完善資料讓更多小伙伴認識你,還能領取20積分哦,立即完善>
標簽 > SVM
SVM(Support Vector Machine)指的是支持向量機,是常見的一種判別方法。在機器學習領域,是一個有監督的學習模型,通常用來進行模式識別、分類以及回歸分析。
SVM(Support Vector Machine)指的是支持向量機,是常見的一種判別方法。在機器學習領域,是一個有監督的學習模型,通常用來進行模式識別、分類以及回歸分析。
Vapnik等人在多年研究統計學習理論基礎上對線性分類器提出了另一種設計最佳準則。其原理也從線性可分說起,然后擴展到線性不可分的情況。甚至擴展到使用非線性函數中去,這種分類器被稱為支持向量機(Support Vector Machine,簡稱SVM)。支持向量機的提出有很深的理論背景。支持向量機方法是在后來提出的一種新方法。SVM的主要思想可以概括為兩點:
它是針對線性可分情況進行分析,對于線性不可分的情況,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉化為高維特征空間使其線性可分,從而使得高維特征空間采用線性算法對樣本的非線性特征進行線性分析成為可能。
它基于結構風險最小化理論之上在特征空間中構建最優超平面,使得學習器得到全局最優化,并且在整個樣本空間的期望以某個概率滿足一定上界。
SVM(Support Vector Machine)指的是支持向量機,是常見的一種判別方法。在機器學習領域,是一個有監督的學習模型,通常用來進行模式識別、分類以及回歸分析。
Vapnik等人在多年研究統計學習理論基礎上對線性分類器提出了另一種設計最佳準則。其原理也從線性可分說起,然后擴展到線性不可分的情況。甚至擴展到使用非線性函數中去,這種分類器被稱為支持向量機(Support Vector Machine,簡稱SVM)。支持向量機的提出有很深的理論背景。支持向量機方法是在后來提出的一種新方法。SVM的主要思想可以概括為兩點:
它是針對線性可分情況進行分析,對于線性不可分的情況,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉化為高維特征空間使其線性可分,從而使得高維特征空間采用線性算法對樣本的非線性特征進行線性分析成為可能。
它基于結構風險最小化理論之上在特征空間中構建最優超平面,使得學習器得到全局最優化,并且在整個樣本空間的期望以某個概率滿足一定上界。
例子
如右圖:將1維的“線性不可分”上升到2維后就成為線性可分了。⑵它基于結構風險最小化理論之上在特征空間中建構最優分割超平面,使得學習器得到全局最優化,并且在整個樣本空間的期望風險以某個概率滿足一定上界。在學習這種方法時,首先要弄清楚這種方法考慮問題的特點,這就要從線性可分的最簡單情況討論起,在沒有弄懂其原理之前,不要急于學習線性不可分等較復雜的情況,支持向量機在設計時,需要用到條件極值問題的求解,因此需用拉格朗日乘子理論,但對多數人來說,以前學到的或常用的是約束條件為等式表示的方式,但在此要用到以不等式作為必須滿足的條件,此時只要了解拉格朗日理論的有關結論就行。
一般特征
⑴SVM學習問題可以表示為凸優化問題,因此可以利用已知的有效算法發現目標函數的全局最小值。而其他分類方法(如基于規則的分類器和人工神經網絡)都采用一種基于貪心學習的策略來搜索假設空間,這種方法一般只能獲得局部最優解。⑵SVM通過最大化決策邊界的邊緣來控制模型的能力。盡管如此,用戶必須提供其他參數,如使用核函數類型和引入松弛變量等。⑶通過對數據中每個分類屬性引入一個啞變量,SVM可以應用于分類數據。⑷SVM一般只能用在二類問題,對于多類問題效果不好。
原理介紹
SVM方法是通過一個非線性映射p,把樣本空間映射到一個高維乃至無窮維的特征空間中(Hilbert空間),使得在原來的樣本空間中非線性可分的問題轉化為在特征空間中的線性可分的問題.簡單地說,就是升維和線性化.升維,就是把樣本向高維空間做映射,一般情況下這會增加計算的復雜性,甚至會引起“維數災難”,因而人們很少問津.但是作為分類、回歸等問題來說,很可能在低維樣本空間無法線性處理的樣本集,在高維特征空間中卻可以通過一個線性超平面實現線性劃分(或回歸).一般的升維都會帶來計算的復雜化,SVM方法巧妙地解決了這個難題:應用核函數的展開定理,就不需要知道非線性映射的顯式表達式;由于是在高維特征空間中建立線性學習機,所以與線性模型相比,不但幾乎不增加計算的復雜性,而且在某種程度上避免了“維數災難”.這一切要歸功于核函數的展開和計算理論.選擇不同的核函數,可以生成不同的SVM,常用的核函數有以下4種:⑴線性核函數K(x,y)=x·y;⑵多項式核函數K(x,y)=[(x·y)+1]^d;⑶徑向基函數K(x,y)=exp(-|x-y|^2/d^2)⑷二層神經網絡核函數K(x,y)=tanh(a(x·y)+b).
