 電子發燒友App
電子發燒友App











 創作
創作 發文章
發文章 發帖
發帖  提問
提問  發資料
發資料 發視頻
發視頻資料介紹
描述
介紹
介紹
歡迎回到我們正在進行的微型機器學習 (TinyML) 系列!在我們之前的兩個教程中已經深入研究了圖像分類、運動分類和異常檢測,現在我們將重點轉移到聲控應用領域,并通過一個使用 XIAO ESP32S3 板的關鍵字識別 (KWS) 項目。
關鍵字識別 (KWS) 是許多語音識別系統不可或缺的一部分,使設備能夠響應特定的單詞或短語。雖然這項技術是 Google Assistant 或 Amazon Alexa 等流行設備的基礎,但它同樣適用于更小的低功耗設備。本教程將指導您在 XIAO ESP32S3 微控制器板上使用 TinyML 實現 KWS 系統。
據了解,配備樂鑫 ESP32-S3 芯片的 XIAO ESP32S3 是一款緊湊而強大的微控制器,提供雙核 Xtensa LX7 處理器、集成 Wi-Fi 和藍牙功能。它在計算能力、能源效率和通用連接性之間取得平衡,使其成為 TinyML 應用程序的絕佳平臺。此外,通過其擴展板,我們可以訪問設備的“感知”部分,該部分具有一個 1600x1200 OV2640 攝像頭、一個 SD 卡插槽和一個數字麥克風。集成麥克風和 SD 卡在該項目中必不可少。
與之前的系列教程一樣,我們將利用Edge Impulse Studio ,這是一個功能強大、用戶友好的平臺,可簡化在邊緣設備上創建和部署機器學習模型的過程。我們將逐步訓練 KWS 模型,對其進行優化并將其部署到 XIAO ESP32S3 Sense 上。
我們的模型旨在識別可觸發設備喚醒或特定操作(在“是”的情況下)的關鍵字,通過語音激活命令使您的項目栩栩如生。
利用我們在之前教程中使用 TensorFlow Lite for Microcontrollers(EI Studio 中的引擎)的經驗,我們將創建一個能夠在設備上進行實時機器學習的 KWS 系統。
隨著教程的推進,我們將分解每個過程階段——從數據收集和準備到模型訓練和部署——以提供對在微控制器上實現 KWS 系統的全面理解。
因此,讓我們使用 Edge Impulse Studio 在 XIAO ESP32S3 上進行關鍵字識別,繼續我們的 TinyML 精彩世界之旅!
語音助手如何工作?
介紹解釋說,關鍵字識別 (KWS) 對許多語音助手至關重要,它使設備能夠響應特定的單詞或短語。
首先,必須認識到市場上的語音助手,如 Google Home 或 Amazon Echo-Dot,只有在人類被特定關鍵字“喚醒”時才會對人類做出反應,例如第一個關鍵字上的“Hey Google”和“ Alexa”在第二個。
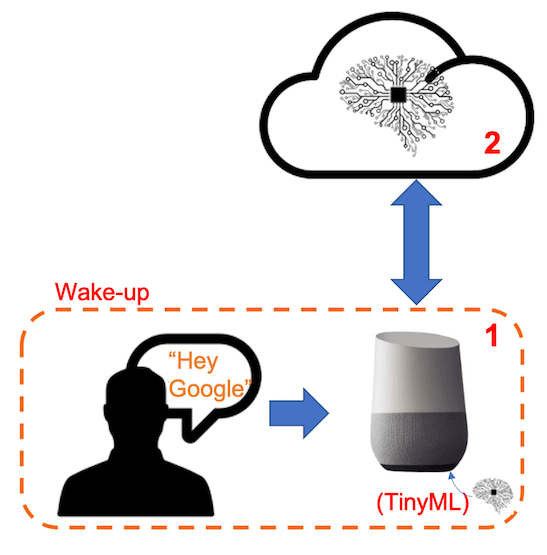
換句話說,識別語音命令是基于多階段模型或級聯檢測。
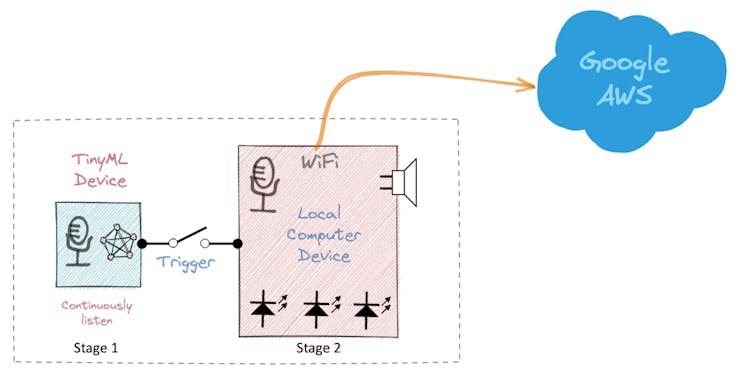
第 1 階段:Echo Dot 或 Google Home 內的一個較小的微處理器持續收聽聲音,等待關鍵詞被識別。
如果您想更深入地了解整個項目,請參閱我的教程:從頭開始構建智能語音助手。
在這個項目中,我們將專注于第 1 階段(KWS 或關鍵字識別),我們將在其中使用 XIAO ESP2S3 Sense,它具有一個用于識別關鍵字的數字麥克風。
KWS 項目
下圖將給出最終 KWS 應用程序應該如何工作的想法(在推理期間):
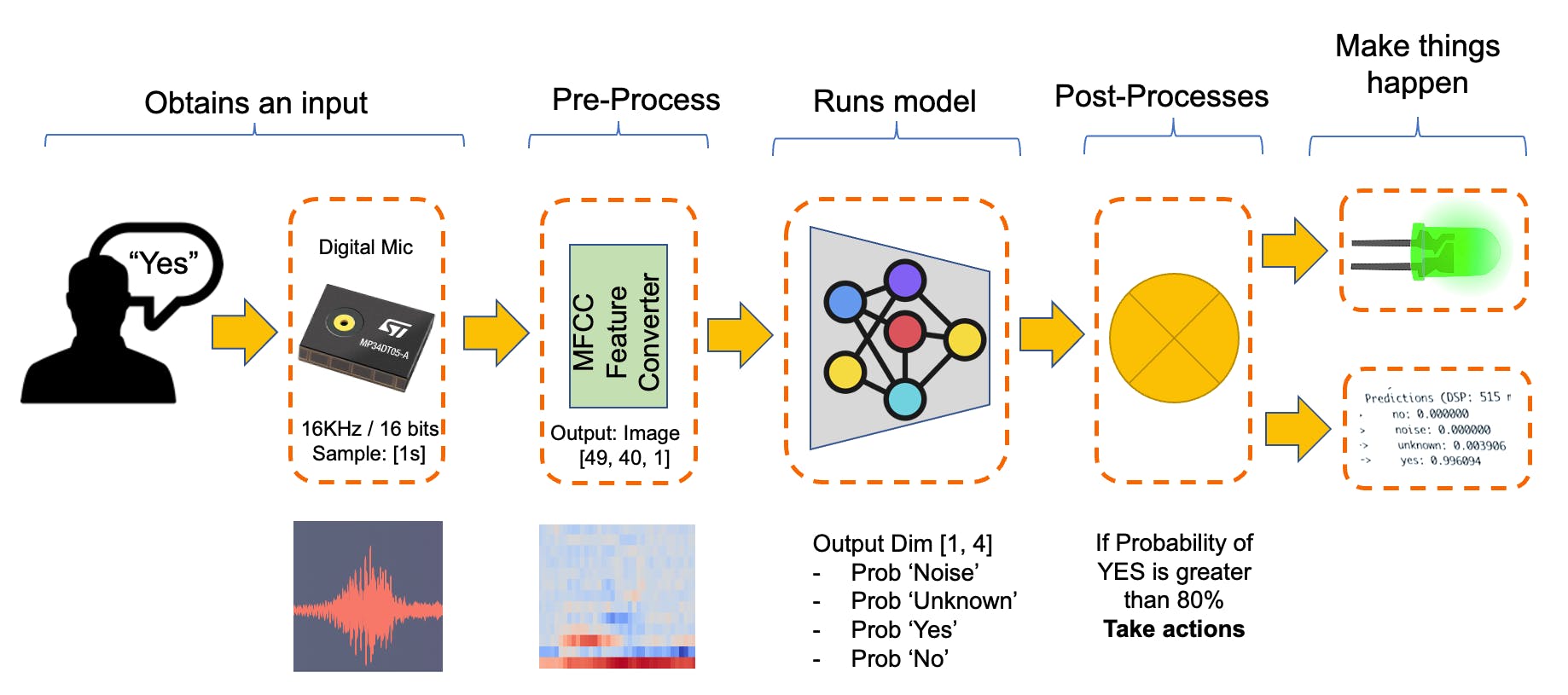
我們的 KWS 應用程序將識別四種聲音:
- 是(關鍵字 1)
- 否(關鍵字 2)
- NOISE (沒有說出關鍵詞,只有背景噪音)
- UNKNOW (不同于 YES 和 NO 的混合詞)
對于真實世界的項目,始終建議包含與關鍵字不同的詞,例如“噪音”(或背景)和“未知”。
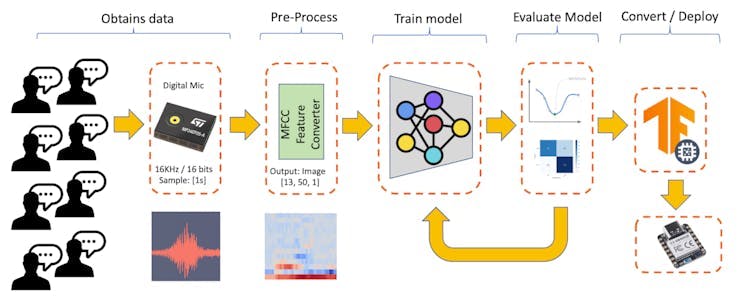
機器學習工作流程
KWS 應用程序的主要組件是它的模型。因此,我們必須使用特定的關鍵字、噪聲和其他詞(“未知”)來訓練這樣的模型:
數據集
機器學習工作流的關鍵組成部分是數據集。一旦我們決定了特定的關鍵字(YES和 NO),我們就可以利用 Pete Warden 開發的數據集“語音命令:有限詞匯語音識別數據集” 。這個數據集有 35 個關鍵字(每個關鍵字 +1, 000 個樣本),例如 yes、no、stop 和 go。在其中一些詞中,我們可以獲得 1, 500 個樣本,例如yes和no 。
您可以從 Edge Studio 下載一小部分數據集(關鍵字識別預建數據集),其中包括我們將在該項目中使用的四個類別的樣本:是、否、噪聲和背景。為此,請按照以下步驟操作:
- 下載關鍵字數據集。
- 將文件解壓縮到您選擇的位置。
雖然我們有很多來自 Pete 的數據集的數據,但建議收集一些我們所說的單詞。在使用加速度計時,使用相同類型的傳感器捕獲的數據創建數據集是必不可少的。在聲音的情況下,情況有所不同,因為我們要分類的實際上是音頻數據。
聲音和音頻之間的主要區別在于它們的能量形式。聲音是通過介質傳播的機械波能量(縱向聲波),導致介質內的壓力發生變化。音頻由代表聲音的電能(模擬或數字信號)組成。
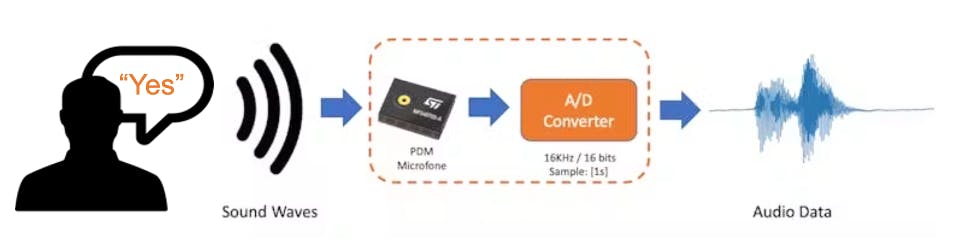
當我們說出關鍵詞時,聲波應該被轉換成音頻數據。轉換應該通過對麥克風生成的信號進行采樣來完成,頻率為 16KHz,深度為 16 位。
因此,任何可以生成具有此基本規格(16Khz/16 位)的音頻數據的設備都可以正常工作。作為設備,我們可以使用合適的XIAO ESP32S3 Sense,也可以是電腦,甚至手機。
使用 Edge Impulse 和智能手機捕獲在線音頻數據
在教程“使用新的 XIAO ESP32S3 探索機器學習”中,我們將設備直接連接到 Edge Impulse Studio 進行數據捕獲(采樣頻率為 50Hz 至 100Hz)。對于如此低的頻率,我們可以使用 EI CLI 功能數據轉發器,但根據 Edge Impulse 首席技術官 Jan Jongboom 的說法,音頻(在本例中為 16KHz)速度太快,數據轉發器無法捕獲。因此,一旦我們獲得了麥克風捕獲的數字數據,我們就可以將其轉換為 WAV 文件,通過數據上傳器發送到工作室(與我們對皮特的數據集所做的相同)。
如果我們想直接在 Studio 上收集音頻數據,我們可以使用任何與其在線連接的智能手機。我們不會在這里探討這個選項,但您可以輕松地遵循 EI文檔。
使用 XIAO ESP32S3 Sense 捕獲(離線)音頻數據
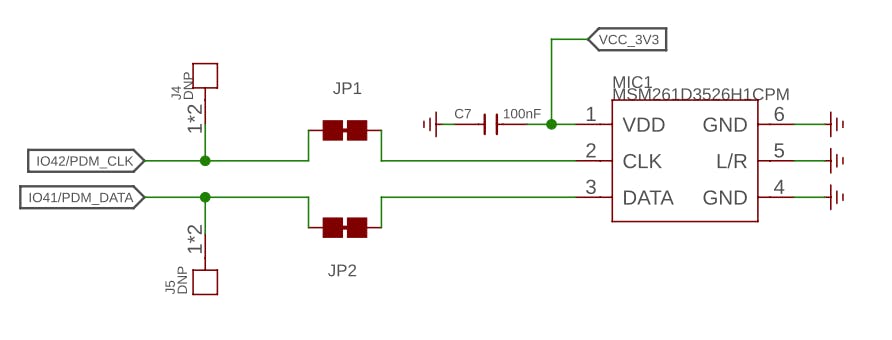
內置麥克風為MSM261D3526H1CPM ,一款具有多模式的PDM數字輸出MEMS麥克風。在內部,它使用引腳 IO41(時鐘)和 IO41(數據)通過 I2S 總線連接到 ESP32S3。
什么是 I2S?
