完善資料讓更多小伙伴認(rèn)識(shí)你,還能領(lǐng)取20積分哦,立即完善>
標(biāo)簽 > cuda
文章:97個(gè) 瀏覽:13641次 帖子:19個(gè)
使用 Python 和 NumPy 庫(kù)開(kāi)發(fā)的 HIM 模型在 hackathon 開(kāi)始時(shí)沒(méi)有并行或 GPU 計(jì)算。在活動(dòng)期間, THINKLAB 團(tuán)...

CUDA核心(Compute Unified Device Architecture Core)是NVIDIA圖形處理器(GPU)上的計(jì)算單元,用于執(zhí)行...
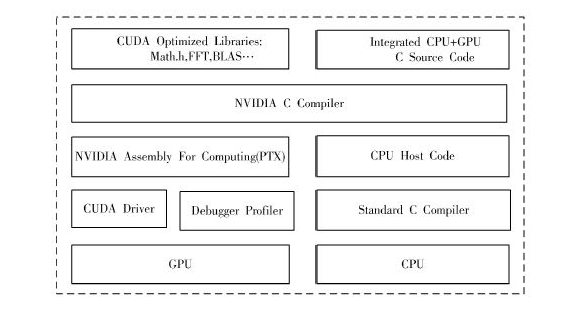
基于CUDA技術(shù)的視頻顯示系統(tǒng)設(shè)計(jì)方案
NVIDIA 推出的CUDA(計(jì)算統(tǒng)一設(shè)備架構(gòu))是基于GPU 進(jìn)行通用計(jì)算的開(kāi)發(fā)平臺(tái),非常適合大規(guī)模的并行數(shù)據(jù)計(jì)算。在GPU 流處理器架構(gòu)下用CUDA ...

這篇文章描述了兩種不同的加速矩陣乘法的方法。第一種方法使用 Numba 編譯器來(lái)減少 Python 代碼中與循環(huán)相關(guān)的開(kāi)銷。第二種方法使用 CUDA...

英偉達(dá)三大AI法寶:CUDA、Nvlink、InfiniBand
以太網(wǎng)是一種廣泛使用的網(wǎng)絡(luò)協(xié)議,但其傳輸速率和延遲無(wú)法滿足大型模型訓(xùn)練的需求。相比之下,端到端IB(InfiniBand)網(wǎng)絡(luò)是一種高性能計(jì)算網(wǎng)絡(luò),能夠...
最近在做OpenCV相關(guān)的項(xiàng)目時(shí)發(fā)現(xiàn),在跑dnn模型時(shí)如果單純只使用cpu幀率會(huì)非常低,有時(shí)甚至一兩秒才刷一幀的圖像出來(lái),需要使用硬件加速,所以在各大論...
OpenCV4.x中關(guān)于CUDA加速的內(nèi)容主要有兩個(gè)部分,第一部分是之前OpenCV支持的圖像處理與對(duì)象檢測(cè)傳統(tǒng)算法的CUDA加速;第二部分是OpenC...
本章說(shuō)明 Python API 的基本用法,假設(shè)您從 ONNX 模型開(kāi)始。?onnx_resnet50.py示例更詳細(xì)地說(shuō)明了這個(gè)用例。
使用VS2022對(duì)GPU進(jìn)行CUDA編程
在異構(gòu)計(jì)算架構(gòu)中,GPU與CPU通過(guò)PCIe總線連接在一起來(lái)協(xié)同工作,CPU所在位置稱為為主機(jī)端(host),而GPU所在位置稱為設(shè)備端(device)...
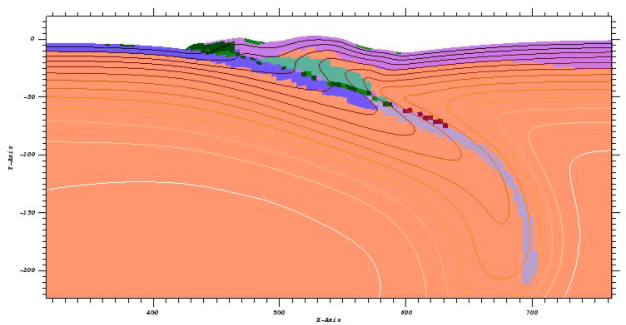
采用空位標(biāo)記的方法對(duì)計(jì)算模式進(jìn)行構(gòu)建與切換,結(jié)合數(shù)據(jù)緩沖機(jī)制和計(jì)算任務(wù)加載方式,設(shè)計(jì)了眾核多計(jì)算模式處理系統(tǒng),實(shí)現(xiàn)了眾核處理機(jī)多模式計(jì)算的功能。##在統(tǒng)...
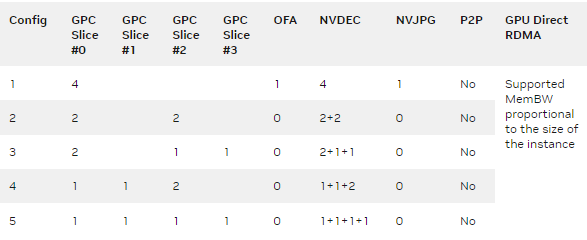
分割NVIDIA A30 GPU并征服多個(gè)工作負(fù)載
多實(shí)例 GPU ( MIG )是 NVIDIA H100 , A100 和 A30 張量核 GPU ,因?yàn)樗梢詫?GPU 劃分為多個(gè)實(shí)例。每個(gè)實(shí)例...
SIMATIC S7- 300 有2種類型的計(jì)數(shù)器,一個(gè)是COUNTER類型,另一個(gè)是IEC_TC類型。
2023-01-29 標(biāo)簽:計(jì)數(shù)器定時(shí)器BCD 3483 0

