 電子發燒友App
電子發燒友App


 ?>設計
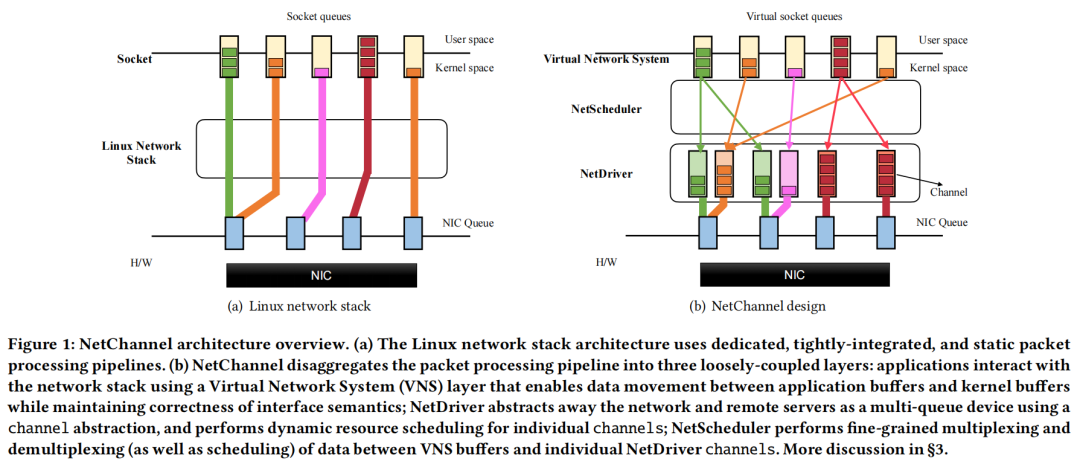
如圖1(b)所示,NetChannel將今天的網絡堆棧中緊密集成的包處理管道分解為三個松散耦合的層。虛擬網絡系統(VNS):應用程序與提供標準化接口的VNS層交互。VNS層支持應用程序和內核程序之間的數據傳輸,同時確保接口語義的正確性(例如,流接口的有序傳遞)。NetChannel的核心是NetDriver層:它使用channel抽象將網絡和遠程服務器抽象為一個多隊列設備。特別是,NetDriver層將包處理從單個應用程序和core解耦:一個core上的應用程序讀取/寫入的數據可以映射到一個或多個channel,而不破壞應用程序語義。每個通道都實現了協議規范功能獨立,可以動態映射到一個底層硬件隊列,和任何一對服務器之間的通道的數量可以擴展獨立于這些服務器上運行的應用程序的數量和個人應用程序使用的核心的數量。網絡調度器:它將延遲敏感的應用程序與吞吐量綁定的應用程序隔離:網絡通道使延遲敏感的應用程序能夠實現微秒規模的尾部延遲,同時允許帶寬密集型的應用程序幾乎完美地使用剩余帶寬。
NetChannel優勢在于簡單,容易實現,同時能夠提升當前網絡堆棧的性能,且獨立于網絡堆棧的位置——內核、用戶空間或硬件,可以在微內核風格的用戶空間堆棧上實現其設計。作者選擇Linux內核只是因為它的成熟、穩定性和廣泛的部署。>性能
?>設計
如圖1(b)所示,NetChannel將今天的網絡堆棧中緊密集成的包處理管道分解為三個松散耦合的層。虛擬網絡系統(VNS):應用程序與提供標準化接口的VNS層交互。VNS層支持應用程序和內核程序之間的數據傳輸,同時確保接口語義的正確性(例如,流接口的有序傳遞)。NetChannel的核心是NetDriver層:它使用channel抽象將網絡和遠程服務器抽象為一個多隊列設備。特別是,NetDriver層將包處理從單個應用程序和core解耦:一個core上的應用程序讀取/寫入的數據可以映射到一個或多個channel,而不破壞應用程序語義。每個通道都實現了協議規范功能獨立,可以動態映射到一個底層硬件隊列,和任何一對服務器之間的通道的數量可以擴展獨立于這些服務器上運行的應用程序的數量和個人應用程序使用的核心的數量。網絡調度器:它將延遲敏感的應用程序與吞吐量綁定的應用程序隔離:網絡通道使延遲敏感的應用程序能夠實現微秒規模的尾部延遲,同時允許帶寬密集型的應用程序幾乎完美地使用剩余帶寬。
NetChannel優勢在于簡單,容易實現,同時能夠提升當前網絡堆棧的性能,且獨立于網絡堆棧的位置——內核、用戶空間或硬件,可以在微內核風格的用戶空間堆棧上實現其設計。作者選擇Linux內核只是因為它的成熟、穩定性和廣泛的部署。>性能-
使單個應用程序線程飽和數百千兆訪問鏈路帶寬;
