 電子發燒友App
電子發燒友App


隨著對用戶體驗的不斷追求,延遲分析成為大型分布式系統中不可或缺的一環。本文介紹了目前在線服務中常用的延遲分析方法,重點講解了關鍵路徑分析的原理和技術實現方案,實踐表明此方案效果顯著,在耗時優化方面發揮了重要作用,希望這些內容能夠對有興趣的讀者產生啟發,并有所幫助。? ? ??
背景
近年來,互聯網服務的響應延遲(latency)對用戶體驗的影響愈發重要,然而當前對于服務接口的延遲分析卻沒有很好的手段。特別是互聯網業務迭代速度快,功能更新周期短,必須在最短的時間內定位到延遲瓶頸。然而,服務端一般都由分布式系統構成,內部存在著復雜的調度和并發調用關系,傳統的延遲分析方法效率低下,難以滿足當下互聯網服務的延遲分析需求。
關鍵路徑分析(Critical Path Tracing)作為近年來崛起的延遲分析方法,受到Google,Meta,Uber等公司的青睞,并在在線服務中獲得了廣泛應用。百度App推薦服務作為億級用戶量的大型分布式服務,也成功落地應用關鍵路徑延遲分析平臺,在優化產品延遲、保障用戶體驗方面發揮了重要的作用。本文介紹面向在線服務常用的延遲分析方法,并詳細介紹關鍵路徑分析的技術實現和平臺化方案,最后結合實際案例,說明如何在百度App推薦服務中收獲實際業務收益。
常用分布式系統延遲分析方法
當前業界常用的服務延遲分析有RPC監控(RPC telemetry),CPU剖析(CPU Profiling),分布式追蹤(Distributed Tracing),下面以一個具體的系統結構進行舉例說明:
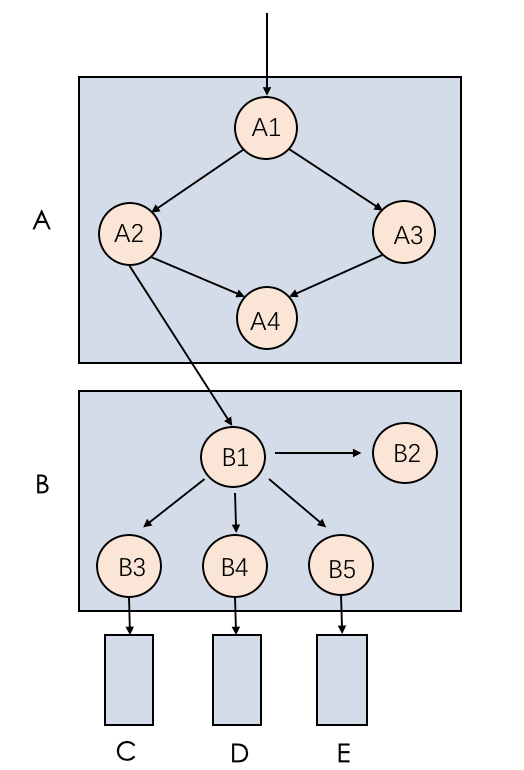
△圖1 系統結構示例
A、B、C、D、E分別為五個系統服務,A1到A4、B1到B5分別為A、B系統內的子組件(可以理解為A、B系統內部進一步的細化組成部分),箭頭標識服務或組件之間的調用關系。
