完善資料讓更多小伙伴認(rèn)識你,還能領(lǐng)取20積分哦,立即完善>
標(biāo)簽 > 語言模型
文章:513個 瀏覽:10292次 帖子:3個
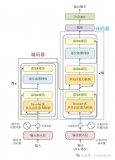
最大的區(qū)別ChatGPT是通過對話數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,而不僅僅是通過單一的句子進(jìn)行預(yù)訓(xùn)練,這使得ChatGPT能夠更好地理解對話的上下文,并進(jìn)行連貫的回復(fù)。
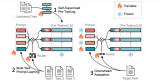
Prompt Tuning 可以讓預(yù)訓(xùn)練的語言模型快速適應(yīng)下游任務(wù)。雖然有研究證明:當(dāng)訓(xùn)練數(shù)據(jù)足夠多的時候,Prompt Tuning 的微調(diào)結(jié)果可以媲...
2023-06-20 標(biāo)簽:模塊數(shù)據(jù)語言模型 701 0

邱錫鵬團(tuán)隊提出具有內(nèi)生跨模態(tài)能力的SpeechGPT,為多模態(tài)LLM指明方向
大型語言模型(LLM)在各種自然語言處理任務(wù)上表現(xiàn)出驚人的能力。與此同時,多模態(tài)大型語言模型,如 GPT-4、PALM-E 和 LLaVA,已經(jīng)探索了 ...
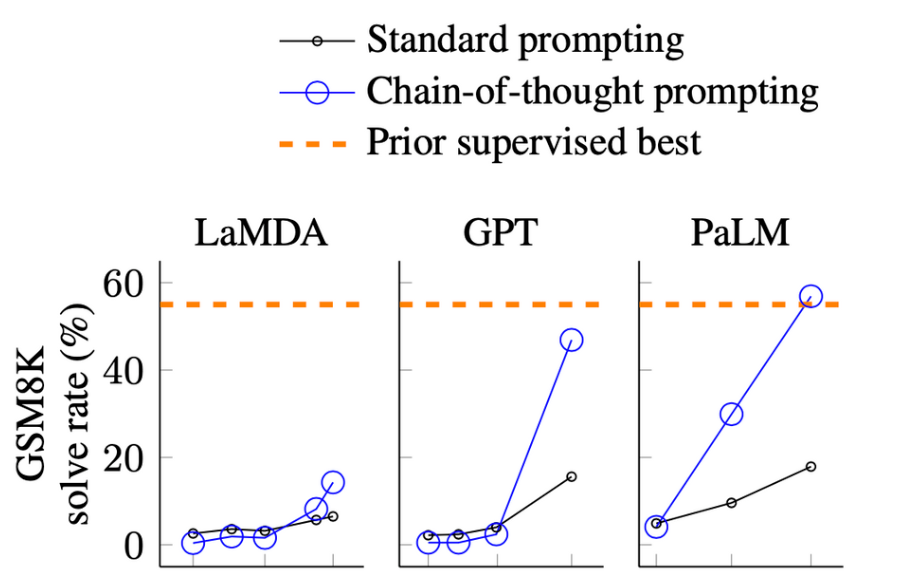
對于先行者來說,范式轉(zhuǎn)變可能是很顯然的。然而,出于科學(xué)的嚴(yán)謹(jǐn)性, 我們確實需要非常明確的理由來說明為什么人們應(yīng)該轉(zhuǎn)向大型語言模型,即使這些模型昂貴、難以...
加利福尼亞州圣克拉拉——Nvidia通過一個名為TensorRT LLM的新開源軟件庫,將其H100、A100和L4 GPU的大型語言模型(LLM)推理...
號稱「碾壓」LLaMA的Falcon實測得分僅49.08,HuggingFace決定重寫排行榜代碼
這是一組由 Meta 開源的大型語言模型,共有 7B、13B、33B、65B 四種版本。其中,LLaMA-13B 在大多數(shù)數(shù)據(jù)集上超過了 GPT-3(1...

爆火Llama 2一周請求下載超15萬,有人開源了Rust實現(xiàn)版本
隨著 Llama 2 的逐漸走紅,大家對它的二次開發(fā)開始流行起來。前幾天,OpenAI 科學(xué)家 Karpathy 利用周末時間開發(fā)了一個明星項目 lla...
基于預(yù)訓(xùn)練語言模型設(shè)計了一套統(tǒng)一的模型架構(gòu)
進(jìn)一步,本文研究了在更依賴 KG 的知識庫問答任務(wù)中如何利用 PLM。已有研究通常割裂地建模檢索-推理兩階段,先從大規(guī)模知識圖譜上檢索問題相關(guān)的小子圖,...
2023-04-07 標(biāo)簽:PLM語言模型數(shù)據(jù)集 665 0

在 2018 年至 2022 年期間,NLP、CV 和通用機(jī)器學(xué)習(xí)領(lǐng)域有大量關(guān)于分布偏移/對抗魯棒性/組合生成的研究,人們發(fā)現(xiàn)當(dāng)測試集分布與訓(xùn)練分布不同...
2023-02-21 標(biāo)簽:語言模型機(jī)器學(xué)習(xí)nlp 665 0

隨著開源預(yù)訓(xùn)練大型語言模型(Large Language Model, LLM )變得更加強(qiáng)大和開放,越來越多的開發(fā)者將大語言模型納入到他們的項目中。其...
2024-01-04 標(biāo)簽:語言模型機(jī)器學(xué)習(xí)LoRa 655 0
最新研究綜述——探索基礎(chǔ)模型中的“幻覺”現(xiàn)象
這種“幻覺”現(xiàn)象可能是無意中產(chǎn)生的,它可以由多種因素導(dǎo)致,包括訓(xùn)練數(shù)據(jù)集中存在的偏見、模型不能獲取最新的信息,或是其在理解和生成準(zhǔn)確回應(yīng)時的固有限制。為...