應用
SVM可用于解決各種現實世界的問題:
支持向量機有助于文本和超文本分類,因為它們的應用程序可以顯著減少對標準感應和轉換設置中標記的訓練實例的需求。
圖像的分類也可以使用SVM進行。實驗結果表明,只有三到四輪的相關性反饋,支持向量機的搜索精度要比傳統的查詢優化方案高得多。圖像分割系統也是如此,包括使用Vapnik建議的使用特權方法的修改版SVM的系統。
使用SVM可以識別手寫字符。
SVM算法已廣泛應用于生物科學和其他科學領域。它們已被用于對高達90%正確分類的化合物進行蛋白質分類。已經提出基于SVM權重的置換測試作為解釋SVM模型的機制。支持向量機權重也被用于解釋過去的SVM模型。Posthoc解釋支持向量機模型為了識別模型使用的特征進行預測是一個比較新的研究領域,在生物科學中具有特殊的意義。
手把手教你實現SVM算法
機器學習是研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。它是人工智能的核心,是使計算機具有智能的根本途徑,其應用遍及人工智能的各個領域。
機器學習的大致分類:
1)分類(模式識別):要求系統依據已知的分類知識對輸入的未知模式(該模式的描述)作分析,以確定輸入模式的類屬,例如手寫識別(識別是不是這個數)。
2)問題求解:要求對于給定的目標狀態,尋找一個將當前狀態轉換為目標狀態的動作序列。
SVM一般是用來分類的(一般先分為兩類,再向多類推廣一生二,二生三,三生萬物哈)
問題的描述
向量表示:假設一個樣本有n個變量(特征):Ⅹ= (X1,X2,…,Xn)T
樣本表示方法:
SVM線性分類器
SVM從線性可分情況下的最優分類面發展而來。最優分類面就是要求分類線不但能將兩類正確分開(訓練錯誤率為0),且使分類間隔最大。SVM考慮尋找一個滿足分類要求的超平面,并且使訓練集中的點距離分類面盡可能的遠,也就是尋找一個分類面使它兩側的空白區域(margin)最大。
過兩類樣本中離分類面最近的點且平行于最優分類面的超平面上H1,H2的訓練樣本就叫做支持向量。
圖例:
問題描述:
假定訓練數據 :![]()
可以被分為一個超平面:![]()
進行歸一化:![]()
此時分類間隔等于:![]()
即使得:最大間隔最大等價于使![]() 最小
最小
下面這兩張圖可以看一下,有個感性的認識。那個好?
看下面這張圖:
下面我們要開始優化上面的式子,因為推導要用到拉格朗日定理和KKT條件,所以我們先了解一下相關知識。在求取有約束條件的優化問題時,拉格朗日乘子法(Lagrange Multiplier) 和KKT條件是非常重要的兩個求取方法,對于等式約束的優化問題,可以應用拉格朗日乘子法去求取最優值;如果含有不等式約束,可以應用KKT條件去求取。當然,這兩個方法求得的結果只是必要條件,只有當是凸函數的情況下,才能保證是充分必要條件。KKT條件是拉格朗日乘子法的泛化。之前學習的時候,只知道直接應用兩個方法,但是卻不知道為什么拉格朗日乘子法(Lagrange Multiplier) 和KKT條件能夠起作用,為什么要這樣去求取最優值呢?