2.1 RPC監控
RPC是目前微服務系統之間常用的調用方式,業界主要開源的RPC框架有BRPC、GRPC、Thrift等。這些RPC框架通常都集成了統計打印功能,打印的信息中含有特定的名稱和對應的耗時信息,外部的監控系統(例如:Prometheus)會進行采集,并通過儀表盤進行展示。
△圖2 RPC耗時監控UI實例
此分析方式比較簡單直接,如果服務之間的調用關系比較簡單,則此方式是有效的,如果系統復雜,則基于RPC分析結果進行的優化往往不會有預期的效果。如圖1,A調用B,A2和A3是并行調用,A3內部進行復雜的CPU計算任務,如果A2的耗時高于A3,則分析A->B的RPC延時是有意義的,如果A3高于A2,則減少A->B的服務調用時間對總體耗時沒有任何影響。此外RPC分析無法檢測系統內部的子組件,對整體延遲的分析具有很大的局限性。
2.2 CPU?Profiling
CPU分析是將函數調用堆棧的樣本收集和聚合,高頻出現的函數認為是主要的延遲路徑,下圖是CPU火焰圖的展示效果:
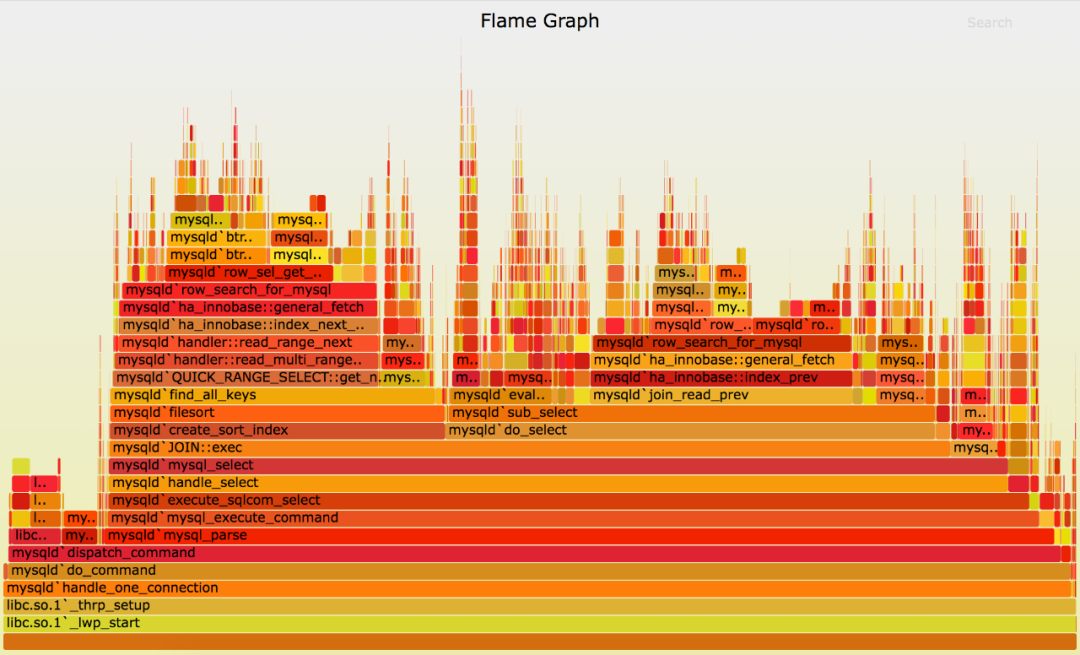
△圖3 cpu火焰圖
水平的寬度表示抽樣的次數,垂直方向表示調用的關系,火焰圖通常是看頂層的哪個函數寬度最大,出現“平頂”表示該函數存在性能問題。
CPU Profiling可以解決上面說的RPC監控的不足,然而由于依然無法知曉并行的A2和A3誰的耗時高,因此按照RPC鏈路分析結果還是按照CPU分析的結果進行優化哪個真正有效果將變得不確定,最好的方式就是都進行優化,然而這在大型復雜的系統中成本將會變得很大。可見CPU Profiling同樣具有一定的局限性。
2.3?分布式追蹤
分布式追蹤目前在各大公司都有了很好的實踐(例如Google的Dapper,Uber的Jaeger)。
