上更加容易檢測假新聞,說明模型更難校準自己的預測。其次,模型大小對生成器和判別器之間的對抗過程非常關鍵。使用 Grover 判別器對 Grover 生成的文本進行檢測,總體上在所有 Grover 模型中都有大約 90% 的準確率。
如果使用一個更大的生成器,準確率會下滑至低于 81%,與此相對應的是,如果判別器更大,則(檢測假新聞)準確率上升至 98% 以上。最后,其他判別器總體上表現比 Grover 更差,這說明有效的判別器需要和生成器一樣的歸納偏置(inductive bias)。
無法獲得對應生成器又怎么樣?
上文中的結果說明,當在測試階段遇到一樣的攻擊方(生成器)時,在研究人員有一定數量的假新聞數據的情況下,Grover 是一個有效的假新聞判別器。但是如果放松這一假設呢?這里,研究人員考慮了攻擊方使用 Grover-Mega 生成器,且有一個未知的 top-p 采樣閾值。
在這一設定下,研究人員在訓練中可以獲得相對較弱的模型(Grover-Base 或 Grover-Large)。研究人員考慮了只有 x 個來自 Grover-Mega 的文本,并從較弱的生成器模型中采樣 5000-x 個文章,采樣閾值則對每一個文章都限定在 [0.9, 1.0] 之間。
研究人員在圖 5 中展示了實驗結果。結果說明,當只有少量 Grover-Mega 生成器文本時,從其他生成器獲得的弱監督文本可以極大提升判別器的表現。16 至 256 個 Grover-Mega 數據,加上從 Grover-Large 獲得的弱文本,可以使模型得到約 78% 的準確率,但沒有弱文本時僅有 50% 的準確率。當來自 Grover-Mega 的文本數據增加時,準確率可提升至 92%。
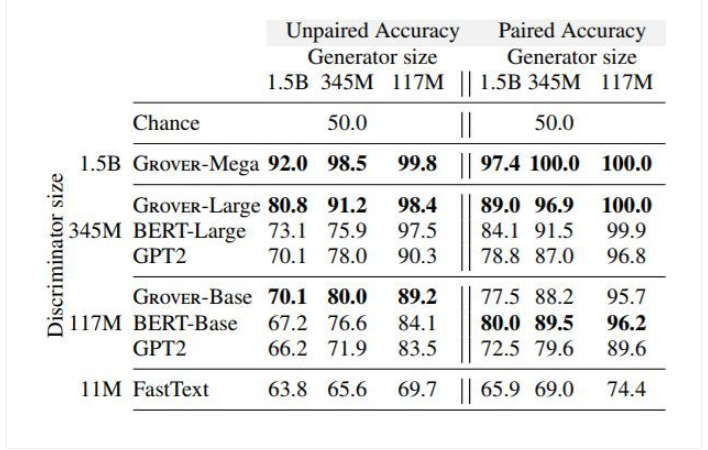
表 1:在成對和不成對設置以及不同大小架構中判別器和生成器的結果。研究人員還調整了每對生成器和判別器的生成超參數,并介紹了一組特殊的超參數,它具有最低驗證準確率的判別測試準確率。與其它模型(如 BERT)相比,Grover 最擅長識別自身生成的假新聞。
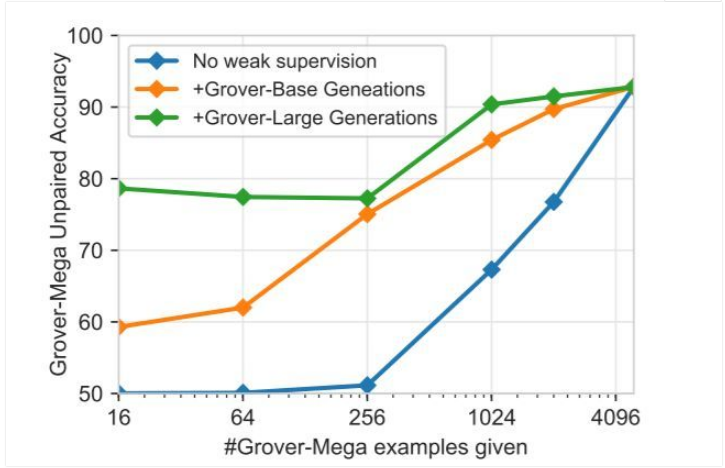
圖 5:探索判別 Grover-Mega 生成結果的弱監督。在沒有弱監督的情況下,判別器發現了 x 個機器生成的文本(來自 Grover Mega)。對于 Grover-Base 和 Grover-Mega,判別器發現了 5000-x 個機器生成的文本,這些文本由較弱的相關生成器給出。當給出的域內樣本較少時,生成的弱文本可以提升判別器的性能表現。
模型如何區分人工手寫和機器生成的文本?