I2S 或 Inter-IC Sound 是一種標準協議,用于將數字音頻從一個設備傳輸到另一個設備。它最初由飛利浦半導體(現為恩智浦半導體)開發。它通常用于音頻設備,例如數字信號處理器、數字音頻處理器,以及最近具有數字音頻功能的微控制器(我們這里的案例)。
I2S協議至少由三行組成:
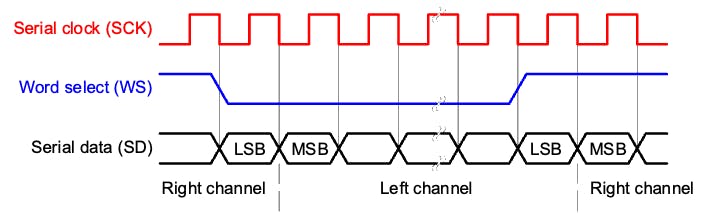
1. 位(或串行)時鐘線(BCLK 或 CLK):該線切換以指示新數據位的開始(引腳 IO42)。
2. 單詞選擇線 (WS) :此行切換以指示新單詞的開始(左聲道或右聲道)。字選擇時鐘的頻率定義了采樣率。在我們的例子中,麥克風上的 L/R 設置為接地,這意味著我們將僅使用左聲道(單聲道)。
3.數據線(SD):此線承載音頻數據(引腳IO41)
在 I2S 數據流中,數據作為幀序列發送,每個幀包含一個左聲道字和一個右聲道字。這使得 I2S 特別適合傳輸立體聲音頻數據。但是,它也可以用于帶有附加數據線的單聲道或多聲道音頻。
讓我們開始了解如何使用麥克風捕獲原始數據。轉到GitHub 項目并下載草圖:XIAOEsp2s3_Mic_Test :
/*
XIAO ESP32S3 Simple Mic Test
*/
#include
void setup() {
Serial.begin(115200);
while (!Serial) {
}
// start I2S at 16 kHz with 16-bits per sample
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, 16000, 16)) {
Serial.println("Failed to initialize I2S!");
while (1); // do nothing
}
}
void loop() {
// read a sample
int sample = I2S.read();
if (sample && sample != -1 && sample != 1) {
Serial.println(sample);
}
}
此代碼是使用 I2S(Inter-IC Sound)接口對 XIAO ESP32S3 進行的簡單麥克風測試。它設置 I2S 接口以 16 kHz 的采樣率捕獲音頻數據,每個樣本 16 位,然后連續從麥克風讀取樣本并將它們打印到串行監視器。
讓我們深入研究代碼的主要部分:
-
Include the I2S library:此庫提供配置和使用I2S 接口的功能,這是連接數字音頻設備的標準。 -
I2S.setAllPins(-1, 42, 41, -1, -1):這會設置 I2S 引腳。參數為(-1,42,41,-1,-1),其中第二個參數(42)為I2S時鐘(CLK)的PIN,第三個參數(41)為I2S數據的PIN (數據)線。其他參數設置為 -1,表示未使用這些引腳。 -
I2S.begin(PDM_MONO_MODE, 16000, 16):這會在脈沖密度調制 (PDM) 單聲道模式下初始化 I2S 接口,采樣率為 16 kHz,每個樣本 16 位。如果初始化失敗,則會打印一條錯誤消息,并且程序會停止。 -
int sample = I2S.read():這從 I2S 接口讀取音頻樣本。
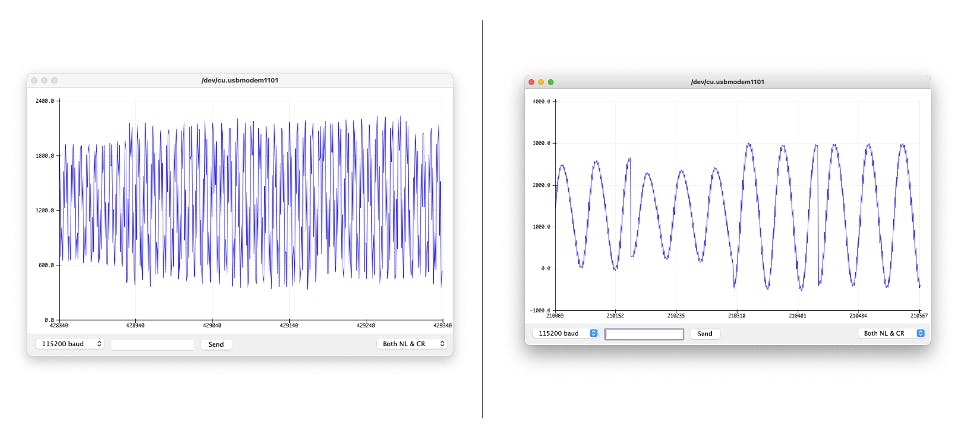
如果樣本有效,它會打印在串行監視器和繪圖儀上。
下面是用兩種不同音調“耳語”的測試。
將錄制的聲音樣本(數據集)作為.wav 音頻文件保存到 microSD 卡中。
讓我們使用板載SD卡讀卡器來保存.wav音頻文件;我們需要先修復 XIAO PSRAM。
ESP32-S3 在 MCU 芯片上只有幾百 KB 的內部 RAM。對于某些用途,ESP32-S3 可以使用與 SPI 閃存芯片并聯的最多 16 MB 的外部 PSRAM(偽靜態 RAM)可能不夠。外部存儲器包含在存儲器映射中,并且在某些限制下,可以像內部數據 RAM 一樣使用。
首先,如下圖所示將 SD 卡插入 XIAO(SD 卡應格式化為 FAT32)。

開啟ESP-32芯片的PSRAM功能(Arduino IDE):Tools>PSRAM: "OPI PSRAM”>OPI PSRAM
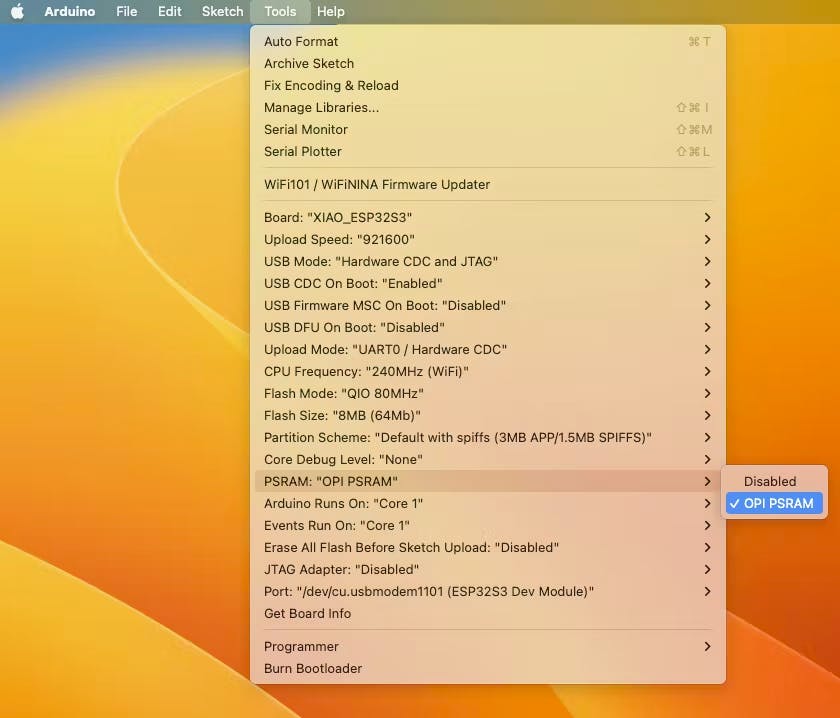
- 下載可以在項目的 GitHub 上找到的草圖Wav_Record_dataset 。
此代碼使用 Seeed XIAO ESP32S3 Sense 板的 I2S 接口錄制音頻,將錄音保存為 SD 卡上的 a.wav 文件,并允許通過串行監視器發送的命令控制錄音過程。音頻文件的名稱是可自定義的(它應該是用于培訓的班級標簽),并且可以制作多個錄音,每個錄音都保存在一個新文件中。該代碼還包括增加錄音音量的功能。
讓我們分解其中最重要的部分:
#include
#include "FS.h"
#include "SD.h"
#include "SPI.h"
這些是該程序必需的庫。I2S.h允許音頻輸入,FS.h提供文件系統處理能力,SD.h允許程序與 SD 卡交互,并SPI.h處理與 SD 卡的 SPI 通信。
#define RECORD_TIME 10
#define SAMPLE_RATE 16000U
#define SAMPLE_BITS 16
#define WAV_HEADER_SIZE 44
#define VOLUME_GAIN 2
這里,為程序定義了各種常量。
-
RECORD_TIME以秒為單位指定錄音的長度。 -
SAMPLE_RATE并SAMPLE_BITS定義錄音的音頻質量。 -
WAV_HEADER_SIZE指定 .wav 文件頭的大小。 -
VOLUME_GAIN用于增加錄音的音量。
int fileNumber = 1;
String baseFileName;
bool isRecording = false;
這些變量跟蹤當前文件號(以創建唯一文件名)、基本文件名以及系統當前是否正在記錄。
void setup() {
Serial.begin(115200);
while (!Serial);
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, SAMPLE_RATE, SAMPLE_BITS)) {
Serial.println("Failed to initialize I2S!");
while (1);
}
if(!SD.begin(21)){
Serial.println("Failed to mount SD Card!");
while (1);
}
Serial.printf("Enter with the label name\n");
}
該setup函數初始化串行通信、用于音頻輸入的 I2S 接口和 SD 卡接口。如果 I2S 沒有初始化或者 SD 卡掛載失敗,它會打印錯誤信息并停止執行。
void loop() {
if (Serial.available() > 0) {
String command = Serial.readStringUntil('\n');
command.trim();
if (command == "rec") {
isRecording = true;
} else {
baseFileName = command;
fileNumber = 1; //reset file number each time a new basefile name is set
Serial.printf("Send rec for starting recording label \n");
}
}
if (isRecording && baseFileName != "") {
String fileName = "/" + baseFileName + "." + String(fileNumber) + ".wav";
fileNumber++;
record_wav(fileName);
delay(1000); // delay to avoid recording multiple files at once
isRecording = false;
}
}
在主循環中,程序等待來自串行監視器的命令。如果命令是rec,則程序開始錄制。否則,該命令被假定為.wav 文件的基本名稱。如果它當前正在錄制并且設置了基本文件名,它會錄制音頻并將其保存為.wav 文件。文件名是通過將文件編號附加到基本文件名生成的。
void record_wav(String fileName)
{
...
File file = SD.open(fileName.c_str(), FILE_WRITE);
...
rec_buffer = (uint8_t *)ps_malloc(record_size);
...
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, rec_buffer, record_size, &sample_size, portMAX_DELAY);
...
