 電子發燒友App
電子發燒友App


引 言
由于成本和視頻通信質量的因素,可視電話從推出到現在,一直受到用戶的冷落。現在因為技術的進步和寬帶因特網的普及,可視電話呈現出新的生機。業內專家預測,未來幾年內,可視電話不僅可與電信固話、小靈通、移動/聯通手機互聯,還可與3G 手機互通。可視電話將成為獨立的產業,發展前景良好。
筆者基于TI公司的單顆600 MHz TMS320DM643(簡稱為DM643)數字媒體處理器,開發了一套性能優異、價格低廉的嵌入式IP可視電話,實現點對點網絡音視頻實時通信。
1 基于TMS320DM643的硬件設計
DM643數字媒體處理器[1]集成了一系列外設,以適應視頻和影像技術的發展。其中包括3個可配置視頻端口,1個10/100 Mbps的以太網MAC(EMAC),1個面向音頻應用的串行口(McASP),1個串行口(McBSP)以及一些其他外設。C64x核內有8個并行的處理單元,采用VLIW(甚長指令集)結構,處理能力高達4800MIPS,并在C6OOO公共指令集的基礎上擴展了88條指令。這些指令使C64x能夠更方便地執行圖象處理中的算法。
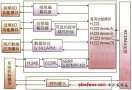
基于單顆DM643的嵌入式IP可視電話的組成如圖1所示。從攝像機輸入的視頻信號和從麥克風輸入的音頻信號經A/D轉換后送入DSP,DSP對音/視頻信號進行壓縮、編碼、合流;然后通過局域網或因特網將數據傳輸出去,同時將從網絡上接收的數據分流,并分別進行視頻信號的解碼顯示和音頻信號的解碼播放。系統中,還通過DM643的McBSP/UART 口外接了一個鍵盤,以實現電話的撥號功能。
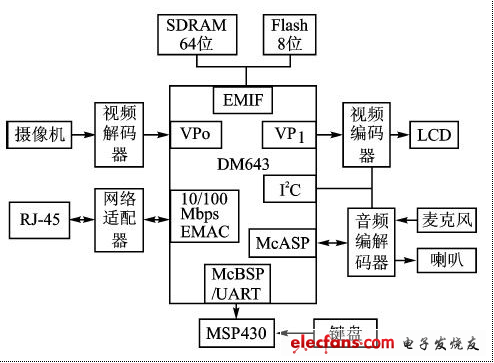
圖1:嵌入式IP可視電話的組成
1.1 視頻采集電路
本系統采用的視頻解碼芯片是Philips公司的SAA7l15.從攝像機輸入的全電視信號在SAA7l15內部經過鉗位、抗混疊濾波、A/D轉換、YuV分離電路之后,在YuV到YCrCb的轉換電路中轉換成BT.656視頻數據流,通過DM643的視頻口VPo輸入到壓縮核心單元DM643中。視頻數據的行/場同步信號包含在BT.656數字視頻數據流的EAV(End of Active Video)和SAV(Startof Active Video)時基信號中,視頻口只需視頻采樣時鐘和采樣使能信號。SAA7l15內部寄存器參數的配置和狀態的讀出通過1 C總線進行。視頻采集接口的原理如圖2所示。
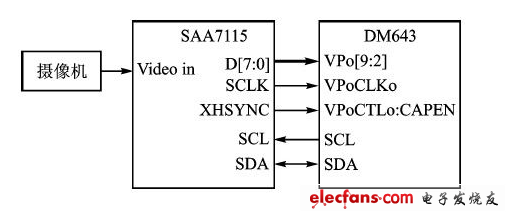
圖2:視頻采集口原理
DM643將解碼后的視頻數據通過視頻口VP1通道送給SAA7121顯示輸出。SAA7121是Philips公司的一款視頻編碼芯片,可實現數字視頻的D/A 變換。SAA7121的工作模式由其內部的控制寄存器決定,控制寄存器的初始化通過1 C總線完成。DM643利用自身具有的1 C總線模塊,作為主控制器,對SAA7121進行參數編程控制。
1.3 音頻輸入/輸出電路
本系統采用TI的高性能立體聲編/解碼器TI V320AIC23(簡稱AIC23),實現音頻信號的采集和播放。AIC23與DM643的I/0電壓兼容,可實現與DM643的McASP接口無縫連接。