等式 1:最近的最佳通用文本生成任務被認為是一個語言建模問題 (Bengio et al., 2003)。在這一問題中,需要尋找生成文本 x 的概率,此概率為該文本中每一個詞以前面所有詞為條件的概率之積。
為什么 Grover 在檢測自己生成的假新聞時效果最好?研究人員猜想部分原因可能是數據偏差,即訓練最大化等式 1 的模型僅能描述人工書寫的文本(Ranzato et al., 2016)。為了驗證他們的猜想,研究人員在圖 6 中繪制了 Grover-Mega 在文本每個位置的困惑度,取閾值 p=0.96 和 p=1 時的文本以及人工手寫的文本。
之后生成第一個 token 會導致較高的困惑度。但是,其余位置顯示出一種奇怪的模式:人工書寫的文本有著比隨機采樣文本更低的困惑度,而這個差距隨著序列長度的增加而加大,表明隨機采樣通常會導致 Grover 生成的結果越來越脫離人類語言的分布。然而,限制方差(p=0.96)會降低由此產生的困惑度并限制其增長。
1. 限制模型方差同樣產生了關鍵特征
但是在另一方面,限制模型的方差同樣留下了一種特征。如同以前的研究采用的 top-k 采樣一樣 (Strobelt and Gehrmann,2019),本次研究使用的原子采樣也出現了同樣的現象。一個人工寫成的文章中所有詞都高于 top-p% 閾值的概率是 p^n,n 是文本長度。當 n 增長時,概率下降。然而,對于原子采樣的文本,概率低于 1?-p 的文本被去除。因此文本中所有詞的出現概率都在 top-p 以上,根據這個特征就能進行判別。
2. 特征能否被捕捉取決于對判別器的選擇
對每一個時間步,從整體上來說,僅有生成器使用了 top-p 超參數。因此,如果一個判別器使用別的方式對文本進行建模,這個生成器需要更多的時間去定位被截斷的 1-p 分布長尾。這可能能夠解釋為什么 Bert 在作為判別器時表現較 Grover 更差。
3. 方差縮減時需要謹慎避開的“甜蜜陷阱”(sweet spot)
不縮減模型方差和強力縮減模型方差都會帶來問題。在縮減的參數中可能存在一個“甜蜜陷阱”(sweet spot)區域,去決定多大程度上需要截斷分布,使判別變得困難。在圖 7 中,研究人員展示了在不同采樣閾值下的 Grover-Mega 判別器的表現。結果確實顯示出了一個“甜蜜陷阱”。對于判別器,當 p 介于 0.92 和 0.98 之間時,判別工作是最困難的。
有趣的是,研究人員注意到攻擊方 top-p 閾值在 Bert-Large 模型遠低于這一閾值在 Grover-Large 中的值,即使兩個模型有著同樣的結構。這一結果支持了研究人員的猜測,即 Bert 對語言的建模方式和 Grover 非常不同。使用低 top-p 閾值似乎不能幫助模型獲得丟失的長尾信息。
?
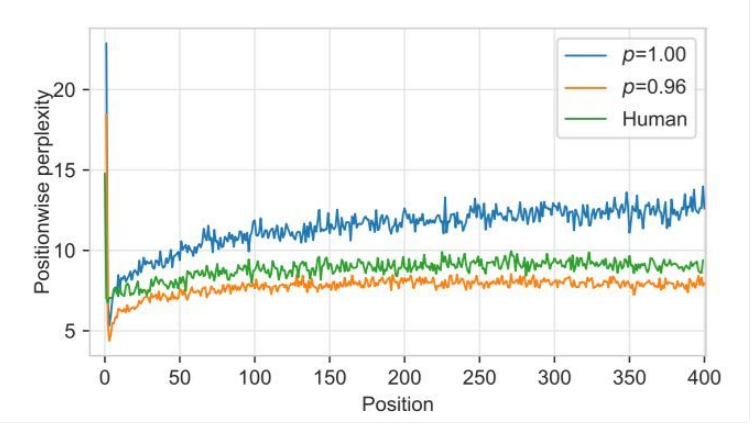
圖 6:Grover-Mega 的困惑度,取自每個位置的平均值(以元數據為條件)。研究人員選取了 p=1(隨機采樣)和 p=0.96 時 Grover-Mega 生成的文本以及人工書寫的文本。隨機采樣的文本有著比人工書寫的文本更高的困惑度,而且這個差距隨著序列長度的增加而加大。這表明,不減少方差的抽樣通常會導致生成結果落在真實分布以外。
?
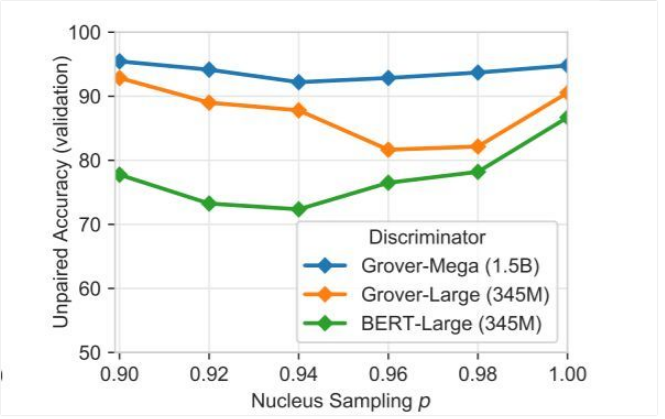
圖 7:在設定了不同的方差縮減閾值時(如 p 對應原子采樣和 k 對應 top-k 采樣方式),將 Grover Mega 生成的新文章與真實文章區分開的未配對的驗證準確率。因 p 的不同,結果也有所不同。當 p 在 0.92-0.96 之間時,區分假消息的難度最高。
總之,本文的分析表明,Grover 可能最擅長捕捉 Grover 生成的假新聞,因為它最了解假新聞的長尾分布在哪里,也因此知道 AI 假新聞的長尾分布是否被不自然地截斷。
開源策略
生成器的發布很關鍵。首先,似乎不開源像 Grover 這樣的模型對我們來說更安全。但是,Grover 能夠有效檢測神經網絡生成的假新聞,即使生成器比其大多了(如第 5 部分所示)。如果不開源生換器,那針對對抗攻擊的手段就很少了。
最后,研究人員計劃公開發布 Grover-Base 和 Grover-Large,感興趣的研究者也可以申請下載 Grover-Mega 和 RealNews。











 工商網監
工商網監
評論