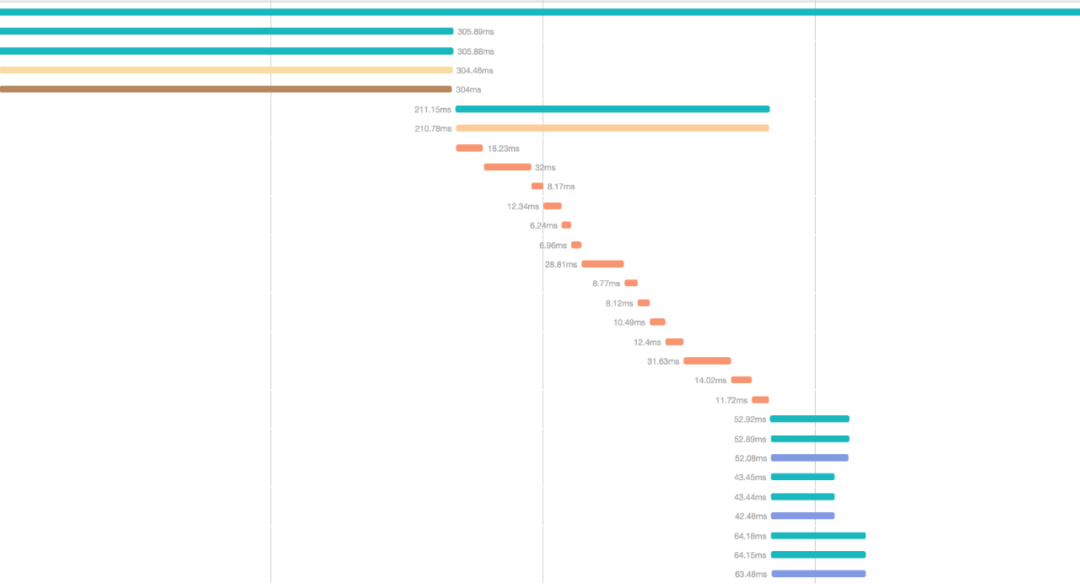
△圖4 分布式追蹤效果示例
分布式追蹤將要追蹤的“節點”通過span標識,將spans按照特定方式構建成trace,效果如圖4所示,從左到右表示時間線上的不同節點耗時,同一個起始點表示并發執行。這需要收集所有跨服務請求的信息,包括具體的時間點以及調用的父子關系,從而在外部還原系統調用的拓撲關系,包含每個服務工作的開始和結束時間,以及服務間是并行運行還是串行運行的。
通常,大多數分布式跟蹤默認情況下包括RPC訪問,沒有服務內部子組件信息,這需要開發人員根據自身系統的結構進行補全,然而系統內部自身運行的組件數目有時過于龐大,甚者達到成百上千個,這就使得成本成為了分布式跟蹤進行詳細延遲分析的主要障礙,為了在成本和數據量之間進行權衡,往往會放棄細粒度的追蹤組件,這就使得分析人員需要花費額外的精力去進一步分析延遲真正的“耗費點”。
下面介紹關鍵路徑分析的基本原理和實際的應用。
關鍵路徑分析
3.1 介紹
關鍵路徑在服務內部定義為一條耗時最長的路徑,如果將上面的子組件抽象成不同的節點,則關鍵路徑是由一組節點組成,這部分節點是分布式系統中請求處理速度最慢的有序集合。一個系統中可能有成百上千個子組件,但是關鍵路徑可能只有數十個節點,這樣數量級式的縮小使得成本大大降低。我們在上圖的基礎上加上各個子模塊的耗時信息。
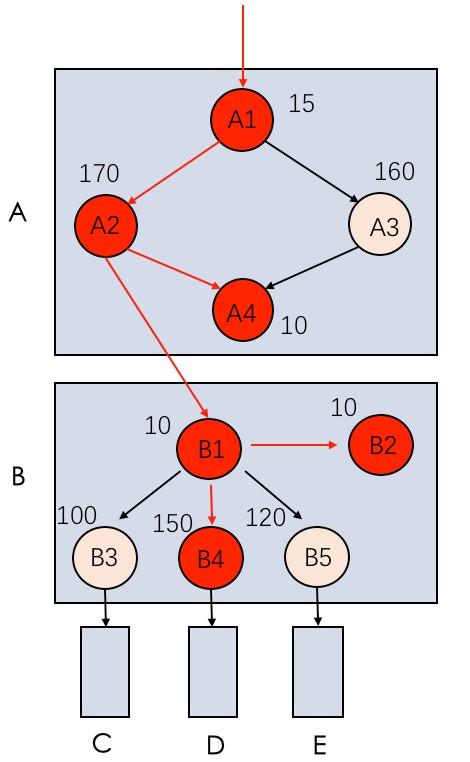
△圖5 加上耗時信息的示例系統結構
如圖5所示,在B中B1并行調用B3、B4、B5,延遲分別為100,150,120,然后再調用內部的B2,進行返回,關鍵路徑為B1->B4->B2,延遲為10 + 150 + 10 = 170,在A中A1并行調用A2,A3。A2和A3都完成后再調用A4,然后返回,關鍵路徑為A1->A2->A4,延遲為15 + 170 + 10 = 195 ,因此這個系統的關鍵路徑為紅色線條的路徑?A1->A2->B1->B4->B2->A4。