}
此函數錄制音頻并將其保存為具有給定名稱的.wav 文件。它首先初始化sample_size和record_size變量。record_size根據采樣率、大小和所需的記錄時間計算。讓我們深入研究重要部分;
File file = SD.open(fileName.c_str(), FILE_WRITE);
// Write the header to the WAV file
uint8_t wav_header[WAV_HEADER_SIZE];
generate_wav_header(wav_header, record_size, SAMPLE_RATE);
file.write(wav_header, WAV_HEADER_SIZE);
這段代碼打開SD卡上的文件進行寫入,然后使用函數生成.wav文件頭generate_wav_header。然后它將標頭寫入文件。
// PSRAM malloc for recording
rec_buffer = (uint8_t *)ps_malloc(record_size);
if (rec_buffer == NULL) {
Serial.printf("malloc failed!\n");
while(1) ;
}
Serial.printf("Buffer: %d bytes\n", ESP.getPsramSize() - ESP.getFreePsram());
該ps_malloc函數在 PSRAM 中為記錄分配內存。如果分配失敗(即為rec_bufferNULL),它會打印一條錯誤消息并停止執行。
// Start recording
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, rec_buffer, record_size, &sample_size, portMAX_DELAY);
if (sample_size == 0) {
Serial.printf("Record Failed!\n");
} else {
Serial.printf("Record %d bytes\n", sample_size);
}
該i2s_read函數從麥克風讀取音頻數據到rec_buffer. 如果沒有讀取數據(sample_size 為 0),它會打印一條錯誤消息。
// Increase volume
for (uint32_t i = 0; i < sample_size; i += SAMPLE_BITS/8) {
(*(uint16_t *)(rec_buffer+i)) <<= VOLUME_GAIN;
}
這部分代碼通過將樣本值移動 . 來增加錄音音量VOLUME_GAIN。
// Write data to the WAV file
Serial.printf("Writing to the file ...\n");