在本系統中,AIC23工作于主模式,左右聲道的采樣字寬均為16位。數據接口為DSP mode模式。通過12 C總線設置內部寄存器的工作參數和反饋狀態信息。
由于網絡傳輸的固有特點,音頻數據和視頻數據傳輸到接收方時不可能是均勻的。如果發送方不作任何糾正處理,則很難保證音/視頻的同步輸出。為了實現音頻和視頻的采樣同步,利用鎖相環PI I 1708.從SAA7115的U C引腳輸出27 MHz時鐘,經PLI 1708的SCKO 3引腳輸出默認時鐘頻率18.433 MHz,作為AIC23的輸入主時鐘MCI K.AIC23內部采用的時鐘可通過設置寄存器由主時鐘MCLK分頻得到。由于音視頻采樣信號采用同一個時鐘源,因此不會出現音/視頻不同步的問題。
1.4 以太網接口電路
本系統用LXT971作為快速以太網物理層自適應收發器。LXT971支持IEEE 802.3標準,提供MII(MediaIndependent Interface)接口,可以支持MAC;而DM643內部正好集成有MAC控制器,所以LXT971可與DM643實現無縫連接。連接電路如圖3所示,其中BH1102為1:1的隔離變壓器。
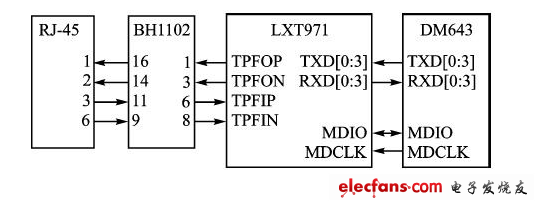
圖3:網絡接口原理
1.5 存儲器擴展電路
DM643通過EMIF接口擴展了2片32 MB的SDRAM來存放原始圖像數據,1片4 MB的Flash來存放應用程序。二者都映射到DM643的外部數據空間。
2 軟件實現和優化
在本系統中,視頻編/解碼算法采用H.264標準[2],音頻編解碼算法采用G.723.1a,回音消除采用G.167,媒體協議采用RTP/RTCP,網絡協議采用TCP/UDP/IP,通信協議采用H.323v.4;另外還軟件實現了靜音、電話功能,并運用抖動緩沖媒體同步技術實現了各種網絡狀況下的音唇一致。操作系統采用基于DSP/B10S的TI參考架構5(RF5)。基于RF5操作系統的應用程序模塊主要包括:音/視頻采集模塊、音/視頻編解碼模塊、UART控制模塊和網絡傳輸模塊。
本系統采用的H.264編/解碼可大大提高圖像質量或降低像通信帶寬。同等圖像質量,H.264算法比H.263算法碼流降低了5O ;但同時H.264算法比H.263算法復雜得多,需要更強的處理能力,以及做更多的軟件優化工作。H.264算法在DM643上的實現和優化是整個系統軟件設計的難點和重點。下面以它為例說明軟件的開發、優化工作。
DM643上的軟件開發過程可分為3個階段:
第1階段是開發C代碼,然后使用profiling工具確定代碼可能存在的低效率段。為進一步改進代碼性能,需進入第2階段。
第2階段是優化C代碼。利用內聯函數、編譯器的外殼選項等方法進一步優化C代碼。再次使用profiling工具檢查其性能,如果代碼仍達不到所期望的效果,須進入第3階段。
第3階段是編寫線性匯編代碼 從C代碼中抽出對性能影響很大的代碼段,用線性匯編重新編寫這段代碼,然后使用匯編優化器優化該代碼。
2.1 C代碼的開發和優化
開發過程中要充分利用Tl公司為用戶提供的功能強大的函數庫,比如IMAGE.LIB庫中就包含許多常用函數,可以實現DCT/IDCT變換、DCT量化、自適應濾波等功能。這些函數都是優化過的,完全能夠實現軟件流水,效率很高。另外,開發C語言代碼還需要考慮的要點包括:① 使用適當的數據結構- - 對定點乘法,應盡可能使用short型數據;對循環計數器應使用int或者無符號int 類型。②使用查找表或常數值代替通過直接計算得到結果的語句或函數。