拉格朗日乘子法和KKT條件
定義:給定一個最優化問題:
最小化目標函數:![]()
制約條件:![]()
定義拉格朗日函數為:
求偏倒方程
可以求得![]() 的值。這個就是神器拉格朗日乘子法。
的值。這個就是神器拉格朗日乘子法。
上面的拉格朗日乘子法還不足以幫我們解決所有的問題,下面引入不等式約束
最小化目標函數:![]()
制約條件變為:
定義拉格朗日函數為:
可以列出方程:
新增加的條件被稱為KKT條件
KKT條件詳解
對于含有不等式約束的優化問題,如何求取最優值呢?常用的方法是KKT條件,同樣地,把所有的不等式約束、等式約束和目標函數全部寫為一個式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT條件是說最優值必須滿足以下條件:
1. L(a, b, x)對x求導為零;
2. h(x) =0;
3. a*g(x) = 0;
求取這三個等式之后就能得到候選最優值。其中第三個式子非常有趣,因為g(x)《=0,如果要滿足這個等式,必須a=0或者g(x)=0. 這是SVM的很多重要性質的來源,如支持向量的概念。
二。 為什么拉格朗日乘子法(Lagrange Multiplier) 和KKT條件能夠得到最優值?
為什么要這么求能得到最優值?先說拉格朗日乘子法,設想我們的目標函數z = f(x), x是向量, z取不同的值,相當于可以投影在x構成的平面(曲面)上,即成為等高線,如下圖,目標函數是f(x, y),這里x是標量,虛線是等高線,現在假設我們的約束g(x)=0,x是向量,在x構成的平面或者曲面上是一條曲線,假設g(x)與等高線相交,交點就是同時滿足等式約束條件和目標函數的可行域的值,但肯定不是最優值,因為相交意味著肯定還存在其它的等高線在該條等高線的內部或者外部,使得新的等高線與目標函數的交點的值更大或者更小,只有到等高線與目標函數的曲線相切的時候,可能取得最優值,如下圖所示,即等高線和目標函數的曲線在該點的法向量必須有相同方向,所以最優值必須滿足:f(x)的梯度 = a* g(x)的梯度,a是常數,表示左右兩邊同向。這個等式就是L(a,x)對參數求導的結果。(上述描述,我不知道描述清楚沒,如果與我物理位置很近的話,直接找我,我當面講好理解一些,注:下圖來自wiki)。
而KKT條件是滿足強對偶條件的優化問題的必要條件,可以這樣理解:我們要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a》=0,我們可以把f(x)寫為:max_{a,b} L(a,b,x),為什么呢?因為h(x)=0, g(x)《=0,現在是取L(a,b,x)的最大值,a*g(x)是《=0,所以L(a,b,x)只有在a*g(x) = 0的情況下才能取得最大值,否則,就不滿足約束條件,因此max_{a,b} L(a,b,x)在滿足約束條件的情況下就是f(x),因此我們的目標函數可以寫為 min_x max_{a,b} L(a,b,x)。如果用對偶表達式: max_{a,b} min_x L(a,b,x),由于我們的優化是滿足強對偶的(強對偶就是說對偶式子的最優值是等于原問題的最優值的),所以在取得最優值x0的條件下,它滿足 f(x0) = max_{a,b} min_x L(a,b,x) = min_x max_{a,b} L(a,b,x) =f(x0),我們來看看中間兩個式子發生了什么事情:
f(x0) = max_{a,b} min_x L(a,b,x) = max_{a,b} min_x f(x) + a*g(x) + b*h(x) = max_{a,b} f(x0)+a*g(x0)+b*h(x0) = f(x0)
可以看到上述加黑的地方本質上是說 min_x f(x) + a*g(x) + b*h(x) 在x0取得了最小值,用Fermat定理,即是說對于函數 f(x) + a*g(x) + b*h(x),求取導數要等于零,即
f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
