完善資料讓更多小伙伴認識你,還能領取20積分哦,立即完善>
標簽 > 存儲系統
存儲系統是存放程序和數據的重要系統,存儲這個詞非常平凡,存儲 + 計算(操作)就構成了一個樸素的計算機模型。簡單來說,存儲就是負責維持計算系統的狀態的單元。從維持狀態的角度,我們會有最樸素的可靠性要求。
存儲系統是指計算機中由存放程序和數據的各種存儲設備、控制部件及管理信息調度的設備(硬件)和算法(軟件)所組成的系統。計算機的主存儲器不能同時滿足存取速度快、存儲容量大和成本低的要求,在計算機中必須有速度由慢到快、容量由大到小的多級層次存儲器,以最優的控制調度算法和合理的成本,構成具有性能可接受的存儲系統。
存儲系統
存儲系統的性能在計算機中的地位日趨重要,主要原因是:①馮諾伊曼體系結構是建筑在存儲程序概念的基礎上,訪存操作約占中央處理器(CPU)時間的70%左右。②存儲管理與組織的好壞影響到整機效率。③現代的信息處理,如圖像處理、數據庫、知識庫、語音識別、多媒體等對存儲系統的要求很高。
存儲系統是指計算機中由存放程序和數據的各種存儲設備、控制部件及管理信息調度的設備(硬件)和算法(軟件)所組成的系統。計算機的主存儲器不能同時滿足存取速度快、存儲容量大和成本低的要求,在計算機中必須有速度由慢到快、容量由大到小的多級層次存儲器,以最優的控制調度算法和合理的成本,構成具有性能可接受的存儲系統。
存儲系統
存儲系統的性能在計算機中的地位日趨重要,主要原因是:①馮諾伊曼體系結構是建筑在存儲程序概念的基礎上,訪存操作約占中央處理器(CPU)時間的70%左右。②存儲管理與組織的好壞影響到整機效率。③現代的信息處理,如圖像處理、數據庫、知識庫、語音識別、多媒體等對存儲系統的要求很高。
存儲器的那些事
存儲系統從其與生俱來的使命來說,就難以擺脫復雜系統的魔咒。無論是從單機時代的文件系統,還是后來C/S或B/S結構下數據庫這樣的存儲中間件興起,還是如今炙手可熱的云存儲服務來說,存儲都很復雜,而且是越來越復雜。存儲為什么會復雜,要從什么是存儲談起。存儲這個詞非常平凡,存儲 + 計算(操作)就構成了一個樸素的計算機模型。簡單來說,存儲就是負責維持計算系統的狀態的單元。從維持狀態的角度,我們會有最樸素的可靠性要求。比如單機時代的文件系統,機器斷電、程序故障、系統重啟等常規的異常,文件系統必須可以正確地應對,甚至對于磁盤扇區損壞,文件系統也需要考慮盡量將損失降到最低。對于大部分的業務程序而言,你只需要重點關注業務的正常分支流程就行,對于出乎意料的情況,通常只需拋出一個錯誤,告訴用戶你不該這么玩。但是對于存儲系統,你需要花費絕大部分精力在各種異常情況的處理上,甚至你應該認為,這些龐雜的、多樣的錯誤分支處理,才是存儲系統的“正常業務邏輯”。到了互聯網時代,有了C/S或B/S結構,存儲系統又有了新指標:可用性。為了保證服務質量,那些用戶看不見的服務器程序必須時時保持在線,最好做到邏輯上是不宕機的(可用性100%)。服務器程序怎么才能做到高可用性?答案是存儲中間件。沒有存儲中間件,意味著所有的業務程序,都必須考慮每做一步就對狀態進行持久化,以便自己掛掉后另一臺服務器(或者自己重啟后),知道之前工作到哪里了,接下去應該做些什么。但是對狀態進行持久化(也就是存儲)會非常繁瑣,如果每個業務都自己實現,負擔無疑非常沉重。但如果有了高可用的存儲中間件,服務器端的業務程序就只需操作存儲中間件來更新狀態,通過同時啟動多份業務程序的實例做互備和負載均衡,很容易實現業務邏輯上不宕機。相關廠商內容QCon北京2018全新開啟深度學習框架演進漫談-by老師木智能寫手——智能文本生成在雙十一的應用深度學習在紅豆Live直播推薦系統中的應用美團騎手智能助手的技術與實踐相關贊助商