通過這個簡單的分布式系統結構表述出關鍵路徑,其描述了分布式系統中請求處理速度最慢步驟的有序列表。可見優化關鍵路徑上的節點肯定能達到降低整體耗時的目的。實際系統中的關鍵路徑遠比以上描述的復雜的多,下面進一步介紹關鍵路徑分析的技術實現和平臺化方案。
3.2?實際應用解決方案
關鍵路徑數據的采集到可視化分析的流程如圖所示:
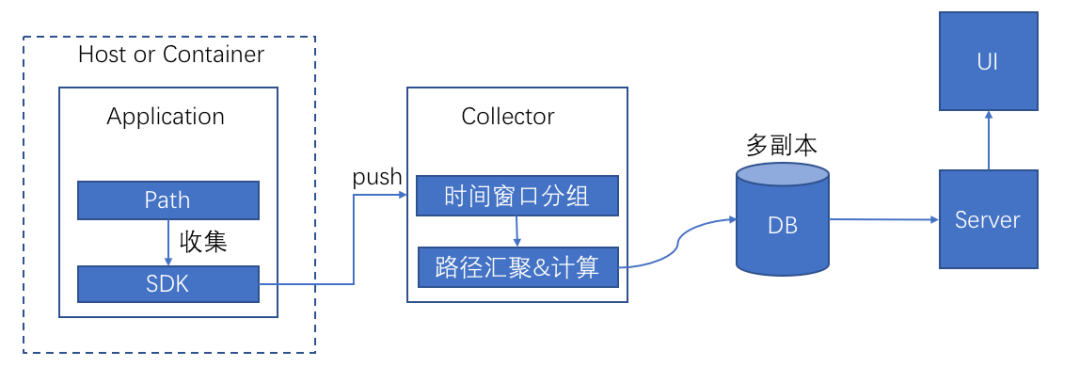
△圖6 數據處理流程
3.2.1 核心關鍵路徑的產出和上報
關鍵路徑由服務自身進行產出,一般大型分布式服務都會采用算子化執行框架,只要集成到框架內部,所有依賴的服務都可以統一產出關鍵路徑。
對于算子化執行框架,考慮到如下簡單的圖結構:
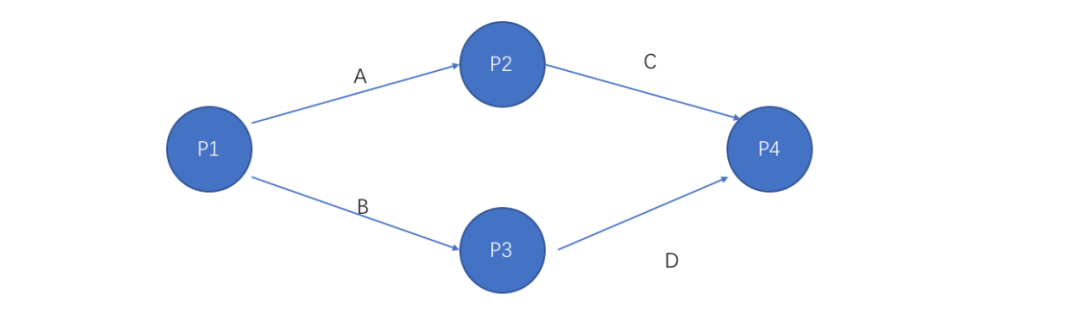
△圖7 一種簡單的圖結構
P1-P4是4個策略算子,按照圖示調度執行。采集SDK收集每個算子開始和結束的運行時刻,匯總為關鍵路徑基礎數據上報。
3.2.2 核心關鍵路徑的匯聚和計算
一個服務內部的關鍵路徑往往反映不了整個分布式系統延時的常態情況,這就需要將不同服務內部關鍵進行匯聚。這里的匯聚是按照時間段進行匯聚,這就需要collector收到數據后按照上傳攜帶過來的時間點分到對應時間的窗口內,收集完成后進行各種延時指標的計算以及關鍵路徑的匯聚,這里有三種匯聚方式:
1、節點關鍵路徑匯聚
這里是將系統的關鍵路徑拼接到一起,組成一條完整路徑,將各個節點進行匯聚,選擇出現次數最多的路徑作為最“核心”的關鍵路徑。
2、服務關鍵路徑匯聚