這就是KKT條件中第一個條件:L(a, b, x)對x求導為零。
而之前說明過,a*g(x) = 0,這時KKT條件的第3個條件,當然已知的條件h(x)=0必須被滿足,所有上述說明,滿足強對偶條件的優化問題的最優值都必須滿足KKT條件,即上述說明的三個條件。可以把KKT條件視為是拉格朗日乘子法的泛化。
上面跑題了,下面我繼續我們的SVM之旅。
經過拉格朗日乘子法和KKT條件推導之后
最終問題轉化為:
最大化:![]()
條件:
這個是著名的QP問題。決策面:![]() 其中
其中 ![]() 為問題的優化解。
為問題的優化解。
松弛變量(slack vaviable)
由于在采集數據的過程中,也可能有誤差(如圖)
所以我們引入松弛變量對問題進行優化。
![]() 式子就變為
式子就變為![]()
最終轉化為下面的優化問題:
其中的C是懲罰因子,是一個由用戶去指定的系數,表示對分錯的點加入多少的懲罰,當C很大的時候,分錯的點就會更少,但是過擬合的情況可能會比較嚴重,當C很小的時候,分錯的點可能會很多,不過可能由此得到的模型也會不太正確。
上面那個個式子看似復雜,現在我帶大家一起推倒一下
……
…(草稿紙上,敲公式太煩人了)
最終得到:
最大化:
條件:
呵呵,是不是感覺和前面的式子沒啥區別內,親,數學就是這么美妙啊。
這個式子看起來beautiful,但是多數情況下只能解決線性可分的情況,只可以對線性可分的樣本做處理。如果提供的樣本線性不可分,結果很簡單,線性分類器的求解程序會無限循環,永遠也解不出來。但是不怕不怕。我們有殺手锏還沒有出呢。接著咱要延伸到一個新的領域:核函數。嘻嘻,相信大家都應該聽過這廝的大名,這個東東在60年代就提出來,可是直到90年代才開始火起來(第二春哈),主要是被Vapnik大大翻出來了。這也說明計算機也要多研讀經典哈,不是說過時了就不看的,有些大師的論文還是有啟發意義的。廢話不多說,又跑題了。
核函數
那到底神馬是核函數呢?
介個咱得先介紹一下VC維的概念。
為了研究經驗風險最小化函數集的學習一致收斂速度和推廣性,SLT定義了一些指標來衡量函數集的性能,其中最重要的就是VC維(Vapnik-Chervonenkis Dimension)。
VC維定義:對于一個指示函數(即只有0和1兩種取值的函數)集,如果存在h個樣本能夠被函數集里的函數按照所有可能的2h種形式分開,則稱函數集能夠把h個樣本打散,函數集的VC維就是能夠打散的最大樣本數目。
如果對任意的樣本數,總有函數能打散它們,則函數集的VC維就是無窮大。
看圖比較方便(三個點分類,線性都可分的)。
如果四個點呢?哈哈,右邊的四個點要分為兩個類,可能就分不啦。
如果四個點,一條線可能就分不過來啦。
一般而言,VC維越大, 學習能力就越強,但學習機器也越復雜。
目前還沒有通用的關于計算任意函數集的VC維的理論,只有對一些特殊函數集的VC維可以準確知道。
N維實數空間中線性分類器和線性實函數的VC維是n+1。
Sin(ax)的VC維為無窮大。
對于給定的學習函數集,如何計算其VC維是當前統計學習理論研究中有待解決的一個難點問題,各位童鞋有興趣可以去研究研究。
咱們接著要說說為啥要映射。
例子是下面這張圖:
下面這段來自百度文庫http://wenku.baidu.com/view/8c17ebda5022aaea998f0fa8.html
俺覺得寫的肯定比我好,所以咱就選擇站在巨人的肩膀上啦。
我們把橫軸上端點a和b之間紅色部分里的所有點定為正類,兩邊的黑色部分里的點定為負類。試問能找到一個線性函數把兩類正確分開么?不能,因為二維空間里的線性函數就是指直線,顯然找不到符合條件的直線。
但我們可以找到一條曲線,例如下面這一條:
顯然通過點在這條曲線的上方還是下方就可以判斷點所屬的類別(你在橫軸上隨便找一點,算算這一點的函數值,會發現負類的點函數值一定比0大,而正類的一定比0小)。這條曲線就是我們熟知的二次曲線,它的函數表達式可以寫為:
問題只是它不是一個線性函數,但是,下面要注意看了,新建一個向量y和a:
這樣g(x)就可以轉化為f(y)=《a,y》,你可以把y和a分別回帶一下,看看等不等于原來的g(x)。用內積的形式寫你可能看不太清楚,實際上f(y)的形式就是:
g(x)=f(y)=ay
在任意維度的空間中,這種形式的函數都是一個線性函數(只不過其中的a和y都是多維向量罷了),因為自變量y的次數不大于1。
看出妙在哪了么?原來在二維空間中一個線性不可分的問題,映射到四維空間后,變成了線性可分的!因此這也形成了我們最初想解決線性不可分問題的基本思路——向高維空間轉化,使其變得線性可分。
而轉化最關鍵的部分就在于找到x到y的映射方法。遺憾的是,如何找到這個映射,沒有系統性的方法(也就是說,純靠猜和湊)。具體到我們的文本分類問題,文本被表示為上千維的向量,即使維數已經如此之高,也常常是線性不可分的,還要向更高的空間轉化。其中的難度可想而知。
為什么說f(y)=ay是四維空間里的函數?
大家可能一時沒看明白。回想一下我們二維空間里的函數定義
g(x)=ax+b
變量x是一維的,為什么說它是二維空間里的函數呢?因為還有一個變量我們沒寫出來,它的完整形式其實是
y=g(x)=ax+b
即
y=ax+b
看看,有幾個變量?兩個。那是幾維空間的函數?
再看看
f(y)=ay
里面的y是三維的變量,那f(y)是幾維空間里的函數?
用一個具體文本分類的例子來看看這種向高維空間映射從而分類的方法如何運作,想象一下,我們文本分類問題的原始空間是1000維的(即每個要被分類的文檔被表示為一個1000維的向量),在這個維度上問題是線性不可分的。現在我們有一個2000維空間里的線性函數
f(x’)=《w’,x’》+b
注意向量的右上角有個 ’哦。它能夠將原問題變得可分。式中的 w’和x’都是2000維的向量,只不過w’是定值,而x’是變量(好吧,嚴格說來這個函數是2001維的,哈哈),現在我們的輸入呢,是一個1000維的向量x,分類的過程是先把x變換為2000維的向量x’,然后求這個變換后的向量x’與向量w’的內積,再把這個內積的值和b相加,就得到了結果,看結果大于閾值還是小于閾值就得到了分類結果。
你發現了什么?我們其實只關心那個高維空間里內積的值,那個值算出來了,分類結果就算出來了。而從理論上說, x’是經由x變換來的,因此廣義上可以把它叫做x的函數(有一個x,就確定了一個x’,對吧,確定不出第二個),而w’是常量,它是一個低維空間里的常量w經過變換得到的,所以給了一個w 和x的值,就有一個確定的f(x’)值與其對應。這讓我們幻想,是否能有這樣一種函數K(w,x),他接受低維空間的輸入值,卻能算出高維空間的內積值《w’,x’》?
如果有這樣的函數,那么當給了一個低維空間的輸入x以后,
g(x)=K(w,x)+b
f(x’)=《w’,x’》+b
這兩個函數的計算結果就完全一樣,我們也就用不著費力找那個映射關系,直接拿低維的輸入往g(x)里面代就可以了(再次提醒,這回的g(x)就不是線性函數啦,因為你不能保證K(w,x)這個表達式里的x次數不高于1哦)。
萬幸的是,這樣的K(w,x)確實存在(發現凡是我們人類能解決的問題,大都是巧得不能再巧,特殊得不能再特殊的問題,總是恰好有些能投機取巧的地方才能解決,由此感到人類的渺小),它被稱作核函數(核,kernel),而且還不止一個,事實上,只要是滿足了Mercer條件的函數,都可以作為核函數。核函數的基本作用就是接受兩個低維空間里的向量,能夠計算出經過某個變換后在高維空間里的向量內積值。幾個比較常用的核函數,俄,教課書里都列過,我就不敲了(懶!)。
回想我們上節說的求一個線性分類器,它的形式應該是:
現在這個就是高維空間里的線性函數(為了區別低維和高維空間里的函數和向量,我改了函數的名字,并且給w和x都加上了 ’),我們就可以用一個低維空間里的函數(再一次的,這個低維空間里的函數就不再是線性的啦)來代替,
又發現什么了?f(x’) 和g(x)里的α,y,b全都是一樣一樣的!這就是說,盡管給的問題是線性不可分的,但是我們就硬當它是線性問題來求解,只不過求解過程中,凡是要求內積的時候就用你選定的核函數來算。這樣求出來的α再和你選定的核函數一組合,就得到分類器啦!