所以,數據庫這樣的存儲中間件出現基本上是歷史必然。盡管數據庫很通用,但它決不會是唯一的存儲中間件。比如業務中用到的富媒體(圖片、音視頻、Office文檔等),我們很少會去存儲到數據庫中,更多的時候我們會把它們放在文件系統里。但是單機時代誕生的文件系統,真的是最適合存儲這些富媒體數據的么?不,文件系統需要改變,因為:伸縮性。單機文件系統的第一個問題是單機容量有限,在存儲規模超過一臺機器可管理的時候,應該怎么辦。
性能瓶頸。通常,單機文件系統在文件數目達到臨界點后,性能會快速下降。在4TB的大容量磁盤越來越普及的今天,這個臨界點相當容易到達。
可靠性要求。單機文件系統通常只是單副本的方案,但是今天單副本的存儲早已無法滿足業務的可靠性要求。數據需要有冗余(比較經典的做法是3副本),并且在磁盤損壞時及早修復丟失的數據,以避免所有的副本損壞造成數據丟失。
可用性要求。單機文件系統通常只是單副本的方案,在該機器宕機后,數據就不可讀取,也不可寫入。
在分布式存儲系統出現前,有一些基于單機文件系統的改良版本被一些應用采納。比如在單機文件系統上加 RAID5 做數據冗余,來解決單機文件系統的可靠性問題。假設 RAID5 的數據修復時間是1天(實際上往往做不到,尤其是業務系統本身壓力比較大的情況下,留給 RAID 修復用的磁盤讀寫帶寬很有限),這種方案單機的可靠性大概是100年丟失一次數據(即可靠性是2個9)。看起來尚可?但是你得小心兩種情況。一種是你的集群規模變大,你仍然沿用這個土方法,比如你現在有 100 臺這樣的機器,那么就會變成1年就丟失一次數據。另一種情況是如果實際數據修復時間是 3 天,那么單機的可靠性就直降至4年丟失一次數據,100臺就會是15天丟失一次數據。這個數字顯然無法讓人接受。Google GFS 是很多人閱讀的第一份分布式存儲的論文,這篇論文奠定了 3 副本在分布式存儲系統里的地位。隨后 Hadoop 參考此論文實現了開源版的 GFS —— HDFS。但關于 Hadoop 的 HDFS 實際上業界有不少誤區。GFS 的設計有很強的業務背景特征,本身是用來做搜索引擎的。HDFS 更適合做日志存儲和日志分析(數據挖掘),而不是存儲海量的富媒體文件。因為:HDFS 的 block 大小為 64M,如果文件不足 64M 也會占用 64M。而富媒體文件大部分仍然很小,比如圖片常規尺寸在 100K 左右。有人可能會說我可以調小 block 的尺寸來適應,但這是不正確的做法,HDFS 的架構是為大文件而設計的,不可能簡單通過調整 block 大小就可以滿足海量小文件存儲的需求。
HDFS 是單 Master 結構,這決定了它能夠存儲的元數據條目數有限,伸縮性存在問題。當然作為大文件日志型存儲,這個瓶頸會非常晚才遇到;但是如果作為海量小文件的存儲,這個瓶頸很快就會碰上。
HDFS 仍然沿用文件系統的 API 形式,比如它有目錄這樣的概念。在分布式系統中維護文件系統的目錄樹結構,會遭遇諸多難題。所以 HDFS 想把 Master 擴展為分布式的元數據集群并不容易。
分布式存儲最容易處理的問題域還是單鍵值的存儲,也就是所謂的 Key-Value 存儲。只有一個 Key,就意味著我們可以通過對 Key 做 Hash,或者對 Key 做分區,都能夠讓請求快速定位到特定某一臺存儲機器上,從而轉化為單機問題。這也是為什么在數據庫之后,會冒出來那么多 NoSQL 數據庫。因為數據庫和文件系統一樣,最早都是單機的,在伸縮性、性能瓶頸(在單機數據量太大時)、可靠性、可用性上遇到了相同的麻煩。NoSQL 數據庫的名字其實并不恰當,他們更多的不是去 SQL,而是去關系(我們知道數據庫更完整的稱呼是關系型數據庫)。有關系意味著有多個索引,也就是有多個 Key,而這對數據庫轉為分布式存儲系統來說非常不利。