-
支持具有核數的小消息處理的近線性可伸縮性,獨立于應用程序線程數;
-
支持隔離對延遲敏感的應用程序,允許它們即使在與以近線速率運行的吞吐量綁定的應用程序競爭時也能保持us-scale的尾延遲。
-
優點
-
不足
SPRIGHT: Extracting the Server from Serverless Computing High-Performance eBPF-based Event-driven, Shared-Memory Processing
Shixiong Qi, Leslie Monis, Ziteng Zeng, Ian-chin Wang, K. K. Ramakrishnan (University of California, Riverside)
>背景與問題 這篇文章來自California的研究者。它設計了一個一種輕量級、高性能、響應式無服務器(Serverless)框架——SPRIGHT。無服務器計算越來越受歡迎,因為用戶只需要開發他們的應用程序,而無需關心底層操作系統和硬件基礎設施。但是對于云服務提供商來說,如何確保滿足服務質量要求(SLO)是一項復雜的工作。其中出現的困難主要有兩個:(1)重型的無服務器組件:為了實現具有廣泛功能支持的跨功能服務網格層(例如指標收集和緩沖,促進無服務器網絡和編配等),每個函數倉(function pod)都會有一個專用的sidecar代理組件來幫助建立。但是該組件是重型的,需要持續運行并產生過多的開銷。并且對于非常見的協議(例如MQTT, CoAP等),也需要額外的重型組件來適配,也會導致大量資源開銷。(2)?函數鏈的數據平面性能較差:現代的云架構為了提高靈活性,借助獨立于平臺的通信技術(如HTTP/REST API),將單個應用程序分解為多個松耦合、鏈接的函數。但是,這涉及到上下文切換、序列化和反序列化以及數據復制開銷。目前的設計還嚴重依賴于內核協議棧來處理路由和在功能艙之間轉發網絡數據包,所有這些都會影響性能。雖然靈活性提升了,但是性能開銷卻仍是一個負擔。函數間產生的復雜數據管道為函數鏈增加了更多的網絡通信。所有這些都會導致數據平面性能較差(吞吐量較低,延遲較高),影響服務水平目標(SLOs)。 下圖為作者研究了幾個專有和開源的無服務器平臺的設計后,開發的一個通用抽象模型。當客戶端發送消息時,在經過網關后(①),在前端代理/消息代理中排隊(②)。代理會將消息發送到第一個函數倉,但是會先經過sidecar代理(③)。第一個函數處理完成后,會發往代理排隊進入下一個函數倉,但還是要先經過sidecar代理(④)。轉交到下個函數倉,按③④的步驟,沿著函數鏈反復執行下去(⑤)。由此圖就可以看出,無服務器函數鏈產生的額外開銷是非常巨大的(除函數倉的user container外都是)。 ? >設計
