 電子發(fā)燒友App
電子發(fā)燒友App


AI加速的尷尬現狀,不知你是否有感受?
獨占式方案,非虛擬化使用,成本高昂。缺少異構加速管理和調度,方案難度大,供應商還容易被鎖定。
對于AI開發(fā)者而言,虛擬化使用加速器計算資源,現有調度和管理軟件,并不親民。
所以現在,幾位虛擬化計算領域的專家,初步打造完成了一套解決方案并正式在GitHub推出,面向開發(fā)者,免費下載和使用。
這就是剛上線的OrionAI計算平臺。
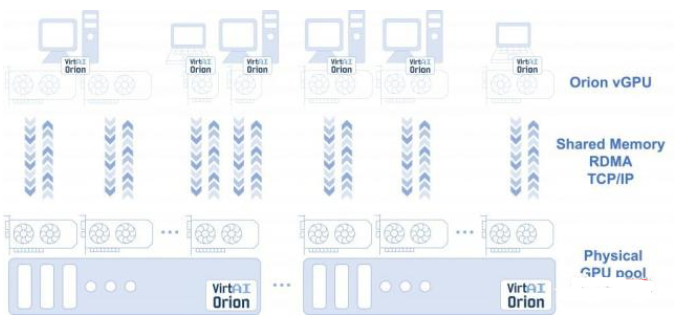
AI加速器虛擬化
整個OrionAI計算平臺,包括AI加速器虛擬化軟件,和異構加速器管理和調度軟件等兩大組件。
其中OrionAI加速器虛擬化軟件,不僅支持用戶使用和共享本地加速器資源,而且支持應用透明地使用遠程加速器資源——無需修改代碼。
從而打破資源調度的物理邊界,構建更高效資源池。
異構加速器管理和調度軟件,同樣支持用戶的應用無需修改代碼,即可透明地運行在多種不同加速器之上。
最終,幫助用戶更好利用多種不同加速器的優(yōu)勢,構建更高效的異構資源池。
剛上線的OrionAI計算平臺社區(qū)版v1.0,支持英偉達GPU的虛擬化,供AI、互聯(lián)網和公有云頭部客戶試用,開發(fā)者用戶可免費下載和使用。
AI加速痛點
OrionAI計算平臺因何出發(fā)?
方案打造者稱,隨著AI技術的快速發(fā)展和普及,越來越多客戶開始使用高性能的AI加速器,包括GPU, FPGA和AI ASIC芯片等。
同時,越來越多的客戶需要高效的AI加速器虛擬化軟件,來提高加速器資源的利用率,以及高效的異構加速器管理和調度軟件,來更好地利用多種不同的加速器,提高性能,降低成本,避免供應商鎖定。
但相應地面臨開頭提及的兩大痛點。
首先,AI加速器價格偏高。
以知名的英偉達V100 GPU為例,價格在8萬元人民幣左右,高性能FPGA卡,價位也在5萬元人民幣。
其次,由于缺乏高效經濟的AI加速器虛擬化解決方案,目前絕大部分企業(yè),不得不獨占式使用上述昂貴的加速器資源,導致資源利用率低,成本高。
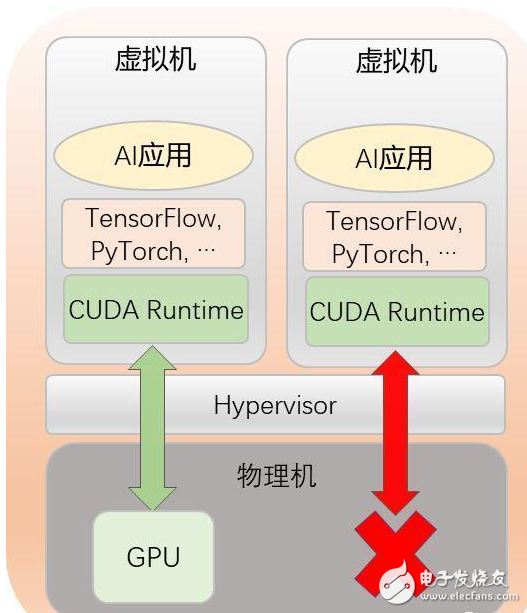
根據AWS在re:Invent 2018披露數據,AWS上GPU利用率只有10%~30%。
當物理機上只有一塊GPU時,如果沒有GPU虛擬化解決方案,用戶就只能讓一個虛擬機獨占式地使用該GPU,導致該GPU無法被多個虛擬機共享。
于是幾位加速虛擬化領域的老兵,決定試水,并最終推出了自己的方案:OrionAI計算平臺v1.0。
方案詳解
該平臺支持用戶通過多個虛擬機或者容器,來共享本地以及遠程GPU資源。
使用OrionAI平臺的典型場景有:
第一,多個虛擬機或容器共享本地的GPU。
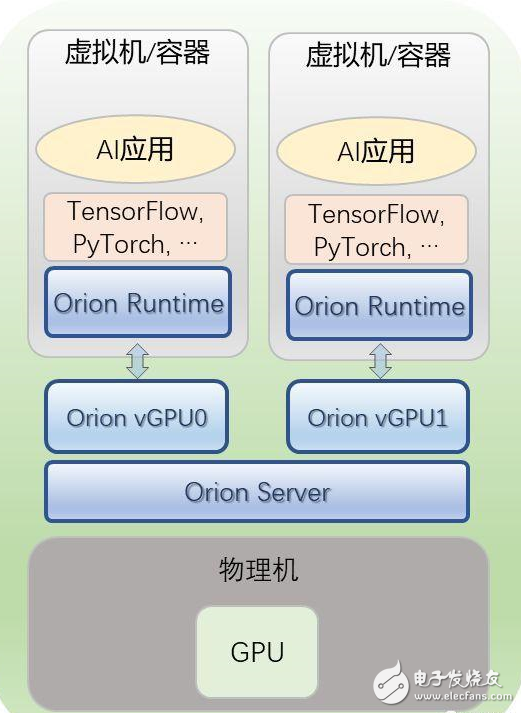