代碼分析結果顯示DCT、IDCT 、運動估計占程序總運算量的比重很大,因此這部分是程序優化的重點。優化C 代碼包括使用編譯器選項、使用內聯函數、使用軟件流水等。
(1)向編譯器指明不相關的指令。
為使指令并行操作,編譯器必須確定指令間的相關性,只有不相關的指令才可并行執行。若編譯器不能確定兩條指令是不相關的,則只能安排它們串行執行。用戶可通過如下方法指明相關的指令:
①關鍵字cons t 表示一個變量或一個變量的存儲單元保持不變,使用const 可提高代碼的性能和適應性。
②使用-mt 選項向編譯器說明在代碼中不存在存儲器相關性,即允許編譯器在無存儲器相關性的假設下進行優化。
(2)使用內聯函數(intrinsics)。
可用內聯函數快速優化C 代碼。如在算術操作中,常對計算的結果做飽和(saturation)處理,使用intrinsics只須調用SADD, 一個指令周期便可得到最終結果。比花費兩個嵌套的條件判斷語句來判斷結果是否溢出,最后得到結果效率要高得多。
(3)使用軟件流水。
在編譯時,使用-o2 選項和-o3 選項,編譯器可對循環代碼實現軟件流水。為填滿軟件流水線,軟件流水結構需要執行的最小循環迭代次數稱為最小循環次數。循環總數小于最小循環次數時,執行不流水形式循環;循環總數大于最小循環次數時,執行軟件流水形式循環。可以使用-ms 選項,使編譯器根據循環次數僅產生一種循環形式; 可使用-o3 和-pm 選項,使優化器訪問整個程序,了解循環次數信息; 使用-nassert 內聯函數,防止冗余循環產生;使用-mh 選項,消除軟件流水循環的排空,從而減小代碼尺寸。
由于在嵌套循環中編譯器僅對最里面的循環執行軟件流水,因此對于執行周期很少的內循環進行循環展開,對外循環進行軟件流水。
使用軟件流水應當注意的問題: 盡管軟件流水循環可以包含內聯函數,但不能包含函數調用; 在循環中不使用break 語句;循環控制變量不能與循環體內的語句有關; 如果循環體內復雜的條件代碼需要超過5 個條件寄存器或者32 個以上寄存器,則這個循環不可進行軟件流水。
(4)片內存儲器的分配及DMA技術的運用。
DM643 內部有16 KB 的一級程序緩存、16 KB 的一級數據緩存和256 KB 的程序數據共享二級緩存,遠小于執行程序和待處理圖像數據,不可能將程序和圖像數據都在片內RAM 中緩存,因此合理地配置和使用存儲空間,對系統整體效率影響很大。
提高算法程序執行速度的關鍵是使核心循環代碼和要訪問的數據在第1 次訪問之后全部發生L1P 和L1D 命中。核心循環代碼占的空間很小,執行過一次之后,完全可以全部在L1P 中緩存,因此,不用考慮代碼如何在存儲器中存放,主要問題是圖像數據的存放。