作者以開源項目Knative作為基礎平臺開始。使用事件驅動處理和共享內存來提升性能,并廣泛使用eBPF進行聯網和監控。eBPF是一個內核內的輕量級虛擬機,它可以插入/從內核中插入,具有相當的靈活性、效率和可配置性。
下圖顯示了SPRIGHT的總體架構。主要包括以下幾個內容:
>設計
作者以開源項目Knative作為基礎平臺開始。使用事件驅動處理和共享內存來提升性能,并廣泛使用eBPF進行聯網和監控。eBPF是一個內核內的輕量級虛擬機,它可以插入/從內核中插入,具有相當的靈活性、效率和可配置性。
下圖顯示了SPRIGHT的總體架構。主要包括以下幾個內容: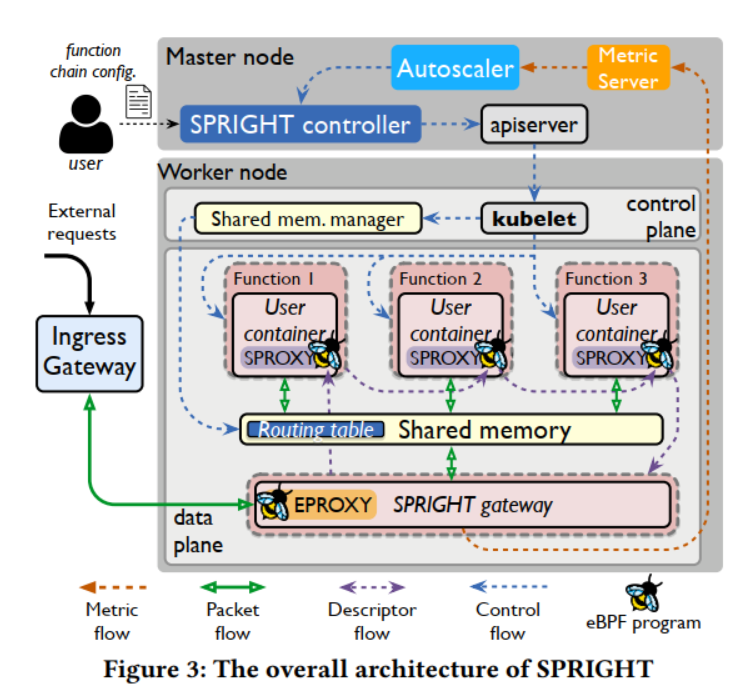 SPRIGHT控制器用來協調與編配引擎(即K8s和Knative)協同工作的函數的控制平面。在K8s主節點中運行,與k8s運作在每個worker節點上的進程合作,對函數倉的生命周期進行管理。此外,與k8s的調度器一起工作,以確定函數鏈的規模和函數鏈在適當的工作節點上的放置位置。給定一個來自用戶的函數鏈創建請求,SPRIGHT控制器為函數鏈創建并分配必要的控制和數據平面組件,包括共享內存管理器和SPRIGHT網關,并根據用戶配置啟動函數鏈中的函數。
SPRIGHT網關是為了靈活管理SPRIGHT中函數鏈的進出流量,避免在函數鏈中重復處理協議。充當了函數鏈的反向代理,以合并協議處理。它攔截對函數鏈的傳入請求,并將有效負載復制到共享內存區域。這允許在鏈內進行零拷貝處理,避免不必要的序列化/反序列化和協議棧處理。SPRIGHT網關是一個輕量級組件,內存占用相對較小,CPU消耗也不是一個重要的問題。
為了消除額外的網絡組件對函數鏈的影響,作者設計了直接功能路由(DFR)。DFR利用共享內存并利用eBPF映射提供的可配置性。DFR允許動態更新路由規則,并使用共享內存直接在函數之間傳遞數據。
設計了一個輕量級的、事件驅動的代理(EPROXY和SPROXY),它使用eBPF來構造服務網格,而不是像Knative那樣使用與每個函數實例關聯的連續運行的隊列代理。因此,我們減少了大量的處理開銷。>性能
與Knative相比,SPRIGHT通過大量使用基于ebp的事件驅動能力以及高性能的共享內存處理,實現了高達5倍的吞吐量提高,53倍的延遲減少,以及27倍的CPU使用節省。
與使用DPDK提供共享內存和零拷貝交付的環境相比,SPRIGHT實現了具有競爭力的吞吐量和延遲,同時消耗的CPU資源減少了11倍。
此外,對于物聯網應用中常見的間歇請求到達,與Knative使用“預熱”功能相比,SPRIGHT仍然將平均延遲提高了16%,同時減少了41%的CPU周期。>個人觀點