if (file.write(rec_buffer, record_size) != record_size)
Serial.printf("Write file Failed!\n");
free(rec_buffer);
file.close();
Serial.printf("Recording complete: \n");
Serial.printf("Send rec for a new sample or enter a new label\n\n");
最后將音頻數據寫入.wav文件。如果寫入操作失敗,它會打印一條錯誤消息。寫入后,分配給的內存rec_buffer被釋放,文件被關閉。該函數通過打印完成消息并提示用戶發送新命令來結束。
void generate_wav_header(uint8_t *wav_header, uint32_t wav_size, uint32_t sample_rate)
{
...
memcpy(wav_header, set_wav_header, sizeof(set_wav_header));
}
該generate_wav_header函數根據參數 (wav_size和sample_rate) 創建一個.wav 文件頭。它根據 .wav 文件格式生成一個字節數組,其中包括文件大小、音頻格式、通道數、采樣率、字節率、塊對齊、每個樣本的位數和數據大小的字段。然后將生成的標頭復制到wav_header傳遞給函數的數組中。
現在,將代碼上傳到 XIAO 并從關鍵字(是和否)中獲取樣本。您還可以捕捉噪音和其他詞語。
串口監視器將提示您接收要記錄的標簽。
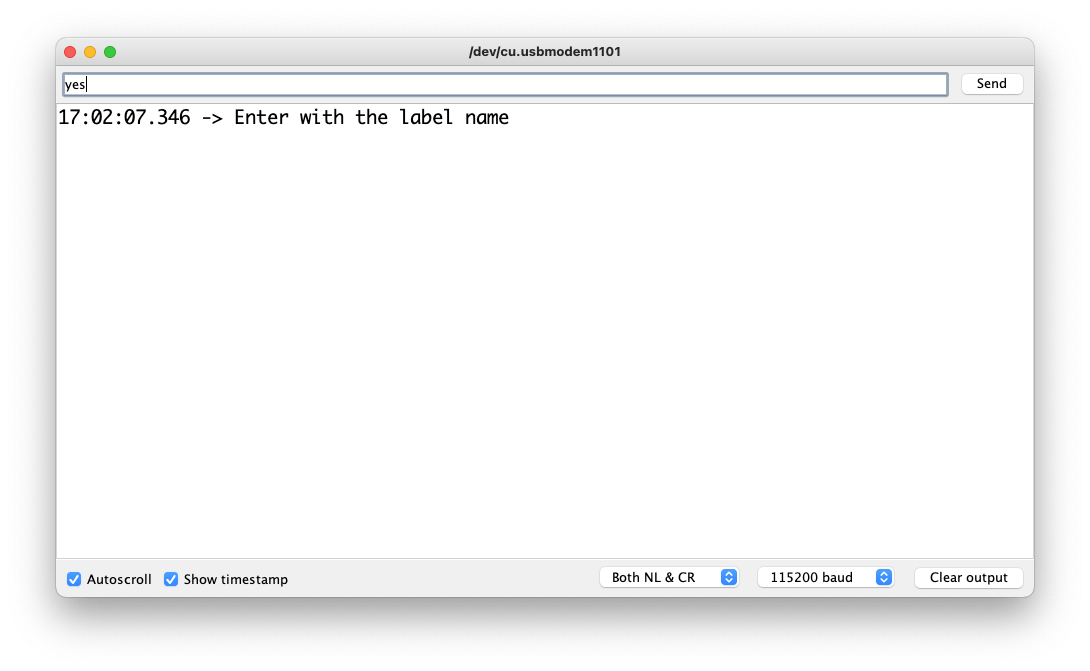
發送標簽(例如,是)。該程序將等待另一個命令:rec
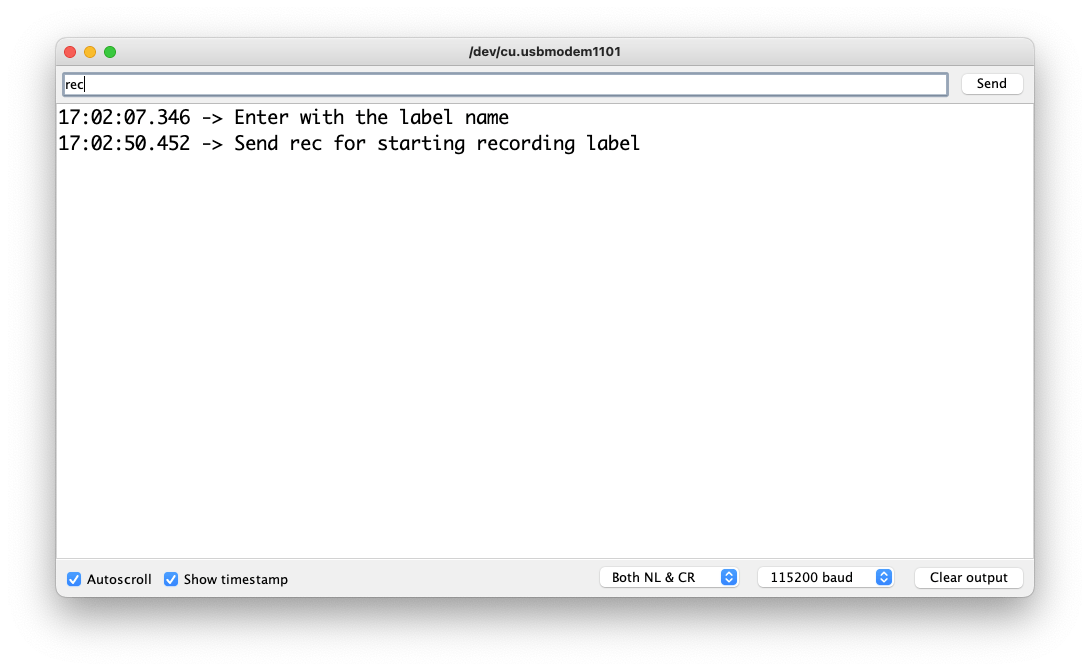
每次發送命令 rec 時,程序都會開始記錄新樣本。文件將保存為 yes.1.wav、yes.2.wav、yes.3.wav 等,直到發送新標簽(例如,no)。在這種情況下,您應該為每個新樣本發送命令 rec,它將被保存為 no.1.wav、no.2.wav、no.3.wav 等。
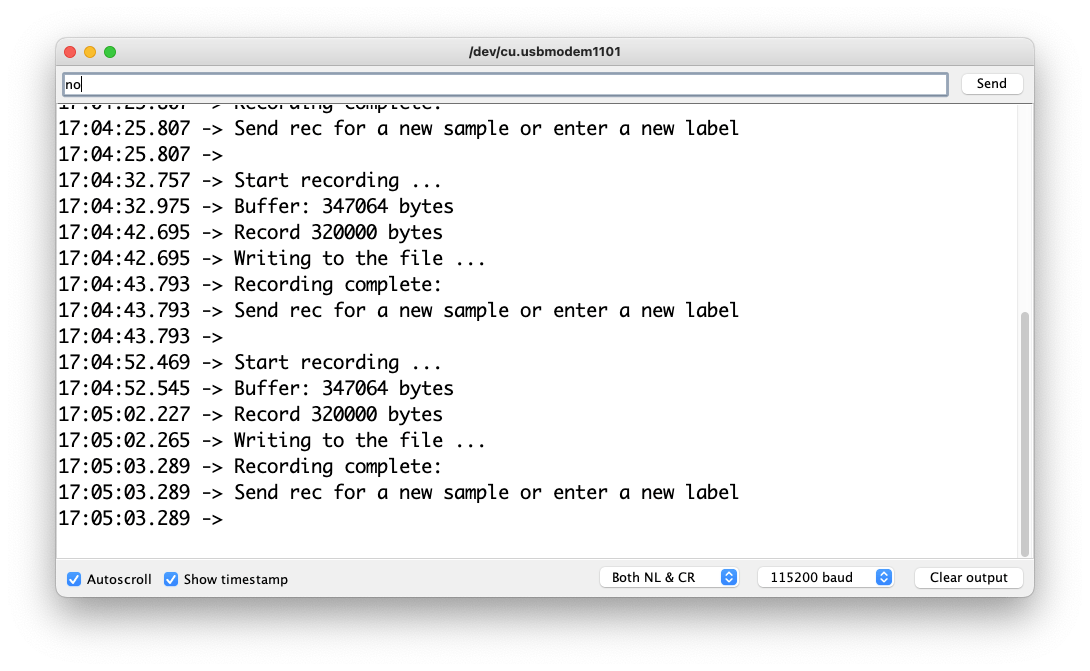
最終,我們將得到保存在 SD 卡上的文件。
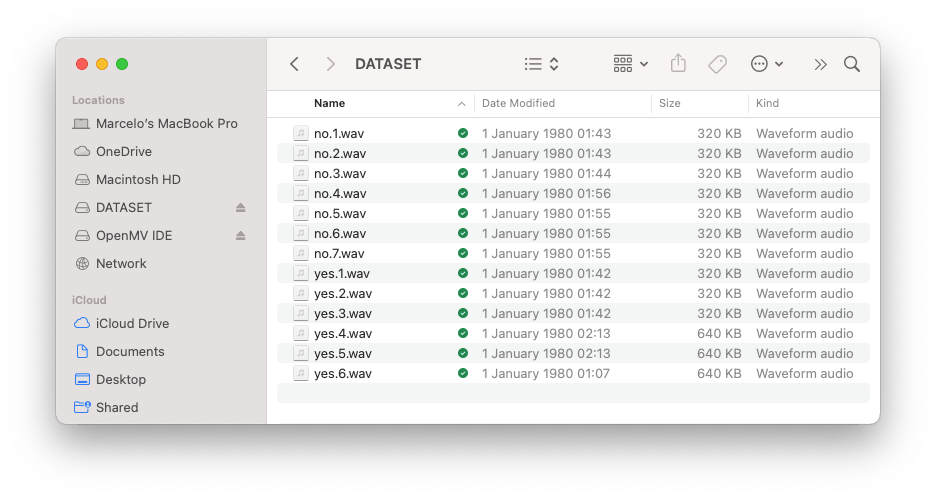
文件已準備好上傳到 Edge Impulse Studio
使用智能手機或 PC 捕獲(離線)音頻數據
或者,您可以使用 PC 或智能手機以 16KHz 的采樣頻率和 16 位的位深度捕獲音頻數據。一個很好的應用程序是Voice Recorder Pro ( IOS)。您應該將您的記錄保存為.wav 文件并將它們發送到您的計算機。