用戶只需要將虛擬機或者容器中的CUDA運行環(huán)境(CUDA runtime),替換成Orion運行環(huán)境(Orion Runtime)即可。
而用戶的AI應用和所使用的深度學習框架(TensorFlow,、PyTorch等)不需要任何改變,即可像在原生的CUDA運行環(huán)境下一樣運行。
同時,用戶需要在物理服務器上運行Orion服務(Orion Server),該服務會接管物理GPU,并且將物理GPU虛擬化成多個Orion vGPU。
用戶在不同虛擬機上運行的AI應用會被分配到不同的Orion vGPU上。這樣物理GPU的利用率就會得到顯著提升。
第二,多個虛擬機或容器共享遠程的GPU。
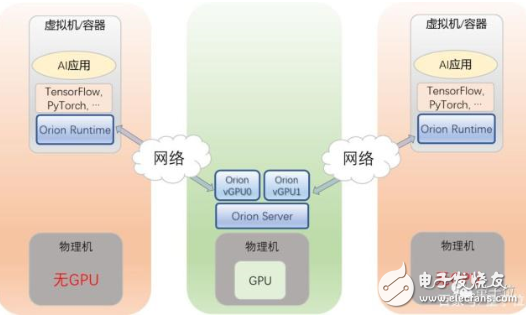
用戶可以將虛擬機/容器,運行在沒有GPU的服務器上,AI應用無需修改,就可以通過Orion Runtime來使用另外一臺服務器上的Orion vGPU。
如此一來,用戶的AI應用就可以被部署在數據中心中的任何一臺服務器之上,用戶的資源調配和管理,得到極大靈活性提升。
第三,單個虛擬機或容器,使用跨越多臺物理服務器上的GPU。
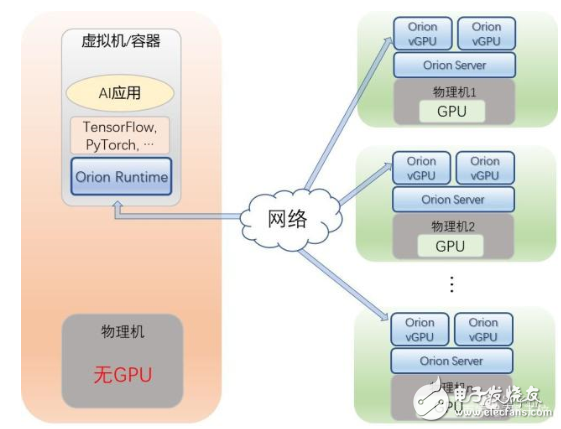
用戶的虛擬機/容器通過Orion Runtime,無需修改AI應用和框架,就可以使用跨越多臺物理機上的GPU資源。
目前現狀是,AI應用可能需要64個GPU——甚至更多GPU來訓練模型,但是今天還沒有一臺物理服務器能夠完全滿足。
通過Orion Runtime,應用無需修改就可以直接使用多臺物理服務器上的GPU,如16臺服務器,每臺4塊GPU。
如此一來,用戶GPU資源,就能變成一個真正的數據中心級的資源池。
用戶的AI應用可以透明地使用任何一臺服務器上的GPU資源,資源利用率和管理調度靈活度,可以得到極大提升。
用戶通過Orion AI Platform分配的GPU資源,無論是本地GPU資源,還是遠程GPU資源,均軟件定義、按需分配。
這些資源不同于通過硬件虛擬化技術得到的資源,它們的分配和釋放都能在瞬間完成,不需要重啟虛擬機或者容器。
例如,當用戶啟動了一個虛擬機時,如果用戶不需要運行AI應用,那么Orion AI Platform不會給這個虛擬機分配GPU資源。
當用戶需要運行一個大型訓練任務,例如需要16個Orion vGPU,那么Orion AI Platform會瞬間給該虛擬機分配16個Orion vGPU。
當用戶完成訓練后,又只需要1個Orion vGPU來做推理,那么Orion AI Platform又能瞬間釋放15個Orion vGPU。
值得一提的是,所有上述的資源分配和釋放都不需要虛擬機重啟。
技術細節(jié)和benchmark
上述方案背后,究竟是怎樣的技術細節(jié)?