SPRIGHT是一個無服務器函數鏈框架,通過對零拷貝、基于eBPF代理和共享內存的系統優化的良好組合,相對于現有的開源無服務器框架,它提供了大量的CPU、延遲和啟動時間改進。此外,本文貢獻了eBPF中高性能軟件數據路徑的設計和實現,該路徑非常適合跨節點中運行的函數鏈處理請求調用的路由和轉發。
SPRIGHT控制器用來協調與編配引擎(即K8s和Knative)協同工作的函數的控制平面。在K8s主節點中運行,與k8s運作在每個worker節點上的進程合作,對函數倉的生命周期進行管理。此外,與k8s的調度器一起工作,以確定函數鏈的規模和函數鏈在適當的工作節點上的放置位置。給定一個來自用戶的函數鏈創建請求,SPRIGHT控制器為函數鏈創建并分配必要的控制和數據平面組件,包括共享內存管理器和SPRIGHT網關,并根據用戶配置啟動函數鏈中的函數。
SPRIGHT網關是為了靈活管理SPRIGHT中函數鏈的進出流量,避免在函數鏈中重復處理協議。充當了函數鏈的反向代理,以合并協議處理。它攔截對函數鏈的傳入請求,并將有效負載復制到共享內存區域。這允許在鏈內進行零拷貝處理,避免不必要的序列化/反序列化和協議棧處理。SPRIGHT網關是一個輕量級組件,內存占用相對較小,CPU消耗也不是一個重要的問題。
為了消除額外的網絡組件對函數鏈的影響,作者設計了直接功能路由(DFR)。DFR利用共享內存并利用eBPF映射提供的可配置性。DFR允許動態更新路由規則,并使用共享內存直接在函數之間傳遞數據。
設計了一個輕量級的、事件驅動的代理(EPROXY和SPROXY),它使用eBPF來構造服務網格,而不是像Knative那樣使用與每個函數實例關聯的連續運行的隊列代理。因此,我們減少了大量的處理開銷。>性能
與Knative相比,SPRIGHT通過大量使用基于ebp的事件驅動能力以及高性能的共享內存處理,實現了高達5倍的吞吐量提高,53倍的延遲減少,以及27倍的CPU使用節省。
與使用DPDK提供共享內存和零拷貝交付的環境相比,SPRIGHT實現了具有競爭力的吞吐量和延遲,同時消耗的CPU資源減少了11倍。
此外,對于物聯網應用中常見的間歇請求到達,與Knative使用“預熱”功能相比,SPRIGHT仍然將平均延遲提高了16%,同時減少了41%的CPU周期。>個人觀點
SPRIGHT是一個無服務器函數鏈框架,通過對零拷貝、基于eBPF代理和共享內存的系統優化的良好組合,相對于現有的開源無服務器框架,它提供了大量的CPU、延遲和啟動時間改進。此外,本文貢獻了eBPF中高性能軟件數據路徑的設計和實現,該路徑非常適合跨節點中運行的函數鏈處理請求調用的路由和轉發。NeuroScaler: neural video enhancement at scale
Hyunho Yeo, Hwijoon Lim, Jaehong Kim, Youngmok Jung, Juncheol Ye, Dongsu Han (KAIST)