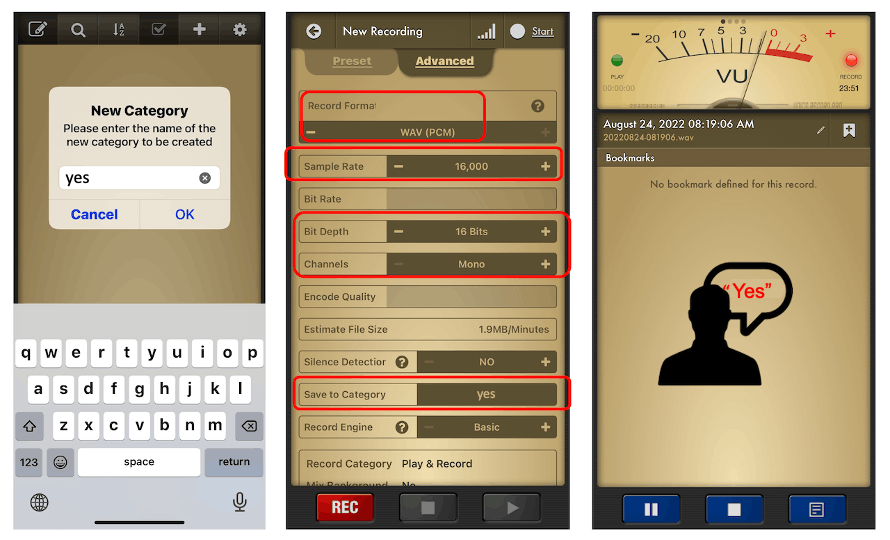
請注意,任何智能手機應用程序(例如Audacity )都可用于錄音甚至您的計算機。
使用 Edge Impulse Studio 訓練模型
定義和收集原始數據集(Pete 的數據集 + 記錄的關鍵字)后,我們應該在 Edge Impulse Studio 啟動一個新項目:
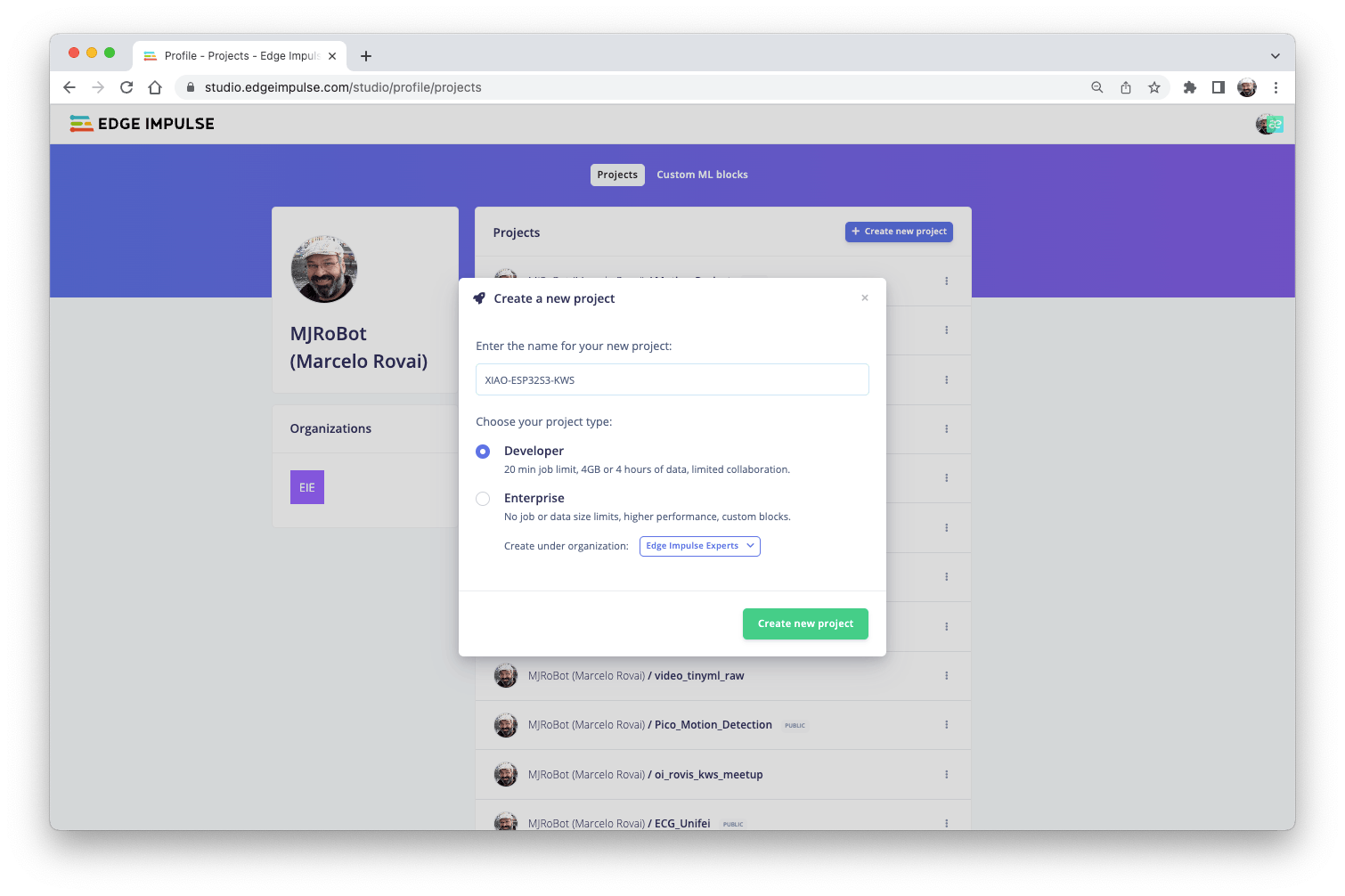
創建項目后,選擇Upload Existing Data該Data Acquisition部分中的工具。選擇要上傳的文件:
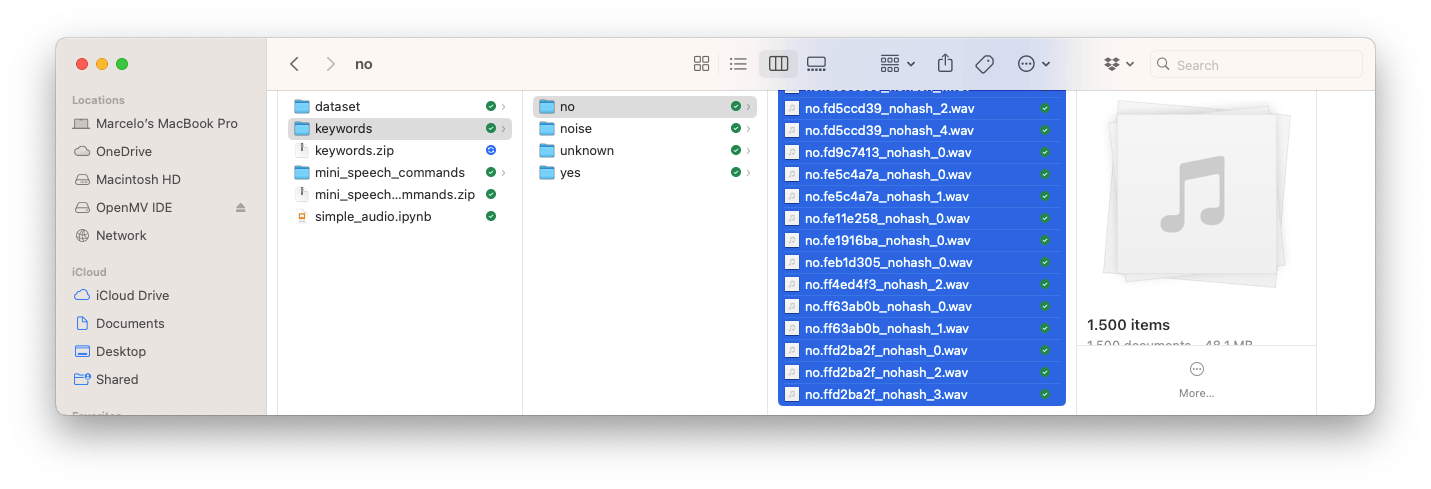
并將它們上傳到工作室(您可以在訓練/測試中自動拆分數據)。重復所有類和所有原始數據。
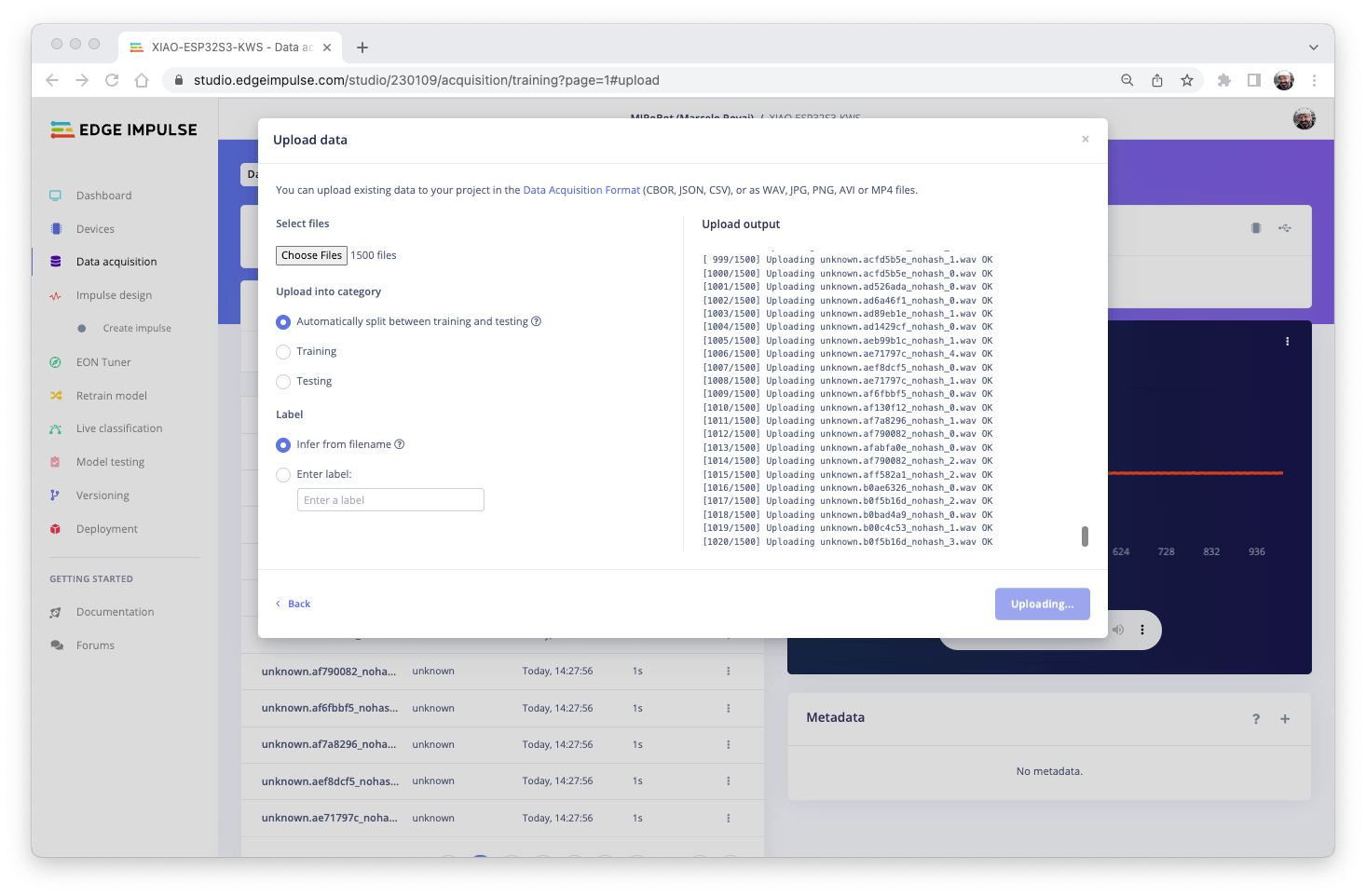
示例現在將出現在該Data acquisition部分中。
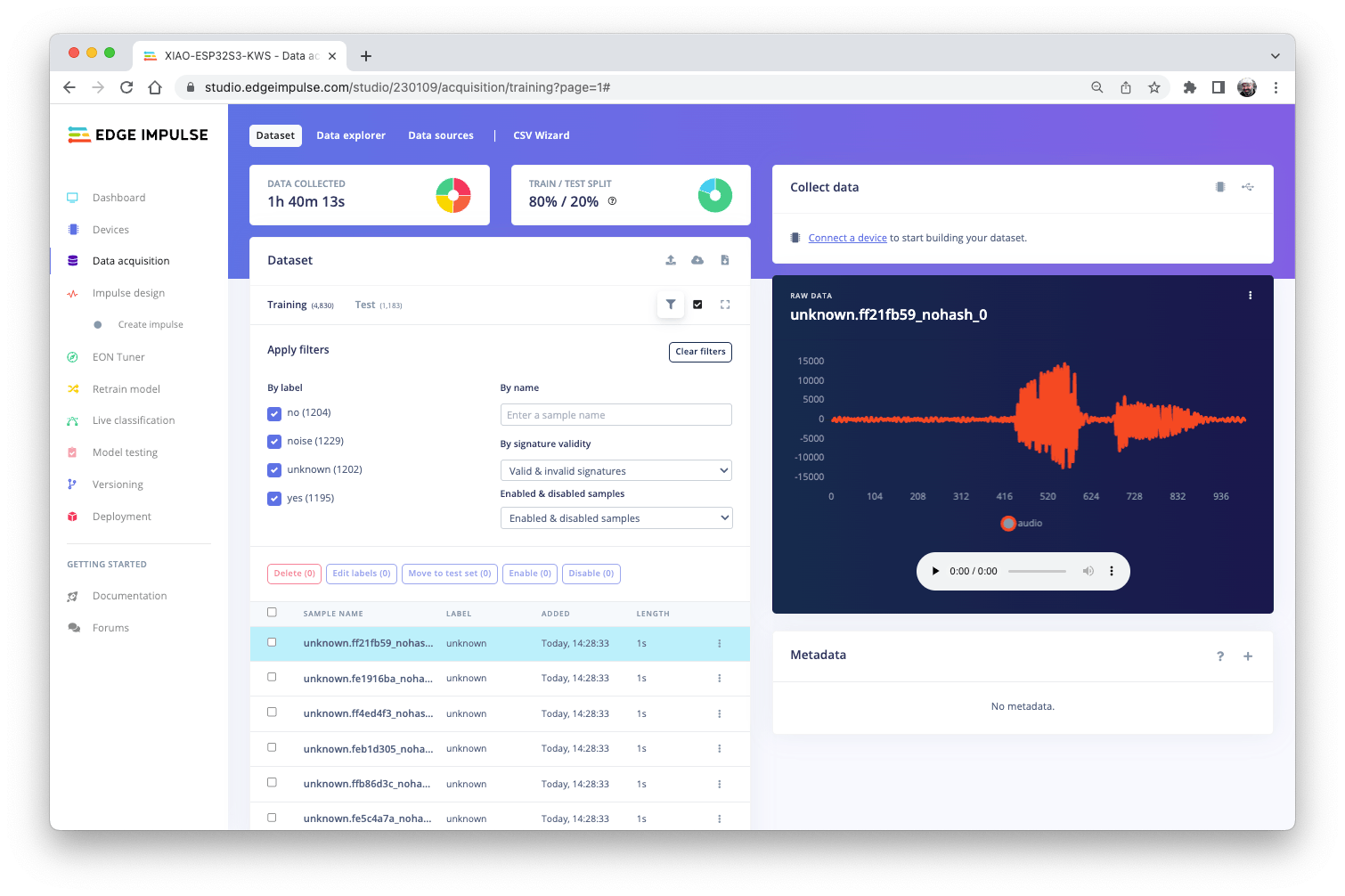
Pete的數據集上所有數據的長度都是1s,但是上一節記錄的樣本長度是10s,必須拆分成1s的樣本才能兼容。
單擊示例名稱后的三個點并選擇Split sample。
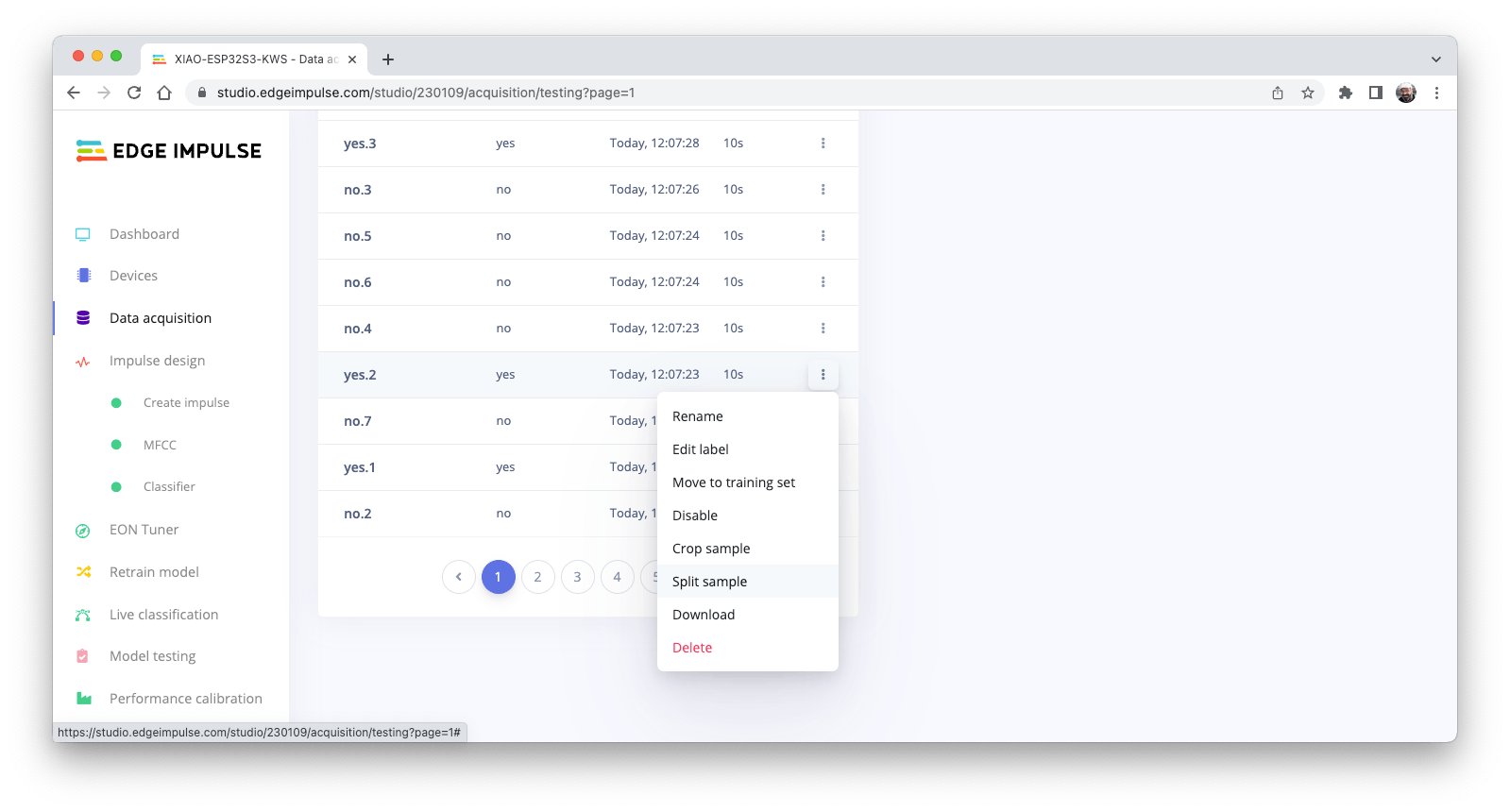
一旦進入 de 工具,將數據拆分為 1 秒記錄。如有必要,添加或刪除段:
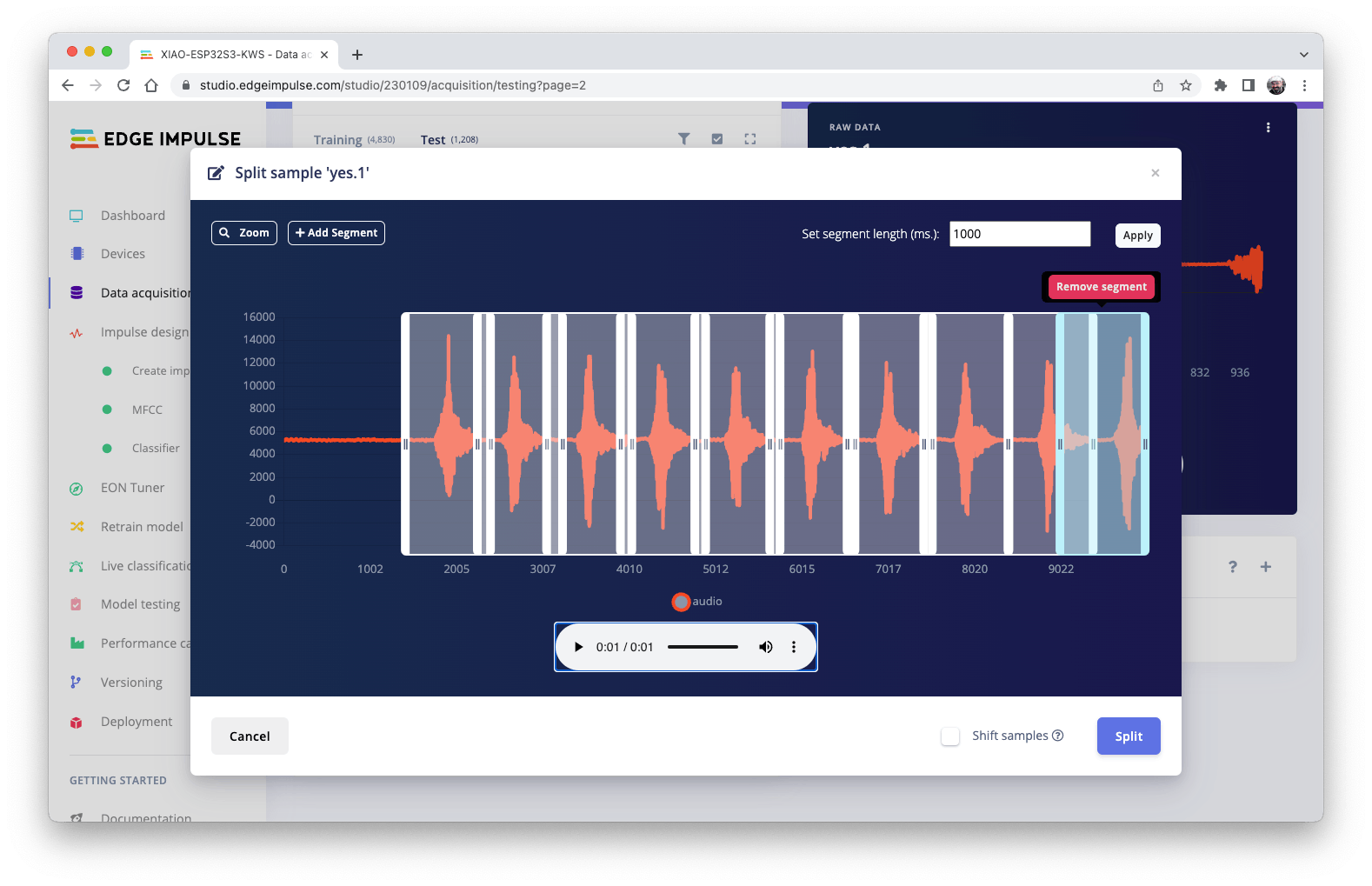
應對所有樣品重復此過程。
注意:對于較長的音頻文件(分鐘),首先,拆分為 10 秒的片段,然后再次使用該工具獲得最后的 1 秒拆分。
假設我們在上傳期間不在訓練/測試中自動拆分數據。在這種情況下,我們可以手動完成(使用三點菜單,單獨移動樣本)或使用Perform Train / Test Spliton Dashboard - Danger Zone。
我們可以選擇使用選項卡檢查所有數據集Data Explorer。
創造沖動(預處理/模型定義)
脈沖獲取原始數據,使用信號處理來提取特征,然后使用學習塊對新數據進行分類。
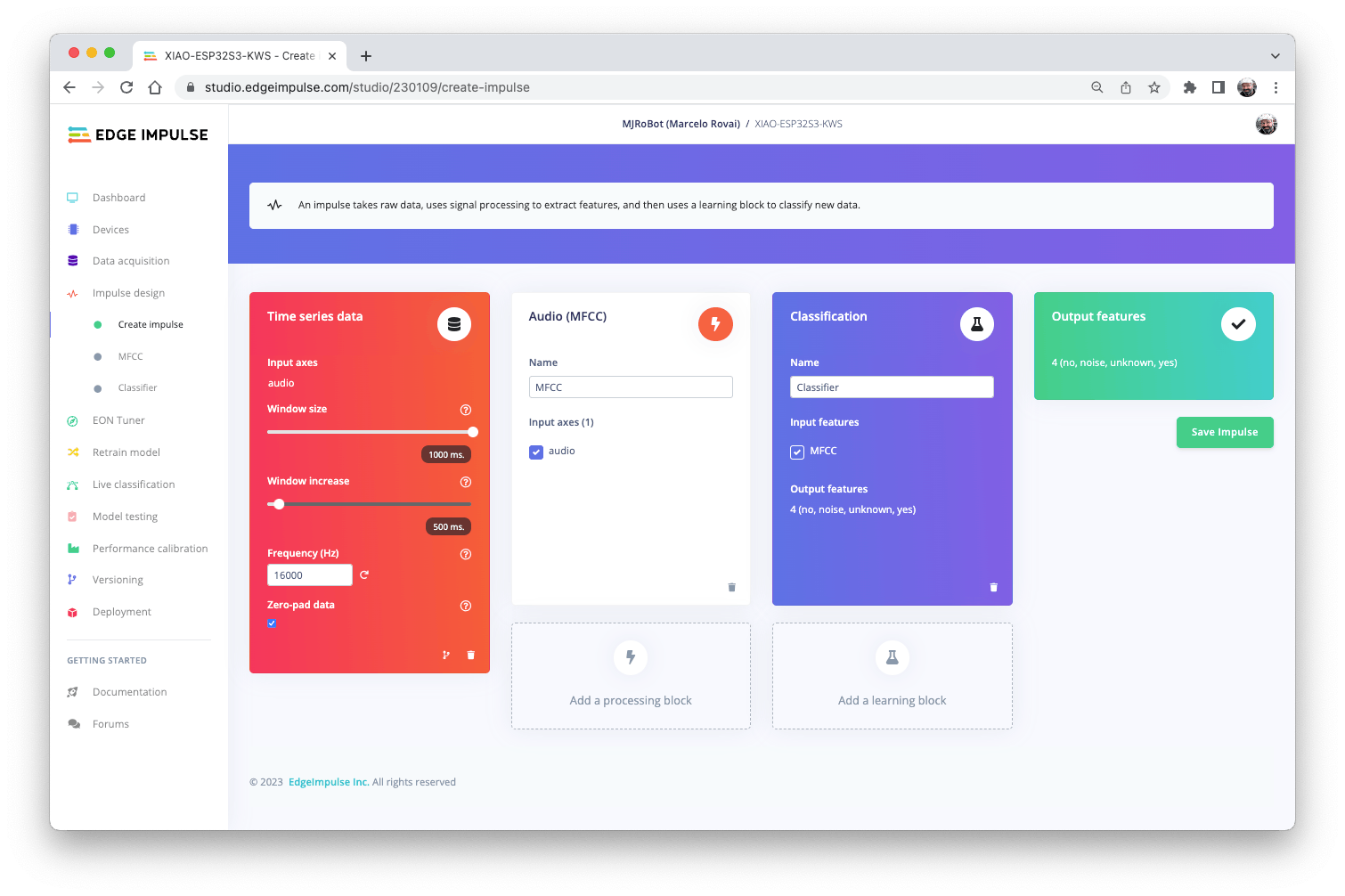
首先,我們將使用 1 秒窗口獲取數據點,增加數據,每 500 毫秒滑動該窗口。請注意,該選項zero-pad data已設置。這對于填充小于 1 秒的零樣本很重要(在某些情況下,我減少了 1000 毫秒的窗口以split tool避免噪音和尖峰)。
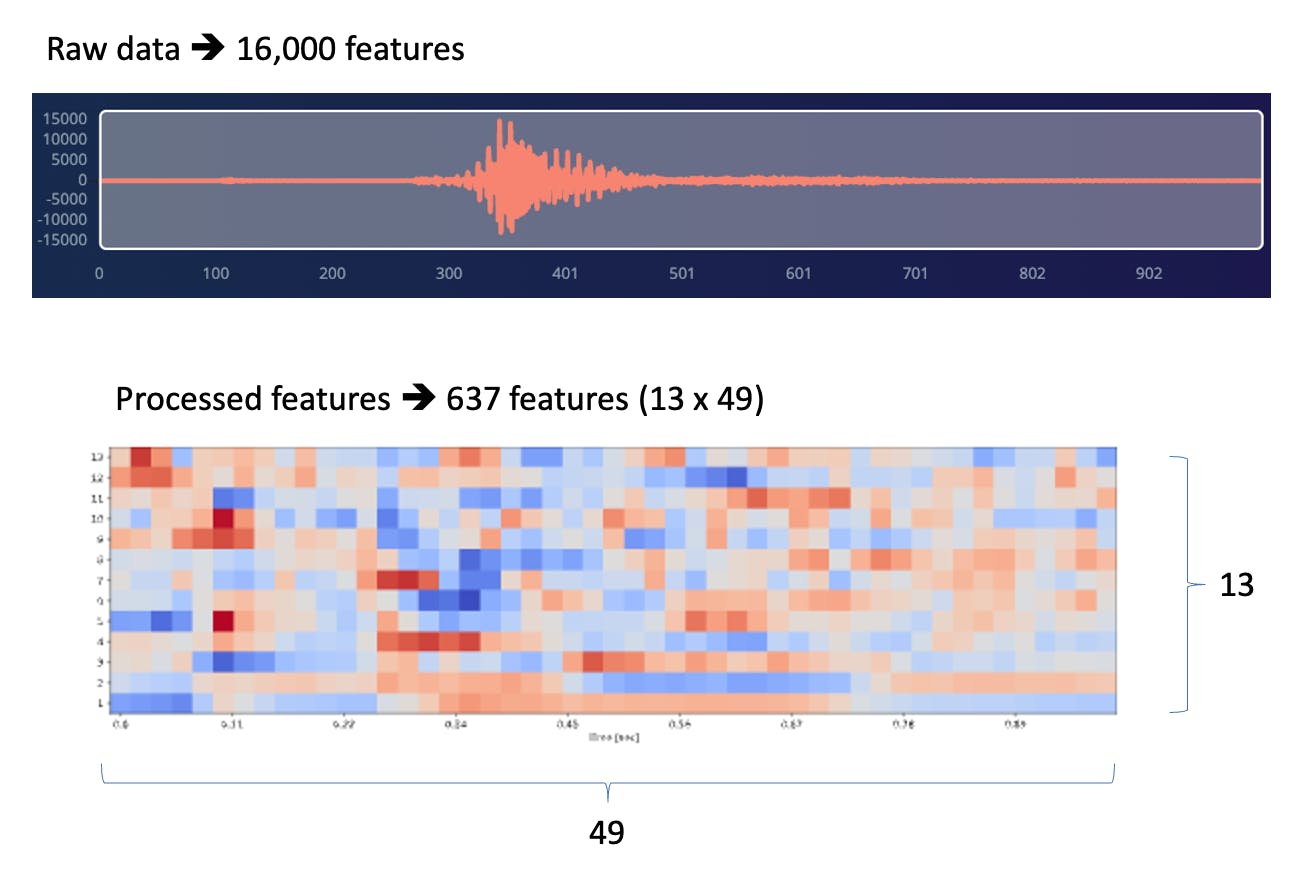
每個 1 秒的音頻樣本都應進行預處理并轉換為圖像(例如,13 x 49 x 1)。我們將使用 MFCC,它使用梅爾頻率倒譜系數從音頻信號中提取特征,這對人聲非常有用。