明白了以上這些,會自然的問接下來兩個問題:
1. 既然有很多的核函數,針對具體問題該怎么選擇?
2. 如果使用核函數向高維空間映射后,問題仍然是線性不可分的,那怎么辦?
第一個問題現在就可以回答你:對核函數的選擇,現在還缺乏指導原則!各種實驗的觀察結果(不光是文本分類)的確表明,某些問題用某些核函數效果很好,用另一些就很差,但是一般來講,徑向基核函數是不會出太大偏差的一種,首選。(我做文本分類系統的時候,使用徑向基核函數,沒有參數調優的情況下,絕大部分類別的準確和召回都在85%以上。
感性理解,映射圖:
常用的兩個Kernel函數:
多項式核函數:![]()
高斯核函數:![]()
定義:![]()
將核函數帶入,問題又轉化為線性問題啦,如下:
求![]() ,其中
,其中![]()
式子是有了,但是如何求結果呢?不急不急,我會帶著大家一步一步的解決這個問題,并且通過動手編程使大家對這個有個問題有個直觀的認識。(PS:大家都對LIBSVM太依賴了,這樣無助于深入的研究與理解,而且我覺得自己動手實現的話會比較有成就感)

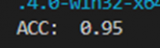
同時根據測試精度,可以看出,通過添加第一次訓練多得到的支持向量,而非將全體數據進行二次訓練,能夠達到同樣的效果。

之前為大家帶來了兩篇關于SVM的介紹與基于python的使用方法。相信大家都已經上手體驗,嘗鮮了鳶尾花數據集了吧。

面部識別是一個經常討論的計算機科學話題,并且由于計算機處理能力的指數級增長而成為人們高度關注的話題。

說到機器學習,大相信大家自然而然想到的就是現在大熱的卷積神經網絡,或者換句話來說,深度學習網絡。對于這些網絡或者模型來說,能夠大大降低進入門檻,具體而言...
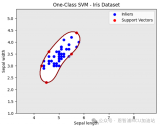
上一篇本著回歸傳統的觀點,在這個深度學習繁榮發展的時期,帶著大家認識了一位新朋友,英文名SVM,中文名為支持向量機,是一種基于傳統方案的機器學習方案,同...
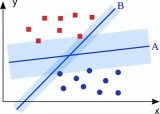
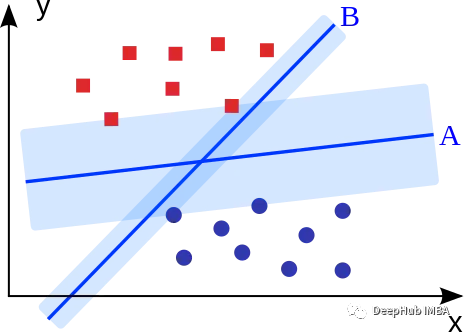
支持向量機的目標是擬合獲得最大邊緣的超平面(兩個類中最近點的距離)。可以直觀地表明,這樣的超平面(A)比沒有最大化邊際的超平面(B)具有更好的泛化特性和...