這篇文章來自KAIST的研究者。本文主要解決的內容是在直播視頻流傳輸的場景下,采用傳統的神經增強方法(Neural enhancement)實現高分辨率的視頻流傳輸時,神經超分辨率(Neural super-resolution)計算開銷過大,無法滿足實時直播需求的問題。本文的是通過提供恰當的超分辨率幀計算方案與服務端的編碼方案,優化整體傳輸性能與視頻質量。>背景與問題 當今視頻流的傳輸過程中,人們對于高分辨率的視頻需求日益增長。而隨著網絡技術的迭代,人們對于直播視頻流的質量有了更多的期待。但是,高清視頻的傳輸很大程度上依賴于上行帶寬,因此,傳統的技術多采用DNN技術,從較低的分辨率圖像中獲取較高的分辨率。當前的技術具有以下幾個特點:上行帶寬較低:視頻流需要從上行帶寬中傳輸到媒體服務器,并分發給其他接收者。但由于上行帶寬較低,往往無法提供較高的視頻流質量。超分辨率技術:超分辨率技術是指將低分辨率對應物生成高分辨率圖像的技術。現有的超分辨率技術大多使用深度神經網絡 (DNN),學習低分辨率到高分辨率低映射。錨幀選取:錨幀是指應用超分辨率技術的幀。因為對幀進行超分辨率推理帶來極大的開銷,因此我們無法對每一個幀進行推理。所以,從視頻流的一系列幀中選取錨幀,利用錨幀重建高分辨率視頻圖像是一種合理的方式。 因為上行帶寬較低,所以我們需要采用超分辨率技術進行視頻流質量的提升。但是,超分辨率技術帶來巨大的計算開銷,因此,我們不能對每一個流進行推理,而是應該選擇錨幀進行輔助重建。這也就帶來了一系列的問題:1)錨幀的選取很大程度上影響著視頻流的質量,不合理的錨幀會導致重建后的視頻質量較低,因此,合適的實時錨幀選擇方式能極大改善系統的質量。2)錨幀的計算開銷是異構的,這也意味著如果對于錨幀計算資源分配不恰當,會導致整體性能的降低。3)媒體服務器上對幀的編碼也會帶來極大的計算開銷。>設計 本文作者認為,合適的錨幀選擇可以提高視頻重建的質量,而視頻流的編碼則是制約整體性能的重要瓶頸。當前的設計面臨著三個主要的挑戰:1)圖像增強的高計算開銷。2)編碼帶來的額外時延。3)在計算資源上的分配失效,無法帶來滿意的表現。此作者提出了三個部分的改進,分別是1)錨幀的調度,即選取合適的錨幀,利用該錨幀可以獲取更好的視頻重建表現。2)為錨幀有效地分配計算資源。3)以及錨幀的增強設計,即使用合適的方法,在超分辨率編碼階段降低計算開銷。其整體的架構如下圖所示: ?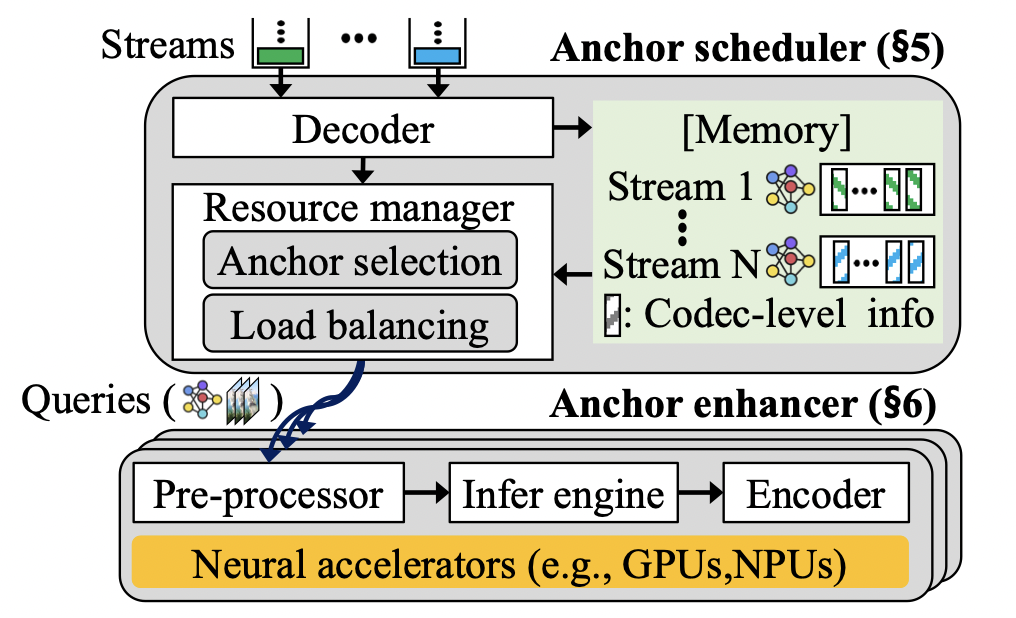 無推斷錨幀選取:錨幀的增益可以不經過實際的神經推理即可獲取。當我們不斷使用超分辨率進行圖像的重建,因為圖像之間的殘差,導致重建后的質量損失。另一方面,文章觀察到增益和殘差具有一定的相關性,因此,文章通過殘差的計算,選取合適的錨幀,而不需要進行具有極大計算開銷都神經推理。