由于L1D 采取LRU (Least Recently Used)分配機制,因此對于小于等于16 KB 的連續存放的數據塊可完全在L1D 中命中。以解碼過程為例,IDCT 和運動補償模塊都是以宏塊為單位進行運算的,IDCT 數據類型為short型,運動補償中的預測幀和當前幀的數據類型為unsignedchar 型。計算一個宏塊(420 格式)的IDCT 和運動補償要訪問的數據大小共需1 536 字節,運動補償的數據包括預測宏塊和當前宏塊的數據,實際解碼中以6 個宏塊(10 KB)作為1 次處理對象。待處理的數據要從外部存儲器搬到L2 中連續的存儲空間,可利用EDMA 與CPU 并行工作的特點,采取Ping??Pong 技術,使CPU 在處理Ping空間數據的同時,由EDMA 將下次要處理的數據搬到Pong 空間中; 當CPU 處理Pong 空間數據時,再由EDMA將Ping 空間已處理好的數據搬回外部存儲器,并將下次要處理的數據搬到Ping 空間,這樣就可達到CPU 的最大計算能力。Ping、Pong 空間各占用的大小為20 KB, 兩個總共約40 KB.L2 中的剩余空間分出64 KB 留給數據空間,用于解碼中常用的解碼表、量化步長、輸入壓縮碼流緩沖區和輸出碼流緩沖區等。64 KB 的程序空間用于存儲H. 264 算法中的運動預測、運動補償和中斷服務程序等關鍵代碼。L2 其余部分配置為Cache, 操作與L1D 類似。
2. 2 編寫線性匯編代碼
為了提高代碼性能,對影響處理速度的關鍵C 代碼段可以用線性匯編重新編寫。線性匯編代碼類似于匯編代碼,不同的是線性匯編代碼中不需要給出匯編代碼必須指出的所有信息(如所使用的寄存器、指令的并行與否、指令的延遲周期和指令使用的功能單元等),匯編優化器會根據代碼的情況確定這些信息。當然,如果能夠事先確定一些信息(如循環的執行次數、存儲區的地址等),則編寫的線性匯編代碼的效率更高。具體的優化措施如下:
①使用偽指令向匯編優化器提供較為詳細的信息。
②畫出指令的相關圖,根據相關圖合理分配邏輯單元,最大限度地保證指令的并行執行。
③充分使用C64x DSP 提供的強大包處理指令處理數據(包處理指令可同時處理2 個l6 位數據和4 個8 位數據)。本系統中使用了AVGU4、MIN2、M AX2、SPACKU4、PACK2、D0T P2、D0T PN2 和UNPKLU4 等指令。C64x DSP 還提供了STDW(STNDW)、LDDW(LDNDW)指令,可一次存取連續的64 位數據。可利用LDDW 指令,將作1 次行變換所需數據1 次取來,并將處理后的結果利用STDW 指令一次存好。這樣大大縮短了代碼長度,提高了代碼效率。
④利用Schedule Table 確定循環的重復間隔,合理安排功能單元,進行軟件的流水。
⑤對于兩重循環嵌套,可將內層循環展開為外層循環內部的條件指令。這樣可減小由內層循環所帶來的循環前后的prolog 和epilog 的開銷。
3 性能分析
設計、調試好硬件系統,并在DM643 上對整個系統軟件進行設計和優化后,視/ 音頻編/ 解碼的處理速度及系統功能得到了很大提高。IP 可視電話基本做到話音清晰并實時傳輸,在網絡速度為30 kbps 以上時能實現CIF 圖像25~ 30 幀/ s, 并可以音唇同步。
結語
該系統能在一顆DM643 芯片上實現網絡可視電話的幾乎全部功能,能對音/ 視頻進行實時的編解碼和網絡傳輸,圖像質量高且易于升級,是一種比較理想的網絡可視電話解決方案。下一步的工作是把短信、電子郵件等其他功能整合進來。這樣,網絡IP 可視電話必將成為家庭或辦公室的真正桌面通信中心。










 工商網監
工商網監
評論