接下來,我們KERAS通過使用卷積神經網絡進行圖像分類來選擇從頭開始構建模型的分類。
預處理 (MFCC)
下一步是創建要在下一階段訓練的圖像:
我們可以保留默認參數值或利用 DSPAutotuneparameters選項,我們將這樣做。
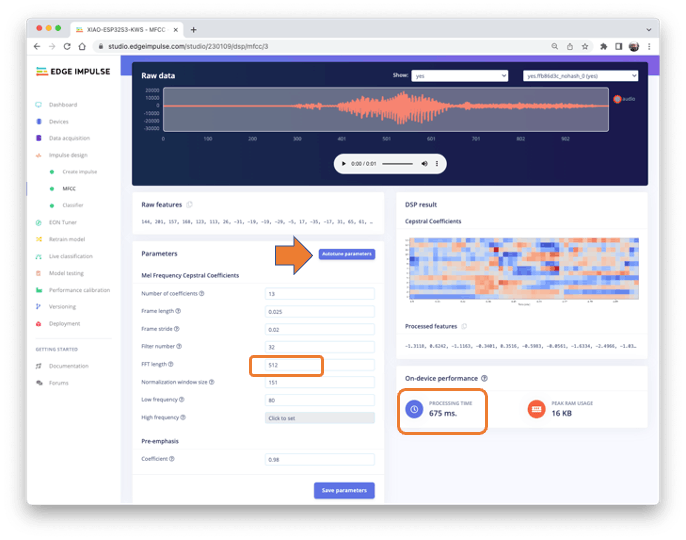
結果不會花費太多內存來預處理數據(僅 16KB)。盡管如此,Espressif ESP-EYE 的估計處理時間仍然很高,為 675 毫秒(最接近的可用參考),時鐘頻率為 240KHz(與我們的設備相同),但 CPU 更小(XTensa LX6,與 ESP32S 上的 LX7 相比) ). 真正的推理時間應該更小。
假設我們以后需要減少推理時間。在這種情況下,我們應該返回到預處理階段,例如減少到FFT length、256更改Number of coefficients或其他參數。
現在,讓我們保留工具定義的參數Autotuning。Save parameters并生成特征。
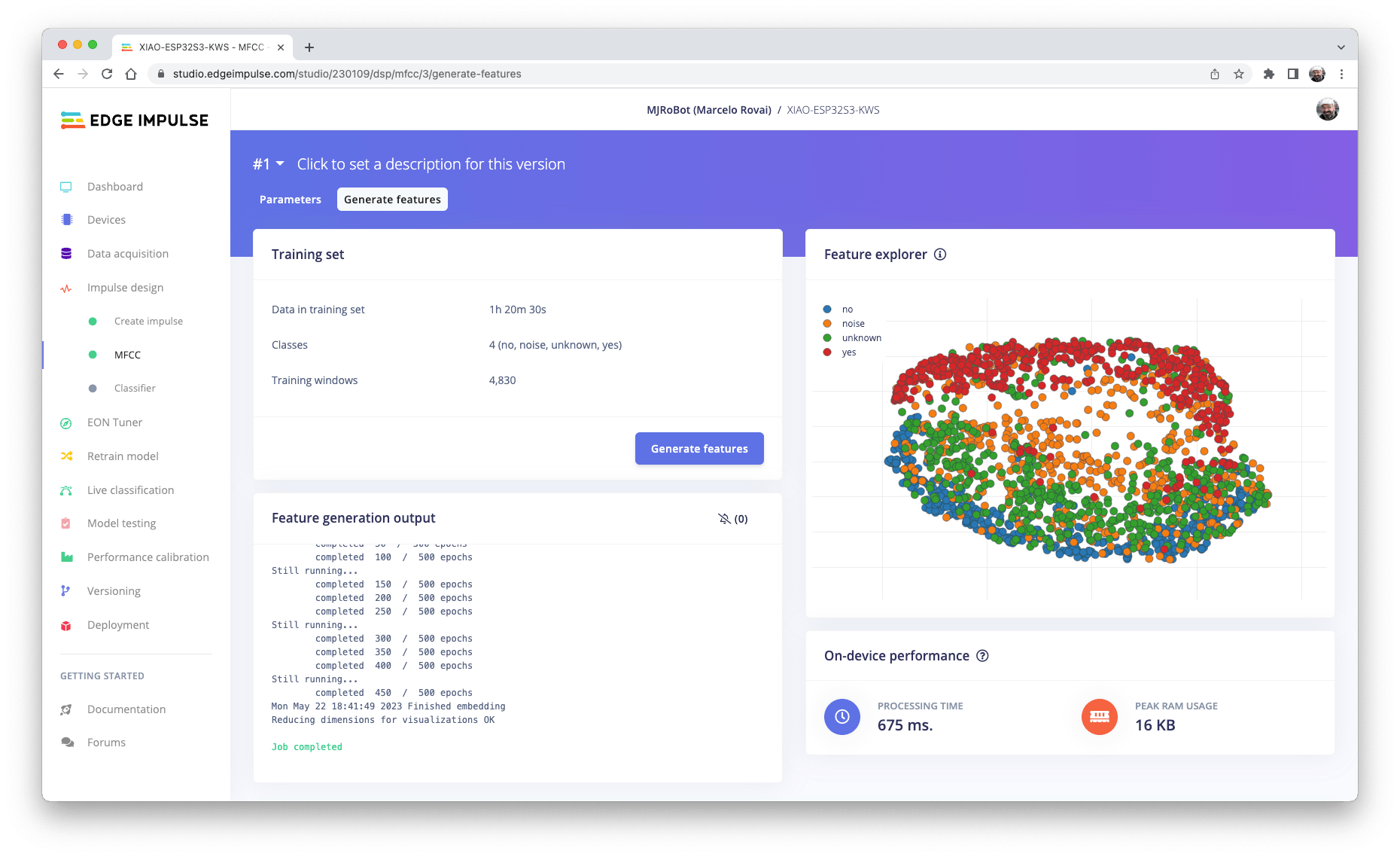
如果您想進一步使用 FFT、頻譜圖等將時間序列數據轉換為圖像,您可以使用這個 CoLab:IESTI01_Audio_Raw_Data_Analisys.ipynb。
模型設計與訓練
我們將使用卷積神經網絡 (CNN) 模型。基本架構由兩個 Conv1D + MaxPooling 塊(分別具有 8 個和 16 個神經元)和 0.25 Dropout 定義。在最后一層,在 Flattening 四個神經元之后,每個類一個:
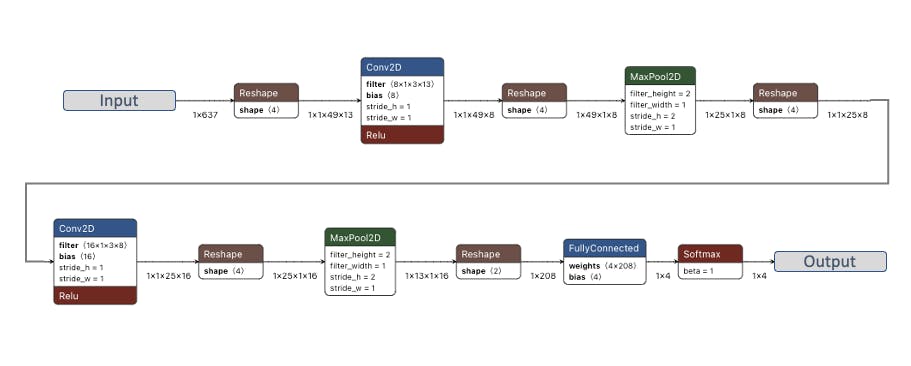
作為超參數,我們將有一個學習率0.005和一個將由100epochs 訓練的模型。我們還將包括數據增強,作為一些噪音。結果似乎沒問題:
如果您想了解“幕后”發生的事情,您可以下載數據集并運行 Jupyter Notebook 來處理代碼。例如,您可以按每個時期分析準確性:
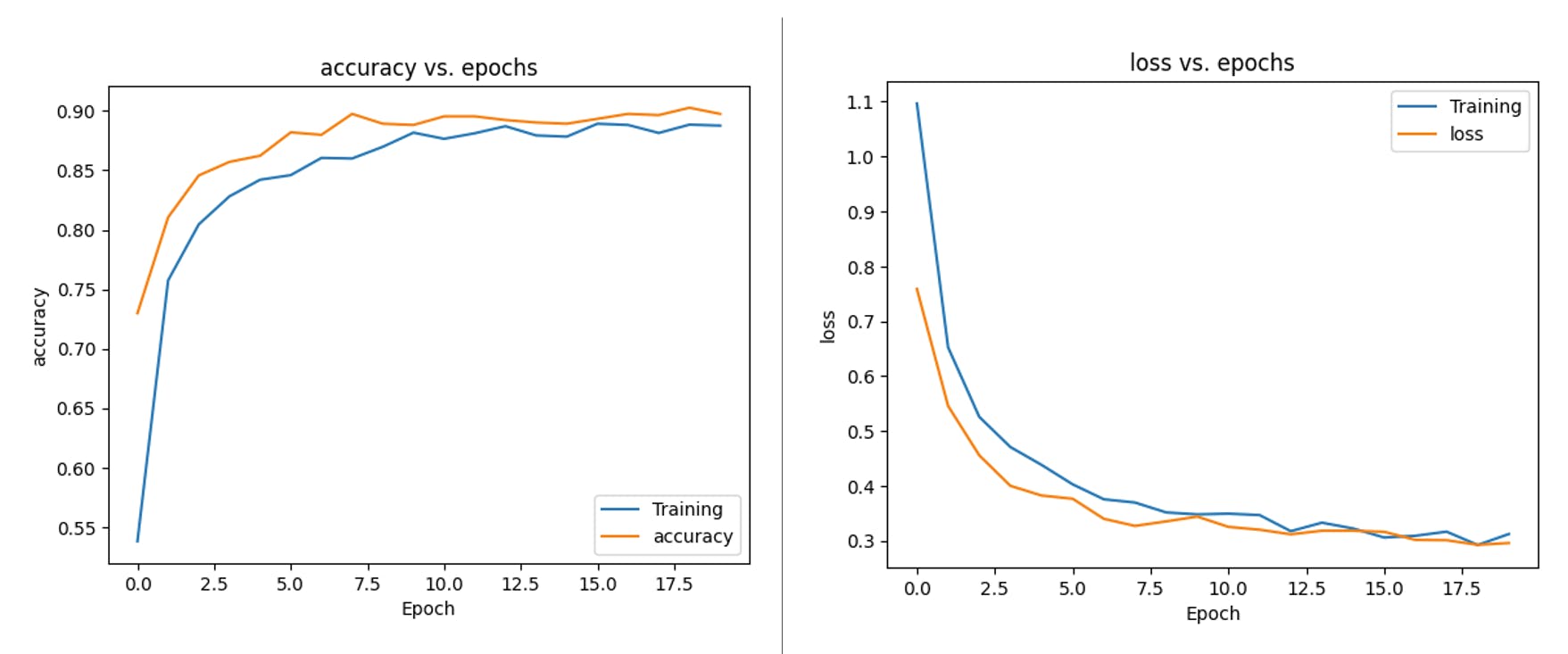
這個 CoLab Notebook 可以解釋你如何才能走得更遠:KWS 分類器項目 - 看“引擎蓋下”。
測試
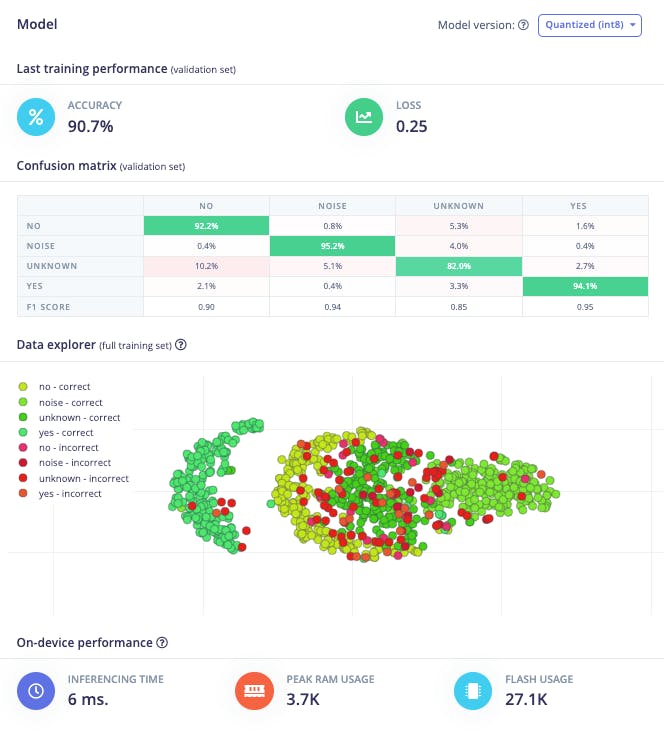
使用訓練前分開的數據(測試數據)測試模型,我們得到了大約 87% 的準確率。
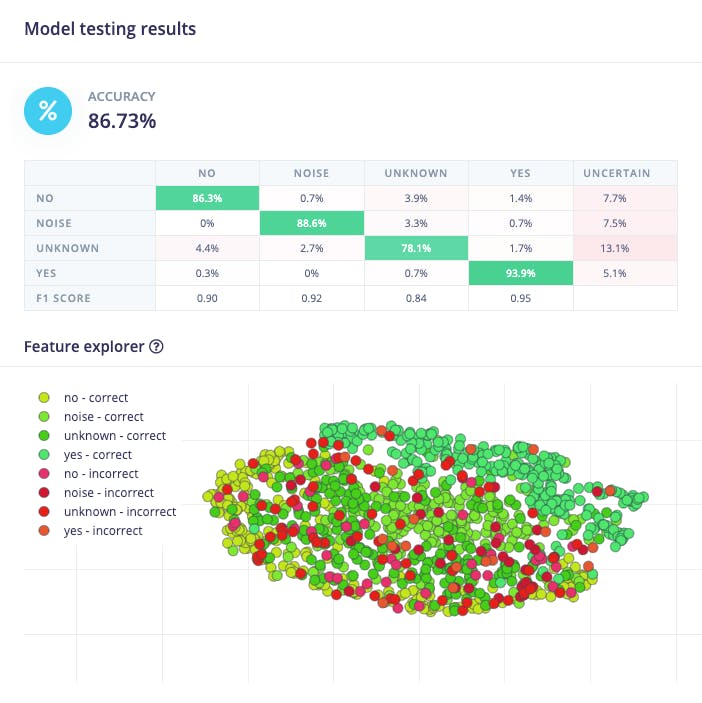
檢查 F1 分數,我們可以看到 YES。一旦我們使用此關鍵字“觸發”我們的后處理階段(打開內置 LED),我們得到了 0.95,這是一個很好的結果。即使是 NO,我們也得到 0.90。最壞的結果是未知,什么都可以。