錨幀計算資源分配:錨幀的計算開銷和增益都是異構并會隨著時間變化的,因此,簡單的平均分配并不能帶來優秀的表現。因此,計算資源的調度應該從錨幀的角度思考。本文提出了一個錨幀的選取算法,即從之前計算獲得的錨幀集合中,按照順序盡可能多的選取一部分錨幀,同時這些錨幀的推理時延需求要滿足一定的限制。在此之后,將錨幀進行分組,并對每組分配計算資源。編碼開銷限制:文章指出,非錨幀在接收端仍能以較低的計算開銷進行重建,因此,在媒體服務端,沒必要對非錨幀進行編碼,而錨幀所占比例較低,這極大降低了編碼的開銷。而在解碼端,該方法只引入了18% 的額外計算開銷,這與編碼開銷的降低相比,是可以接受的。GPU上下文切換:除了上述設計之外,文章還針對推理框架的切換帶來的開銷,引入了模型預優化與內存預分配,提高了整體的性能表現。>性能端對端吞吐量:如下圖所示,NeuroScaler overview相對于每一幀推斷以及其他選取的對比,吞吐量提高了10x和2x-5x。
無推斷錨幀選取:錨幀的增益可以不經過實際的神經推理即可獲取。當我們不斷使用超分辨率進行圖像的重建,因為圖像之間的殘差,導致重建后的質量損失。另一方面,文章觀察到增益和殘差具有一定的相關性,因此,文章通過殘差的計算,選取合適的錨幀,而不需要進行具有極大計算開銷都神經推理。錨幀計算資源分配:錨幀的計算開銷和增益都是異構并會隨著時間變化的,因此,簡單的平均分配并不能帶來優秀的表現。因此,計算資源的調度應該從錨幀的角度思考。本文提出了一個錨幀的選取算法,即從之前計算獲得的錨幀集合中,按照順序盡可能多的選取一部分錨幀,同時這些錨幀的推理時延需求要滿足一定的限制。在此之后,將錨幀進行分組,并對每組分配計算資源。編碼開銷限制:文章指出,非錨幀在接收端仍能以較低的計算開銷進行重建,因此,在媒體服務端,沒必要對非錨幀進行編碼,而錨幀所占比例較低,這極大降低了編碼的開銷。而在解碼端,該方法只引入了18% 的額外計算開銷,這與編碼開銷的降低相比,是可以接受的。GPU上下文切換:除了上述設計之外,文章還針對推理框架的切換帶來的開銷,引入了模型預優化與內存預分配,提高了整體的性能表現。>性能端對端吞吐量:如下圖所示,NeuroScaler overview相對于每一幀推斷以及其他選取的對比,吞吐量提高了10x和2x-5x。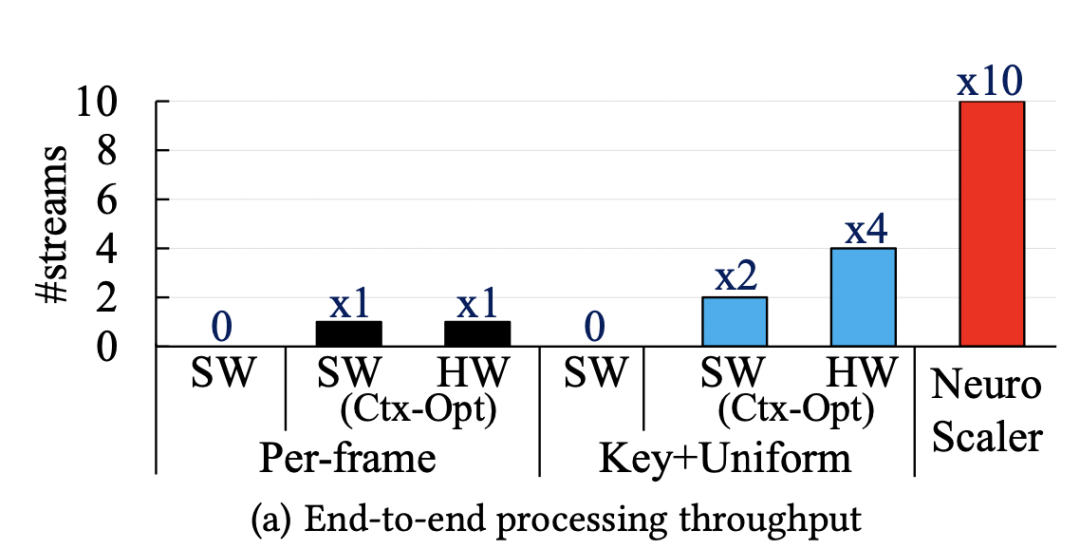 ?資源開銷:如以下兩幅圖所示,NeuroScaler的資源開銷,相較于其他的方案都較為低廉,能夠很好地滿足性能的需求。
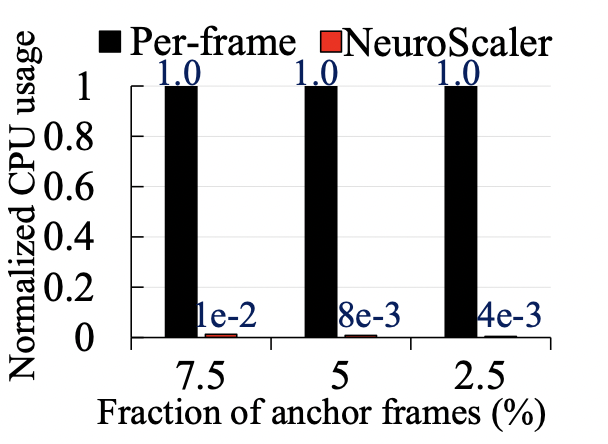
?資源開銷:如以下兩幅圖所示,NeuroScaler的資源開銷,相較于其他的方案都較為低廉,能夠很好地滿足性能的需求。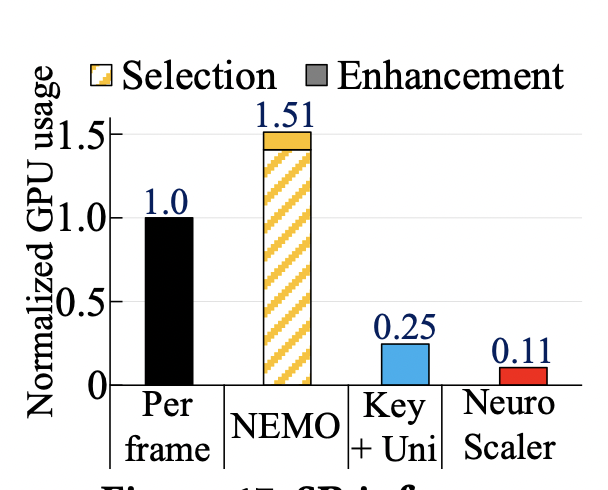