七牛云存儲的設計目標是針對海量小文件的存儲,所以它對文件系統的第一個改變也是去關系,也就是去目錄結構(有目錄意味著有父子關系)。所以七牛云存儲不是文件系統(File System),而是鍵值存儲(Key-Value Storage),用時髦點的話說是對象存儲(Object Storage)。不過七牛自己喜歡把它叫做資源存儲(Resource Storage),因為它是用來存儲靜態資源文件的。蠻多七牛云存儲的新手會問,為什么我在七牛的 API 中找不到創建目錄這樣的 API,根本原因還是受文件系統這個經典存儲系統的影響。七牛云存儲的第一個實現版本,從技術上來說是經典的 3 副本的鍵值存儲。它由元數據集群和數據塊集群組成。每個文件被切成了 4M 為單位的一個個數據塊,各個數據塊按 3 副本做冗余。但是作為云存儲,它并不僅僅是一個分布式存儲集群,它需要額外考慮:網絡問題,也就是文件的上傳下載問題。文件上傳方面,我們得考慮在相對比較差的網絡條件下(比如2G/3G網絡)如何確保文件能夠上傳成功,大文件(七牛云存儲的單文件大小理論極限是1TB)如何能夠上傳成功,如何能夠更快上傳。文件下載加速方面,考慮到 CDN 已經發展了 10 多年的歷史,非常成熟,我們決定基于 CDN 來做下載加速。
數據處理。當用戶文件托管到了七牛,那么針對文件內容的數據處理需求也會自然衍生。比如我們第一個客戶就給我們提了圖片縮略圖相關的需求。在音視頻內容越來越多的時候,自然就有了音視頻轉碼的需求。可以預見在Office文檔多了后,也就會有 Office 文檔轉換的需求。
所以從技術上來說,七牛云存儲是這樣的:七牛云存儲 = 分布式存儲集群 + 上傳加速網絡(下載外包給CDN) + 數據處理集群網絡問題并不是七牛要解決的核心問題,只是我們要面對的現實困難。所以在這個問題上如果能夠有足夠專業的供應商,能夠外包我們會盡可能外包。而分布式存儲集群的演進和優化,才是我們最核心的事情。早在 2012 年 2 月,我們就啟動了新一代基于糾刪碼算術冗余的存儲系統的研發。新存儲系統的關注焦點在:成本。經典的 3 副本存儲系統雖然經典,但是代價也是高昂的,需要我們投入 3 倍的存儲成本。那么有沒有保證高可靠和高可用的前提下把成本做下來?
可靠性。如何進一步提升存儲系統的可靠性?答案是更高的容錯能力(從允許同時損壞2塊盤到允許同時損壞4塊盤),更快的修復速度(從原先3小時修復一塊壞盤到30分鐘修復一塊壞盤)。
伸縮性。如何從系統設計容量、IO吞吐能力、網絡拓撲結構等角度,讓系統能夠支持EB級別的數據存儲規模?關于伸縮性這個話題,涉及的點是全方位的,本文不展開討論,后面我們另外獨立探討這個話題(讓我們把焦點放在成本和可靠性上)。
在經過了四個大的版本迭代,七牛新一代云存儲(v2)終于上線。新存儲的第一大亮點是引入了糾刪碼(EC)這樣的算術冗余方案,而不再是經典的 3 副本冗余方案。我們的 EC 采用的是 28 + 4,也就是把文件切分為 28 份,然后再根據這 28 份數據計算出 4 份冗余數據,最后把這 32 份數據存儲在 32 臺不同的機器上。這樣做的好處是既便宜,又提升了可靠性和可用性。從成本角度,同樣是要存儲 1PB 的數據,要買的存儲服務器只需 3 副本存儲的 36.5%,經濟效益相當好。從可靠性方面,以前 3 副本只能允許同時損壞2塊盤,現在能夠允許同時損壞4塊盤,直觀來說這大大改善了可靠性(后面討論可靠性的時候我們給出具體的數據)。從可用性角度,以前能夠接受 2 臺服務器下線,現在能夠同時允許 4 臺服務器下線。新存儲的第二大亮點是修復速度,我們把單盤修復時間從 3 小時提升到了 30 分鐘以內。修復時間同樣對提升可靠性有著重要意義(后面討論可靠性的時候我們給出具體的數據)。這個原因是比較容易理解的。