無監(jiān)督域自適應(yīng)場景:基于檢索增強(qiáng)的情境學(xué)習(xí)實現(xiàn)知識遷移
本文對比了多種基線方法,包括無監(jiān)督域自適應(yīng)的傳統(tǒng)方法(如Pseudo-labeling和對抗訓(xùn)練)、基于檢索的LM方法(如REALM和RAG)和情境學(xué)習(xí)...
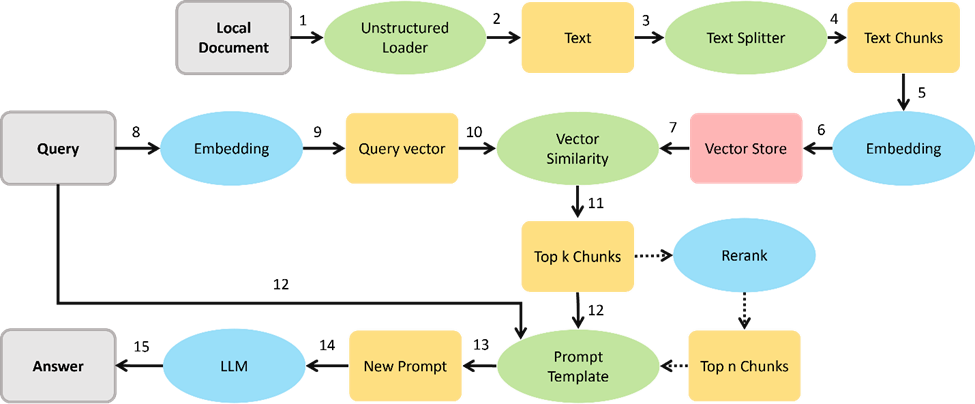
LangChain是一個強(qiáng)大的框架,旨在幫助開發(fā)人員使用語言模型構(gòu)建端到端的應(yīng)用程序。它提供了一套工具、組件和接口,可簡化創(chuàng)建由大型語言模型 (LLM)...
2024-08-30 標(biāo)簽:應(yīng)用程序語言模型LLM 621 0
在本文中,我們將深入探討LLM(Large Language Model,大型語言模型)的應(yīng)用領(lǐng)域。LLM是一種基于深度學(xué)習(xí)的人工智能技術(shù),它能夠理解和...
2024-07-09 標(biāo)簽:模型語言模型深度學(xué)習(xí) 620 0
蒸餾也能Step-by-Step:新方法讓小模型也能媲美2000倍體量大模型
為了解決大型模型的這個問題,部署者往往采用小一些的特定模型來替代。這些小一點的模型用常見范式 —— 微調(diào)或是蒸餾來進(jìn)行訓(xùn)練。微調(diào)使用下游的人類注釋數(shù)據(jù)升...
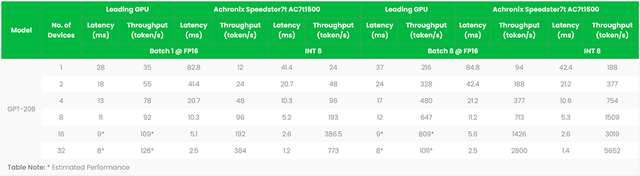
FPGA加速器支撐ChatGPT類大語言模型創(chuàng)新
作者:Bill Jenkins,Achronix人工智能/機(jī)器學(xué)習(xí)產(chǎn)品營銷總監(jiān) 探索FPGA加速語言模型如何通過更快的推理、更低的延遲和更好的語言理解來...
Falcon-7B大型語言模型在心理健康對話數(shù)據(jù)集上使用QLoRA進(jìn)行微調(diào)
使用領(lǐng)域適應(yīng)技術(shù)對預(yù)訓(xùn)練LLM進(jìn)行微調(diào)可以提高在特定領(lǐng)域任務(wù)上的性能。但是,進(jìn)行完全微調(diào)可能會很昂貴,并且可能會導(dǎo)致CUDA內(nèi)存不足錯誤。當(dāng)進(jìn)行完全微調(diào)...
2023-09-19 標(biāo)簽:模型語言模型數(shù)據(jù)集 597 0

基于預(yù)訓(xùn)練模型和語言增強(qiáng)的零樣本視覺學(xué)習(xí)
在一些非自然圖像中要比傳統(tǒng)模型表現(xiàn)更好 CoOp 增加一些 prompt 會讓模型能力進(jìn)一步提升 怎么讓能力更好?可以引入其他知識,即其他的預(yù)訓(xùn)練模型,...
重新審視Prompt優(yōu)化問題,預(yù)測偏差讓語言模型上下文學(xué)習(xí)更強(qiáng)
Prompt tuning 的關(guān)鍵思想是將任務(wù)特定的 embedding 注入隱藏層,然后使用基于梯度的優(yōu)化來調(diào)整這些 embeddings。然而,這些...
2023-04-03 標(biāo)簽:語言模型 571 0
Subword算法如今已經(jīng)成為了一個重要的NLP模型性能提升方法。自從2018年BERT橫空出世橫掃NLP界各大排行榜之后,各路預(yù)訓(xùn)練語言模型如同雨后春...
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語言教程專題
| 電機(jī)控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機(jī) | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機(jī) | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進(jìn)電機(jī) | SPWM | 充電樁 | IPM | 機(jī)器視覺 | 無人機(jī) | 三菱電機(jī) | ST |
| 伺服電機(jī) | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1