節點關鍵路徑是節點粒度的表示形態,然而在一個系統中服務的路徑關系是怎樣的呢?這就需要服務關鍵路徑來表示。為了更好的表征服務內部的耗時情況,對節點進行聚合抽象。將所有計算型節點統一歸為一個叫inner的節點,作為起始節點,其他訪問外部服務的節點不變,在重新轉換后的路徑中選擇出現次數最多的路徑作為服務關鍵路徑,聚合后的路徑可以標識服務“自身”和“外部”的延時分布情況。
3、平鋪節點類型匯聚
這部分主要是對于核心路徑比較分散的子節點,例如B中B1訪問B3/B4/B5等多個下游(在實際的系統中可能有數十個節點出現在關鍵路徑中,但是沒有一個節點有絕對的核心占比,各個節點在關鍵路徑中相對比較分散,且經常周期性改變),對這種情況直接統計并篩選出核心占比>x%(x%根據特定需求進行確定,x越小則收集到的關鍵節點越精細)的節點,需要注意的是這里是平鋪取的節點,并不是一條“核心”的關鍵路徑。
3.2.3 核心關鍵路徑的存儲和展示
數據庫存儲的是計算好的結果,以時間、用戶類型、流量來源等作為查詢關鍵字,方便進行多維度分析。這里使用OLAP Engine進行存儲,方便數據分析和查詢。
展示的內容主要有以下幾部分:
核心占比:節點出現在關鍵路徑中的概率
核心貢獻度:節點出現在關鍵路徑中時,自身耗時占整個路徑總耗時的比例
綜合貢獻度:核心占比和核心貢獻度兩者相乘,作為綜合衡量的標準
均值:節點耗時的平均值
分位值:節點耗時的不同分位值。分位值是統計學中的概念,即把所有的數值從小到大排序,取前N%位置的值即為該分位的值,常用的有50分位、80分位、90分位等
核心占比高貢獻度很低或者貢獻度高占比很低的節點優化的效果往往不是很顯著,因此使用綜合貢獻度做為核心占比和核心貢獻度的綜合考量,這個指標高的節點是我們需要重點關注的,也是優化收益較大的。