LayerNorm/RMSNorm的重計(jì)算實(shí)現(xiàn)
我去實(shí)測(cè)了一下,單機(jī)8卡A100訓(xùn)練LLama7B,純數(shù)據(jù)并行的情況下打開(kāi)memory_efficient開(kāi)關(guān)相比于不打開(kāi)節(jié)省了大約2個(gè)G的顯存,如果模...

OpenCV+CUDA編譯實(shí)現(xiàn)YOLOv5能加速
對(duì)比一下,加速效果真得是杠杠滴!所以值得編譯OpenCV+CUDA支持,因?yàn)樗还饧铀偕疃葘W(xué)習(xí)模型推理,對(duì)傳統(tǒng)圖像處理均有加速!
CUDA是NVIDIA的一種用于GPU編程的技術(shù),CUDA核心是GPU上的一組小型計(jì)算單元,它們可以同時(shí)執(zhí)行大量的計(jì)算任務(wù)。
2023-01-08 標(biāo)簽:gpuNVIDIA技術(shù)CUDA 2546 0
llama.cpp代碼結(jié)構(gòu)&調(diào)用流程分析
llama.cpp 的代碼結(jié)構(gòu)比較直觀,如下所示,為整體代碼結(jié)構(gòu)中的比較核心的部分的代碼結(jié)構(gòu)

GPU平臺(tái)生態(tài):英偉達(dá)CUDA和AMD ROCm對(duì)比分析
成熟且完善的平臺(tái)生態(tài)是 GPU 廠商的護(hù)城河。相較于持續(xù)迭代的微架構(gòu)帶來(lái)的技術(shù)壁壘硬實(shí)力,成熟的軟件生態(tài)形成的強(qiáng)大用戶粘性將在長(zhǎng)時(shí)間內(nèi)塑造 GPU廠商的...
無(wú)需實(shí)例或類級(jí)別3D模型的對(duì)新穎物體的6D姿態(tài)追蹤
跟蹤RGBD視頻中物體的6D姿態(tài)對(duì)機(jī)器人操作很重要。然而,大多數(shù)先前的工作通常假設(shè)目標(biāo)對(duì)象的CAD 模型,至少類別級(jí)別,可用于離線訓(xùn)練或在線測(cè)試階段模板匹配。
單精度矩陣乘法(SGEMM)幾乎是每一位學(xué)習(xí) CUDA 的同學(xué)繞不開(kāi)的案例,這個(gè)經(jīng)典的計(jì)算密集型案例可以很好地展示 GPU 編程中常用的優(yōu)化技巧。本文將...
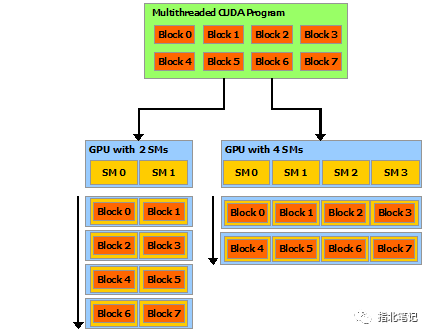
CUDA 編程模型主要有三個(gè)關(guān)鍵抽象:層級(jí)的線程組,共享內(nèi)存和柵同步(barrier synchronization)。
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語(yǔ)言教程專題
| 電機(jī)控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動(dòng)駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無(wú)刷電機(jī) | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機(jī) | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進(jìn)電機(jī) | SPWM | 充電樁 | IPM | 機(jī)器視覺(jué) | 無(wú)人機(jī) | 三菱電機(jī) | ST |
| 伺服電機(jī) | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國(guó)民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹(shù)莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1