假設我們的存儲允許同時壞 M 塊盤而不丟失數據,那么集群可靠性,就是看在單位修復時間內,同時損壞 M+1 塊盤的概率。例如,假設我們修復時間是 3 小時,那么 3 副本集群的可靠性就是看 3 小時內同時損壞 3 塊盤的概率(也就是丟數據的概率)。讓我們回到存儲系統最核心的指標 —— 可靠性。首先,可靠性和集群規模是相關的。假設我們有 1000 塊磁盤的集群,對于 3 副本存儲系統來說,這 1000 塊盤同時壞 3 塊就會發生數據丟失,這個概率顯然比 3 塊盤同時壞 3 塊要高很多。基于這一點,有些人會想這樣的土方法:那我要不把集群分為 3 塊磁盤一組互為鏡像,1000 塊盤就是 333 組(不好意思多了1塊,我們忽略這個細節),是不是可以提升可靠性?這些同學忽略了這樣一些關鍵點:3 塊盤同時壞 3 塊盤(從而丟失數據)的概率為 p,那么 333 組這樣的集群,丟失數據的概率是 1-(1-p)^333 ≈ p * 333,而不是 p。
互為鏡像的麻煩之處是修復速度存在瓶頸。壞一塊盤后你需要找一個新盤進行數據對拷,而一塊大容量磁盤數據對拷的典型時間是 15 小時(我們后面將給出 15 小時同時壞 3 塊盤的概率)。要想提升這個修復速度,第一步我們就需要打破鏡像帶來的束縛。
如果一個存儲系統的修復時間是恒定的,那么這個存儲集群在規模擴大的時候,必然伴隨著可靠性的降低。所以最理想的情況是集群越大,修復速度越快。這樣才能抵消因集群增大導致壞盤概率增加帶來負面影響。計算表明,如果我們修復速度和集群規模成正比(線性關系),那么集群隨著規模增大,可靠性會越來越高。下表列出了1000塊硬盤的存儲集群在不同存儲方案、不同修復時間下的可靠性計算結果:副本存儲方案容錯度(M)修復時間數據丟失概率(P)可靠性
3副本方案230分鐘1.00E-088個9
3小時1.00E-055個9
15小時1.00E-022個9
28+4算術冗余方案430分鐘1.00E-1616個9
3小時1.00E-1111個9
15小時1.00E-077個9
對于數據丟失概率具體的計算公式和計算方法,由于篇幅所限,本文中不做展開,我會另找機會討論。對我個人而言,七牛新一代云存儲(v2)的完成,了了我多年的夙愿。但七牛不會就此停止腳步。我們在存儲系統上又有了一些好玩的想法。從長遠來說,單位存儲的成本會越來越廉價(硬件和軟件系統都會推動這個發展趨勢)。而存儲系統肯定會越來越復雜。例如,有賴于超高的容錯能力,七牛對單塊磁盤的可靠性要求降低了很多,這就為未來我們采用桌面硬盤而不是企業硬盤作為存儲介質打下基礎。但是單塊磁盤可靠性的降低,則會進一步推動存儲系統往復雜的方向發展。基于這個推理,我認為存儲必然需要轉為云服務,成為水電煤一樣的基礎設施。存儲系統越來越復雜,越來越專業,這就導致自建存儲的難度和成本越來越高,自建存儲的必要性也越來越低。必然有那么一天,你會發現云存儲的成本遠低于自建存儲的成本,到時自建存儲就會是純投入而無產出,也就沒有多少人會去熱衷于干這樣的事情了。

計算機存儲系統作為計算機系統中至關重要的組成部分,其原理和功能對于理解計算機的運行機制具有關鍵意義。以下將詳細闡述計算機存儲系統的原理和功能。
計算機存儲系統是計算機中用于存放程序和數據的設備或部件的集合,它構成了計算機信息處理的基礎。一個完整的計算機存儲系統通常包括多個層次的存儲器,從高速緩存...
在計算機系統中,內存、存儲系統和CPU是三個至關重要的組件,它們各自承擔著不同的職責,共同協作以完成數據處理和運算任務。以下是對這三者之間區別的詳細闡述。
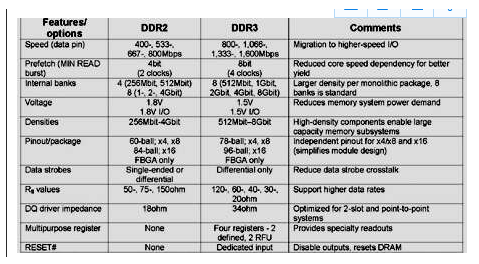
DRAM 技術的進步伴隨著多核處理器、新操作系統的出現,以及對許多不同計算平臺和應用程序(例如服務器、工作站、大容量存儲系統、超級計算機、PC 和外圍設...