從耗時優化的角度出發,這里有兩個主要的訴求,一個是查詢某個時間段的關鍵路徑,依此來指導進行特定節點或階段的優化。另一個是需要進行關鍵路徑的對比,找到diff的節點,挖掘具體的原因來進行優化,整體延時的退化往往是由于特定節點的惡化造成的,這里的對比可以是不同時間、不同地域、甚至是不同流量成分的對比,這樣為延遲分析提供了多維度的指導依據。
關鍵路徑的效果如圖8所示,在頁面上可以按照特定維度進行排序,便于進一步的篩選。

△圖8 核心關鍵路徑示例
應用
百度App推薦系統內部建設了關鍵路徑延遲分析平臺Focus,已上線1年多,成功支持了日常的耗時分析和優化工作,保證了百度App Feed流推薦接口的毫秒級響應速度,提供用戶順滑的反饋體驗。獲得研發,運維和算法團隊的一致好評。
以推薦服務的一個實際線上問題舉例,某天監控系統發現系統出口耗時突破監控閾值,關鍵路徑延遲分析平臺自動通過服務關鍵路徑定位到是某個服務B出了問題,然后通過觀察服務B的節點關鍵路徑發現是節點X有問題,然而節點X下游請求的是多個下游,這時通過平鋪節點類型發現平時耗時比較低的隊列Y延時突增,核心占比和貢獻度都異常高,通知下游負責的owner進行定位,發現確實是服務本身異常,整個定位過程全自動化,無需人工按個模塊排查。
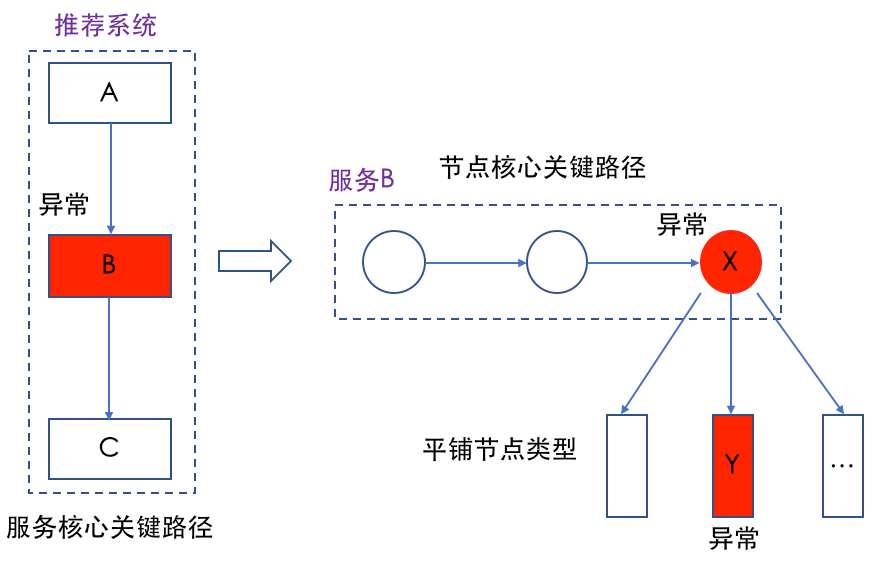
△圖9 系統延遲異常后的自動定位分析過程
總結
在當下大型分布式系統中,服務接口的低響應延遲是保證用戶體驗的重要關鍵。各大公司也紛紛投入大量精力來優化延時,然而復雜的系統結構使得優化難度較大,這就需要借助創新的優化方法。本文通過具體的例子介紹了關鍵路徑分析的原理,在百度App推薦系統中實際應用落地的平臺化方案,最后分享了實際案例。延遲耗時分析方向還有很多新的發展方向和創新空間,也歡迎對該方向感興趣的業界同仁一起探討。
編輯:黃飛
?









 工商網監
工商網監
評論