可穿戴傳感器可將人體各種生理信號轉換為可直接觀測的電信號,為了解人體健康提供豐富的信息,有望為人體實時活動、健康狀況提供預測平臺。
本文將首先簡要概述支持向量機及其訓練和推理方程,然后將其轉換為代碼以開發支持向量機模型。

這篇文章將介紹一種新的調制方法,空間矢量調制 (Space Vector Modulation),簡稱 SVM。
在機器學習中,機器學習的效率在很大程度上取決于它所提供的數據集,數據集的大小和豐富程度也決定了最終預測的結果質量。目前在算力方面,量子計算能超越傳統二進...
類別:模型|Macromodel 2021-04-26 標簽:算法SVM模型
4、結果分析 4.3 不同分類方法比較與分析 4.3.1基于SVM方法的分類結果比較 在不同SVM分類方法中,由于其所采用的分類模型和輸入特征差異影響,...

細胞變形性(Cellular deformability)是醫學上評價細胞生理狀態的一種很有前景的生物標志物。
類皮膚柔性傳感器在醫療保健和人機交互中發揮著至關重要的作用。然而,一般目標集中在追求類皮膚傳感器本身固有的靜態和動態性能,同時伴隨著各種試錯嘗試。這種前...
河南作為小麥玉米的主要產糧區,對小麥玉米方面的研究頗為深入。針對小麥灌漿期易受天氣等因素影響,造成小麥倒伏的情況,需快速準確評估作物倒伏災情狀況,需及時...
什么叫AI計算?AI計算力是什么? 隨著科技的不斷發展,人工智能(AI)已經成為當今最熱門的技術之一。而在人工智能中,AI計算是非常重要的一環。那么,什...
機器學習算法總結 機器學習算法是什么?機器學習算法優缺點? 機器學習算法總結 機器學習算法是一種能夠從數據中自動學習的算法。它能夠從訓練數據中學習特征,...

微塑料污染已成為全球關注的問題,據估計,海洋上層約有24.4萬億個微塑料碎片,這突顯了這種污染物在海洋環境中的廣泛存在。
簡介 支持向量機基本上是最好的有監督學習算法了。最開始接觸SVM是去年暑假的時候,老師要求交《統計學習理論》的報告,那時去網上下了一份入門教程,里面講的...
【編者按】這是一篇關于機器學習工具包Scikit-learn的入門級讀物。對于程序員來說,機器學習的重要性毋庸贅言。也許你還沒有開始,也許曾經失敗過,都...
很多開發者說自從有了 Python/Pandas,Excel 都不怎么用了,用它來處理與可視化表格非常快速。但是這樣還是有一大缺陷,操作不是可視化的表格...
 換一批
換一批
編輯推薦廠商產品技術軟件/工具OS/語言教程專題 教程专题
| 電機控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機 | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機 | PID | MOSFET | 傳感器 | 人工智能 | 物聯網 | NXP | 賽靈思 |
| 步進電機 | SPWM | 充電樁 | IPM | 機器視覺 | 無人機 | 三菱電機 | ST |
| 伺服電機 | SVPWM | 光伏發電 | UPS | AR | 智能電網 | 國民技術 | Microchip |
| 開關電源 | 步進電機 | 無線充電 | LabVIEW | EMC | PLC | OLED | 單片機 |
| 5G | m2m | DSP | MCU | ASIC | CPU | ROM | DRAM |
| NB-IoT | LoRa | Zigbee | NFC | 藍牙 | RFID | Wi-Fi | SIGFOX |
| Type-C | USB | 以太網 | 仿真器 | RISC | RAM | 寄存器 | GPU |
| 語音識別 | 萬用表 | CPLD | 耦合 | 電路仿真 | 電容濾波 | 保護電路 | 看門狗 |
| CAN | CSI | DSI | DVI | Ethernet | HDMI | I2C | RS-485 |
| SDI | nas | DMA | HomeKit | 閾值電壓 | UART | 機器學習 | TensorFlow |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關注我們的微信

下載發燒友APP

電子發燒友觀察

版權所有 ? 湖南華秋數字科技有限公司
長沙市望城經濟技術開發區航空路6號手機智能終端產業園2號廠房3層(0731-88081133)
電子發燒友 (電路圖) 湘公網安備43011202000918 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1