我們可以繼續該項目,但在我們的設備上部署之前,可以使用智能手機執行實時分類。轉到該Live Classification部分并單擊Connect a Development board:
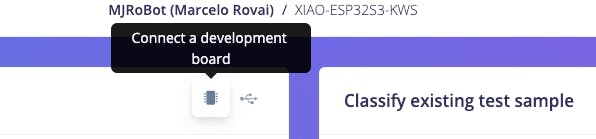
將您的手機指向條形碼并選擇鏈接。
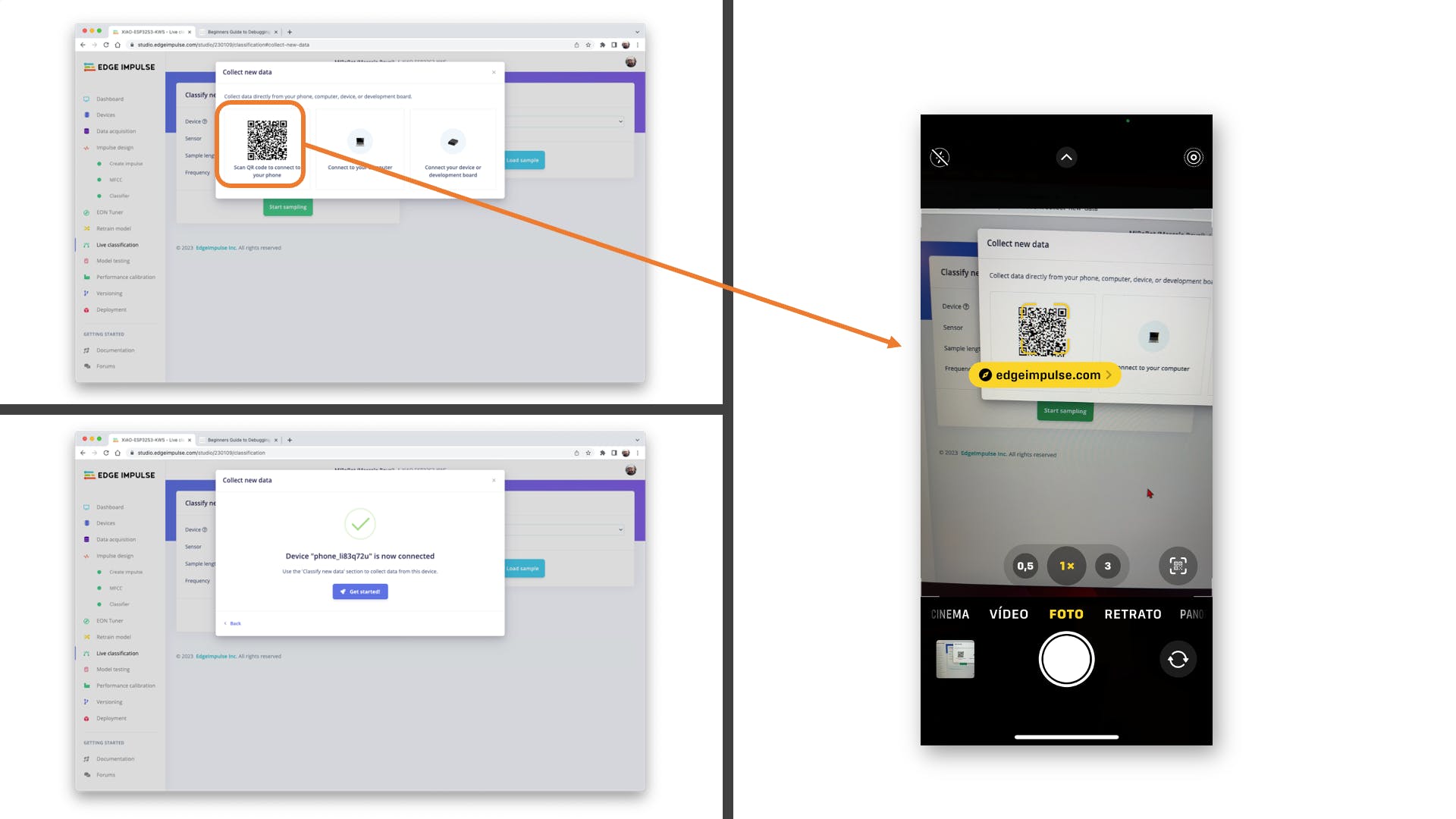
您的手機將連接到 Studio。選擇應用程序上的選項Classification,當它運行時,開始測試您的關鍵字,確認模型正在使用實時和真實數據:
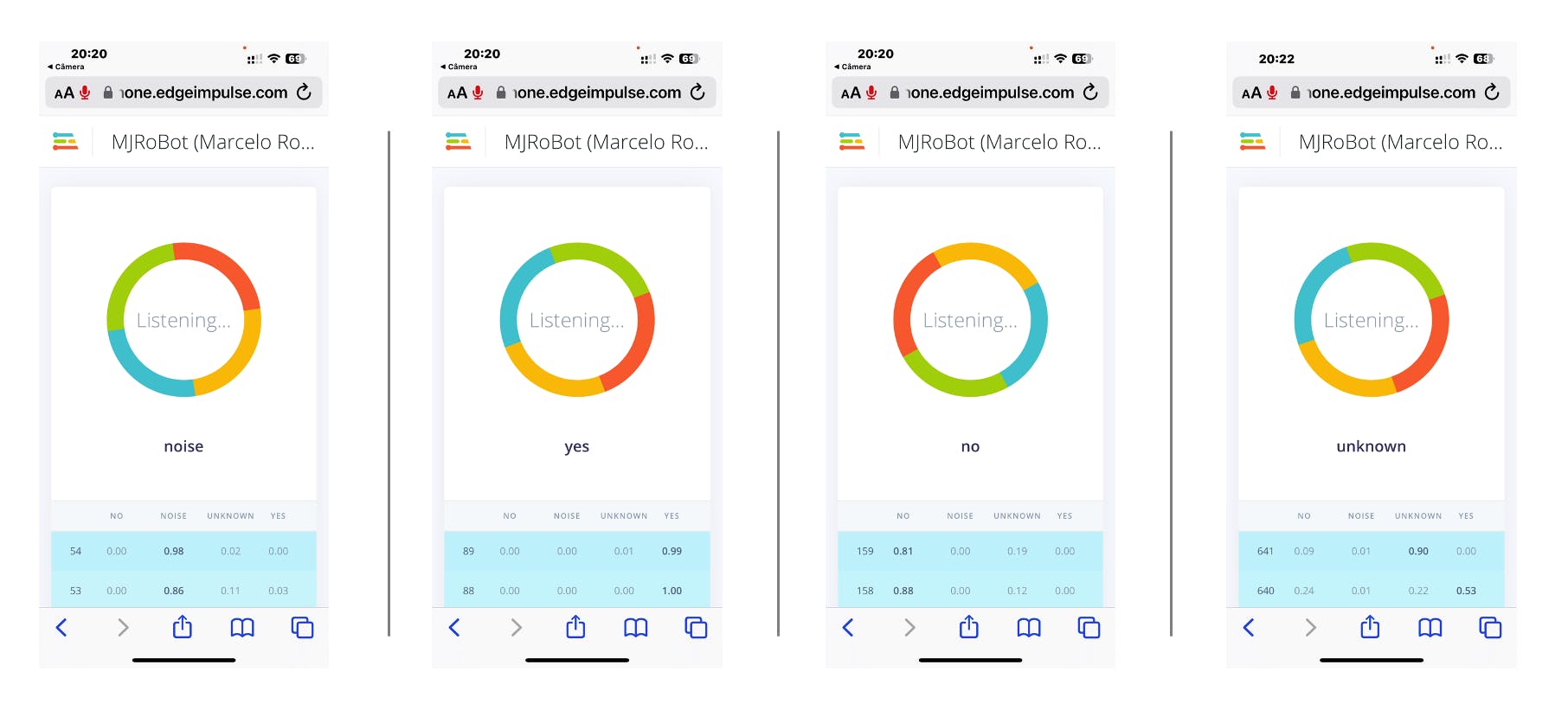
部署和推理
Studio 將打包所有需要的庫、預處理函數和經過訓練的模型,并將它們下載到您的計算機上。您應該選擇該選項Arduino Library,然后在底部選擇Quantized (Int8)并按下按鈕Build。
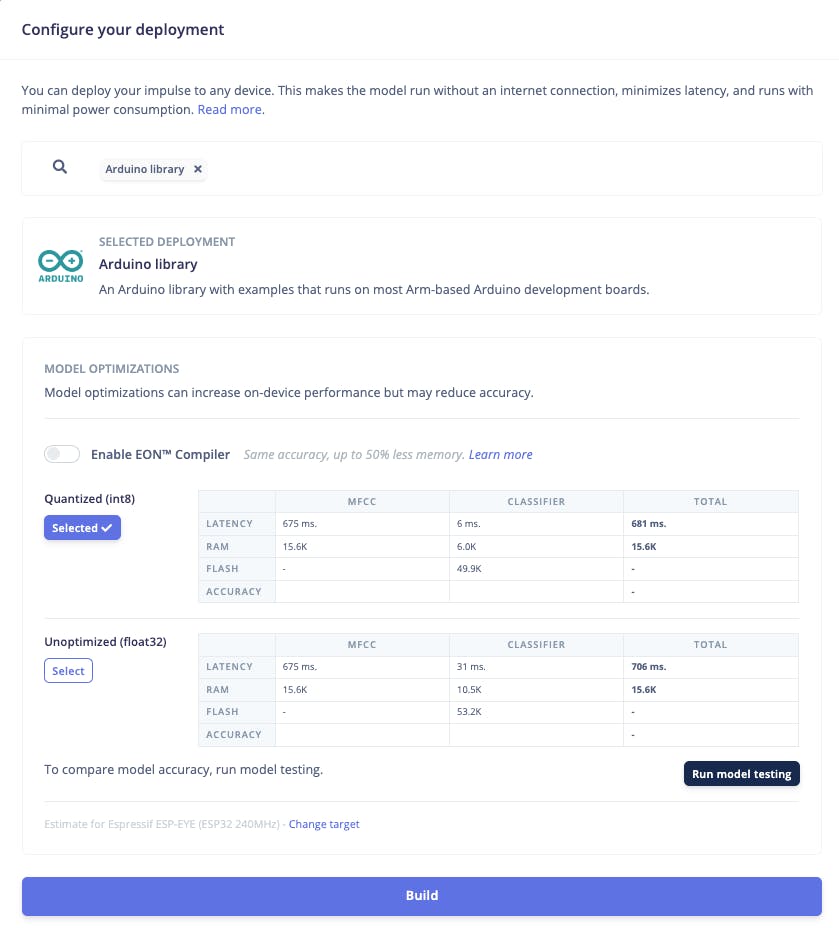
盡管 Edge Impulse 尚未發布其使用 ESP NN 加速器的 ESP32S3 SDK,但感謝Dmitry Maslov,我們可以為 ESP32-S3 恢復和修復其裝配優化。這個解決方案還不是官方的,一旦他們解決了與其他板卡的沖突,EI 將把它包含在 EI SDK 中。
目前,這僅適用于非 EON 版本。因此,您還應該保留未選中的選項Enable EON Compiler。
選擇構建按鈕后,將創建一個 Zip 文件并將其下載到您的計算機。在您的 Arduino IDE 上,轉到 Sketch 選項卡并選擇選項Add .ZIP Library,然后選擇 Studio 下載的 .zip 文件:

在我們使用下載的庫之前,我們需要啟用 ESP NN 加速器。為此,您可以從項目 GitHub 下載一個初步版本,解壓縮,然后用它替換 ESP NN 文件夾:src/edge-impulse-sdk/porting/espressif/ESP-NN,在您的 Arduino 庫文件夾中。
現在是真正測試的時候了。我們將做出與工作室完全脫節的推論。讓我們更改部署 Arduino 庫時創建的 ESP32 代碼示例之一。
在您的 Arduino IDE 中,轉到File/Examples選項卡并查找您的項目,然后選擇esp32/esp32_microphone:
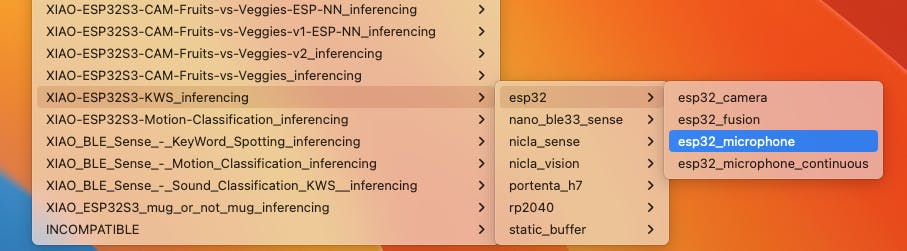
此代碼是為 ESP-EYE 內置麥克風創建的,應該適用于我們的設備。
開始更改庫以處理 I2S 總線:

經過:
#include
#define SAMPLE_RATE 16000U
#define SAMPLE_BITS 16
在 setup() 中初始化 IS2 麥克風,包括以下行:
void setup()
{
...