實現基于門控線性網絡(GLN)的高壓縮比無損醫學圖像壓縮算法,以提高醫學圖像存儲和分發系統的效率。與“傳統”的基于上下文的數據壓縮算法相比,基于GLN的...
服務重啟變得特別慢且 Sys cpu 被打滿,原因是在服務重啟的過程中需要并發的加載 HDFS 上 Part 的元數據,而 libhdfs3 庫并發讀 ...

智能存儲系統(IntelligentStorageSystem)是一種先進的數據存儲解決方案,它結合了硬件、軟件和自動化管理功能,以實現對數據存儲的高度...
磁盤陣列是一種企業級存儲系統(RAID級別和磁盤陣列可以提高數據的可靠性和性能。在選擇磁盤陣列時,需要考慮容量、性能、可靠性和可擴展性等因素,并進行定制...
雙向逆變器(Bidirectional Inverter)是一種電力轉換裝置,可將直流(DC)電能轉換為交流(AC)電能,同時也能將交流電能轉換為直流電...
緩存對大數據處理的影響顯著且重要,主要體現在以下幾個方面: 一、提高數據訪問速度 在大數據環境中,數據存儲通常采用分布式存儲系統,數據量龐大,直接從存儲...
Redis和Memcached都是廣泛使用的內存數據存儲系統,它們主要用于提高應用程序的性能,通過減少對數據庫的直接訪問來加速數據檢索。以下是對Redi...

從進一步優化數據服務,到引入QLC SSD,再到I/O性能提升、數據縮減能力增強,以及網絡服務、遠程復制與系統管理能力的升級,從性能、效率、彈性到管理…...
1. 數據預處理 在大數據的處理過程中,數據預處理是至關重要的第一步。這包括數據清洗、轉換和歸一化,以確保數據的質量和一致性。 數據清洗 :移除重復記錄...
精準化,是智慧醫療的核心目標之一。通過大數據、人工智能、機器人等先進數字技術與醫療技術的深度融合,使得醫療服務能夠更加精準地滿足患者的需求,從而提高患者...
數據是各種現代企業的生命線,而數據存儲、訪問與管理策略對企業的生產力、盈利能力以及競爭力會產生顯著影響。隨著人工智能(AI)的興起,各行各業都在經歷變革...
近日,中國計算機學會第十三期CCF秀湖會議在蘇州CCF業務總部&學術交流中心正式拉開帷幕。本次會議就“新應用與硬件驅動下的存儲技術創新”主題進行...
在當今這個數據驅動的時代,企業對于數據存儲的需求日益增長。EMC,作為全球領先的數據存儲解決方案提供商,其企業級存儲系統以其卓越的性能、可靠性和創新技術...
 換一批
換一批
編輯推薦廠商產品技術軟件/工具OS/語言教程專題
| 電機控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機 | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機 | PID | MOSFET | 傳感器 | 人工智能 | 物聯網 | NXP | 賽靈思 |
| 步進電機 | SPWM | 充電樁 | IPM | 機器視覺 | 無人機 | 三菱電機 | ST |
| 伺服電機 | SVPWM | 光伏發電 | UPS | AR | 智能電網 | 國民技術 | Microchip |
| 開關電源 | 步進電機 | 無線充電 | LabVIEW | EMC | PLC | OLED | 單片機 |
| 5G | m2m | DSP | MCU | ASIC | CPU | ROM | DRAM |
| NB-IoT | LoRa | Zigbee | NFC | 藍牙 | RFID | Wi-Fi | SIGFOX |
| Type-C | USB | 以太網 | 仿真器 | RISC | RAM | 寄存器 | GPU |
| 語音識別 | 萬用表 | CPLD | 耦合 | 電路仿真 | 電容濾波 | 保護電路 | 看門狗 |
| CAN | CSI | DSI | DVI | Ethernet | HDMI | I2C | RS-485 |
| SDI | nas | DMA | HomeKit | 閾值電壓 | UART | 機器學習 | TensorFlow |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關注我們的微信

下載發燒友APP

電子發燒友觀察

版權所有 ? 湖南華秋數字科技有限公司
長沙市望城經濟技術開發區航空路6號手機智能終端產業園2號廠房3層(0731-88081133)
電子發燒友 (電路圖) 湘公網安備43011202000918 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1