實際上,Orion Runtime提供了和CUDA Runtime完全兼容的API接口,保證用戶的應用無需修改即能運行。
Orion Runtime在得到用戶所有對CUDA Runtime的調用之后,將這些調用發(fā)送給Orion Server。
Orion Server會將這些調用加載到物理GPU上去運行,然后再將結果返回給Orion Runtime。
OrionAI計算平臺v1.0也公布了性能對比結果。
先看配置:
GPU服務器配置:雙路Intel Xeon Gold 6132,128GB內存,單塊nVidia Tesla P40。
性能測試集:TensorFlow v1.12, 官方benchmark,無代碼修改,測試使用synthetic數據。
“Native GPU”為將性能測試運行在物理GPU之上,不使用虛擬機或者容器;
“Orion Local Container”為將性能測試運行在安裝了Orion Runtime的容器之中,Orion Server運行在同一臺物理機之上;
“Orion Local KVM”為將性能測試運行在安裝了Orion Runtime的KVM虛擬機之中,Orion Server運行在同一臺物理機之上;
“Orion Remote – 25G RDMA”為性能測試運行在一臺沒有GPU的物理機之上,Orion Server運行在有GPU的物理機之上,兩臺物理機通過25G RDMA網卡連接。
最終對比結果如下:
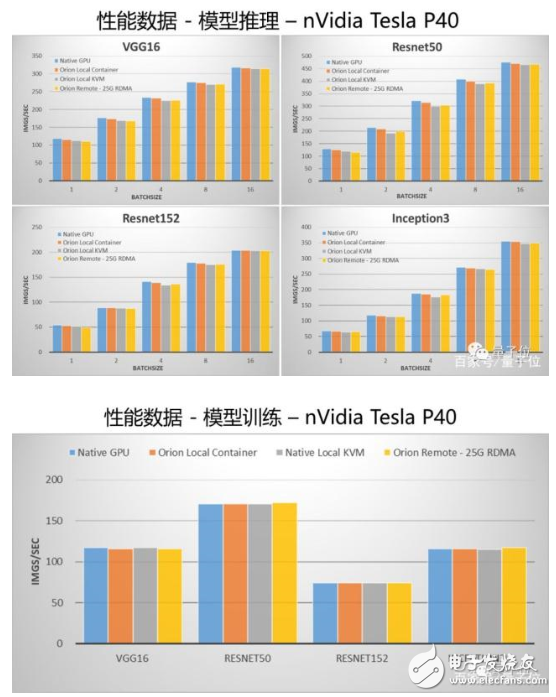
通過數據可以看出,和跑在物理GPU上相比,Orion Runtime和Orion Server引入的性能損失非常小。
尤其是在通過網絡連接來使用遠程的GPU的情況下,OrionAI計算平臺通過大量的優(yōu)化,使其性能與使用本機GPU相比差距非常小。
OrionAI計算平臺打造方
最后,介紹下OrionAI計算平臺背后的打造方:
趨動科技 VirtAI Tech。
2019年1月剛創(chuàng)立,主打AI加速器虛擬化軟件,以及異構AI加速器管理和調度軟件。
主要創(chuàng)始人有三位,皆為該領域的資深老兵。
王鯤,趨動科技CEO。博士畢業(yè)于中國科學技術大學計算機系。
在創(chuàng)辦趨動科技之前,王鯤博士供職于Dell EMC中國研究院,任研究院院長,負責管理和領導Dell EMC在大中華區(qū)的所有研究團隊。
他長期從事計算機體系結構,GPU和FPGA虛擬化,分布式系統(tǒng)等領域的研究工作,在業(yè)界最早開始推動FPGA虛擬化相關研究,在該領域擁有十多年的工作經驗和積累。
陳飛,趨動科技CTO。博士畢業(yè)于中國科學院計算技術研究所。
在創(chuàng)立趨動科技之前,陳飛博士供職于Dell EMC,擔任Dell EMC中國研究院首席科學家,長期從事高性能計算,計算機體系結構,GPU和FPGA虛擬化等領域的研究工作。
鄒懋,趨動科技首席架構師。博士畢業(yè)于中國科學技術大學。
在創(chuàng)立趨動科技之前,鄒懋博士供職于Dell EMC,擔任Dell EMC中國研究院高級研究員,長期從事計算機體系結構,GPU虛擬化等領域的研究工作。















 工商網監(jiān)
工商網監(jiān)
評論