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, SAMPLE_RATE, SAMPLE_BITS)) {
Serial.println("Failed to initialize I2S!");
while (1) ;
...
}
在static void capture_samples(void* arg)函數上,替換從 I2S mic 讀取數據的第 153 行:

經過:
/* read data at once from i2s */
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
在 function 上static bool microphone_inference_start(uint32_t n_samples),我們應該注釋或刪除第 198 到 200 行,其中調用了麥克風初始化函數。這不是必需的,因為 I2S 麥克風在 ) 期間已經初始化setup(。

最后,在static void microphone_inference_end(void)功能上,替換第 243 行:

經過:
static void microphone_inference_end(void)
{
free(sampleBuffer);
ei_free(inference.buffer);
}
您可以在項目的 GitHub上找到完整的代碼。將草圖上傳到您的電路板并測試一些真實的推論:
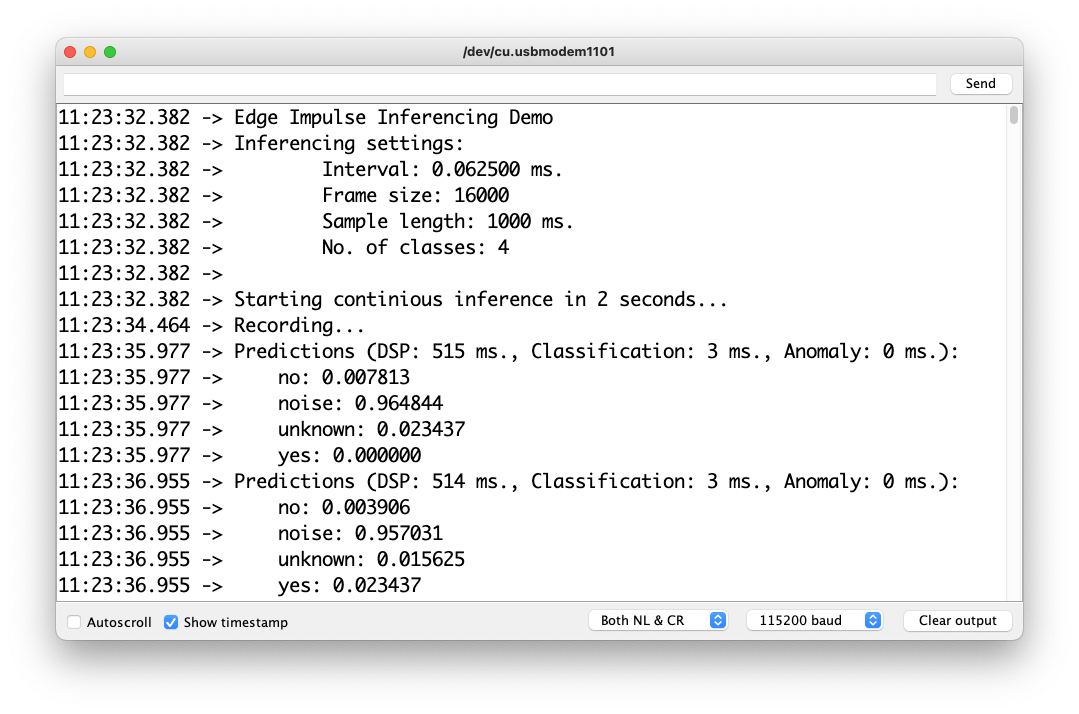
后期處理
現在我們知道模型通過檢測我們的關鍵字工作,讓我們修改代碼以查看每次檢測到 YES 時內部 LED 亮起。
您應該初始化 LED:
#define LED_BUILT_IN 21
...
void setup()
{
...
pinMode(LED_BUILT_IN, OUTPUT); // Set the pin as output
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
...
}
并更改// print the predictions 先前代碼的部分(在loop():
int pred_index = 0; // Initialize pred_index
float pred_value = 0; // Initialize pred_value
// print the predictions
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
if (result.classification[ix].value > pred_value){
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// show the inference result on LED
if (pred_index == 3){
digitalWrite(LED_BUILT_IN, LOW); //Turn on
}
else{
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
}
您可以在項目的 GitHub 上找到完整的代碼。將草圖上傳到您的電路板并測試一些真實的推論:
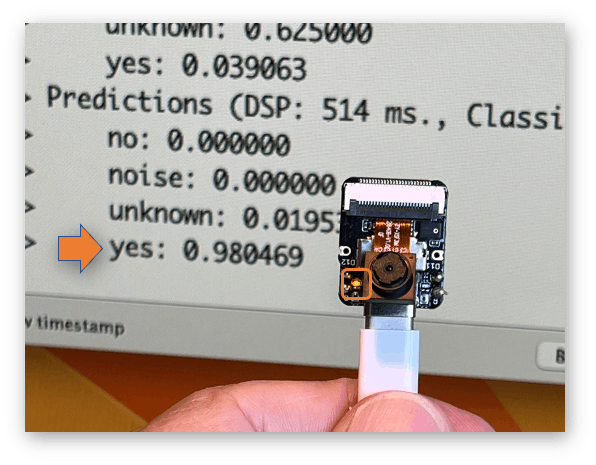
這個想法是,只要檢測到關鍵字 YES,LED 就會亮起。同樣,這不是打開 LED,而是外部設備的“觸發器”,正如我們在介紹中看到的那樣。
結論
Seeed XIAO ESP32S3 Sense 是一個巨大的微型設備!然而,它功能強大、值得信賴、價格不貴、功耗低,并且具有適用于最常見的嵌入式機器學習應用(如視覺和聲音)的傳感器。盡管 Edge Impulse 并未正式支持 XIAO ESP32S3 Sense(目前!),但我們意識到使用 Studio 進行訓練和部署非常簡單。
在我的GitHub 存儲庫中,您將找到該項目中使用的所有代碼的最新版本以及 XIAO ESP32S3 系列的先前版本。
在我們結束之前,請考慮聲音分類不僅僅是語音。例如,您可以在多個領域圍繞聲音開發 TinyML 項目,例如:
- 安全(碎玻璃檢測)
- 工業(異常檢測)
- 醫療(打鼾、輾轉反側、肺部疾病)
- 自然(蜂箱控制、昆蟲聲音)
了解更多
如果您想了解有關嵌入式機器學習 (TinyML) 的更多信息,請參閱以下參考資料:
- “ TinyML - 嵌入設備的機器學習” - UNIFEI
- “微型機器學習專業證書 (TinyML)” – edX/Harvard
- 《嵌入式機器學習入門》- Coursera/Edge Impulse
- “帶有嵌入式機器學習的計算機視覺” - Coursera/Edge Impulse
- Fran?ois Chollet 的“ Deep Learning with Python”
- Pete Warden 和 Daniel Situnayake 的“ TinyML”
- Gian Marco Iodice 的“ TinyML Cookbook”
- Daniel Situnayake 和 Jenny Plunkett 的“ AI at the Edge”
在TinyML4D 網站上,您可以找到很多關于 TinyML 的教育資料。它們都是免費和開源的,用于教育用途——我們要求如果您使用這些材料,請引用它們!TinyML4D 是一項旨在讓全球所有人都能獲得 TinyML 教育的倡議。
?
- TinyML變得簡單:圖像分類
- TinyML課程#7變得更小
- 語音識別_ML-KWS-for-MCU_資料整理
- 云服務器中同態加密關鍵詞檢索方案分析 5次下載
- 基于關鍵詞的GCC抽象語法樹消除冗余算法 210次下載
- 一種基于位置信息的關鍵詞自動化提取算法 3次下載
- 一種基于詞和文檔嵌入的關鍵詞抽取方法 4次下載
- 結合通配符模式與隨機游走算法的關鍵詞提取方法 14次下載
- 融合BERT詞向量與TextRank的關鍵詞抽取方法 18次下載
- 支持檢索關鍵詞語義擴展的可排序密文檢索方案詳細資料說明 15次下載
- 實現支持檢索關鍵詞語義擴展的可排序密文檢索的方案詳細說明 10次下載
- 對加密電子醫療記錄的關鍵詞的搜索 0次下載
- 基于關鍵詞相似度的用戶挖掘研究 0次下載
- 基于強度熵解決中文關鍵詞識別 7次下載
- 基于動態排位信息的語音關鍵詞確認方法
- 如何在雅特力AT32 MCU上實現關鍵詞語音識別(KWS) 680次閱讀
- 基于SensiML平臺開發語音關鍵詞識別 410次閱讀
- 在MAX78000上開發功耗優化應用 713次閱讀
- 如何使用TinyML在內存受限的設備上部署ML模型呢 958次閱讀
- 如何才能自己做詞云圖 8002次閱讀
- 如何在 MCU 上快速部署 TinyML 1689次閱讀
- 如何利用TinyML實現語音識別機器人車的設計 2110次閱讀
- dfrobot語音識別控制板 介紹 2976次閱讀
- Python數據挖掘:WordCloud詞云配置過程及詞頻分析 3848次閱讀
- 一種改變標準的谷歌關鍵詞搜索的新方式 6723次閱讀
- 基于Cortex-M處理器上實現高精度關鍵詞語音識別 1911次閱讀
- 自然語言處理技術入門之基于關鍵詞生成文本的技術實現過程 1w次閱讀
- 如何讓光伏逆變器效率測量變得更簡單 1492次閱讀
- 科普:12大關鍵詞讓你了解機器學習 1815次閱讀
- 工控行業熱搜榜十大關鍵詞 5025次閱讀

 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1山景DSP芯片AP8248A2數據手冊
- 1.06 MB | 532次下載 | 免費
- 2RK3399完整板原理圖(支持平板,盒子VR)
- 3.28 MB | 339次下載 | 免費
- 3TC358743XBG評估板參考手冊
- 1.36 MB | 330次下載 | 免費
- 4DFM軟件使用教程
- 0.84 MB | 295次下載 | 免費
- 5元宇宙深度解析—未來的未來-風口還是泡沫
- 6.40 MB | 227次下載 | 免費
- 6迪文DGUS開發指南
- 31.67 MB | 194次下載 | 免費
- 7元宇宙底層硬件系列報告
- 13.42 MB | 182次下載 | 免費
- 8FP5207XR-G1中文應用手冊
- 1.09 MB | 178次下載 | 免費
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費
- 2555集成電路應用800例(新編版)
- 0.00 MB | 33566次下載 | 免費
- 3接口電路圖大全
- 未知 | 30323次下載 | 免費
- 4開關電源設計實例指南
- 未知 | 21549次下載 | 免費
- 5電氣工程師手冊免費下載(新編第二版pdf電子書)
- 0.00 MB | 15349次下載 | 免費
- 6數字電路基礎pdf(下載)
- 未知 | 13750次下載 | 免費
- 7電子制作實例集錦 下載
- 未知 | 8113次下載 | 免費
- 8《LED驅動電路設計》 溫德爾著
- 0.00 MB | 6656次下載 | 免費
總榜
- 1matlab軟件下載入口
- 未知 | 935054次下載 | 免費
- 2protel99se軟件下載(可英文版轉中文版)
- 78.1 MB | 537798次下載 | 免費
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420027次下載 | 免費
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費
- 6電路仿真軟件multisim 10.0免費下載
- 340992 | 191187次下載 | 免費
- 7十天學會AVR單片機與C語言視頻教程 下載
- 158M | 183279次下載 | 免費
- 8proe5.0野火版下載(中文版免費下載)
- 未知 | 138040次下載 | 免費





 工商網監
工商網監
評論