 ?>個人觀點
本文作者主要解決的是當前直播視頻流傳輸遇到的主要問題。在計算資源與傳輸資源緊張的情況下,通過選取合適的計算方法與編碼思路,可以極大減輕計算與傳輸負載。本文便采用恰當的錨幀選取算法,以較小的計算資源獲得較為優異的表現。同時,本文以接收端的解碼時間為代價,犧牲了一部分接收端的解碼速度,極大增強了媒體服務器的速度,即將整體負載分散到多個獨立的運算端上,從而獲得整體性能的提升。
?>個人觀點
本文作者主要解決的是當前直播視頻流傳輸遇到的主要問題。在計算資源與傳輸資源緊張的情況下,通過選取合適的計算方法與編碼思路,可以極大減輕計算與傳輸負載。本文便采用恰當的錨幀選取算法,以較小的計算資源獲得較為優異的表現。同時,本文以接收端的解碼時間為代價,犧牲了一部分接收端的解碼速度,極大增強了媒體服務器的速度,即將整體負載分散到多個獨立的運算端上,從而獲得整體性能的提升。LiveNet: a low-latency video transport network for large-scale live streaming
Jinyang Li, Zhenyu Li (ICT, CAS), Ri Lu, Kai Xiao, Songlin Li, Jufeng Chen, Jingyu Yang, Chunli Zong, Aiyun Chen (Alibaba Group), Qinghua Wu (ICT, CAS), Chen Sun (Alibaba Group), Gareth Tyson (Queen Mary University of London), Hongqiang Harry Liu (Alibaba Group)
本文來自阿里巴巴和中科院計算所等機構的研究者,主要報道了作者在阿里云的直播服務LiveNet的建設和運營方面所做的工作。>背景與問題 隨著新冠肺炎疫情在全球范圍內蔓延,直播已經成為日常生活的必需品。隨著新的低延遲直播用例的出現(如電子商務、工作、娛樂游戲),用戶數量顯著增長。隨著用戶期望的增長,底層傳輸系統的靈活性和可擴展性受到了挑戰。 ? 作為全球主要的CDN提供商之一,阿里巴巴的CDN擁有眾多的直播應用(如淘寶的電商直播)。多年來,這些應用程序在很大程度上得到了阿里巴巴第一代分層視頻傳輸網絡的支持(見下圖)。在該網絡中,流被傳輸到一個中央系統進行視頻加工,然后分配到邊緣節點,這些節點隨后與觀眾連接。通常,這些CDN節點使用例如應用層組播和緩存等,形成一個(多層)覆蓋樹,葉子節點服務客戶端和內部節點傳播內容到葉子。然而,這對中央處理系統和內部節點造成了巨大的壓力,它們必須根據流的數量進行伸縮。這對于有嚴格延遲約束的直播流來說尤其具有挑戰性,因為流需要兩次遍歷傳遞樹的深度。事實上,樹形結構覆蓋沒有達到低延遲直播服務對CDN延遲的嚴格要求。 ?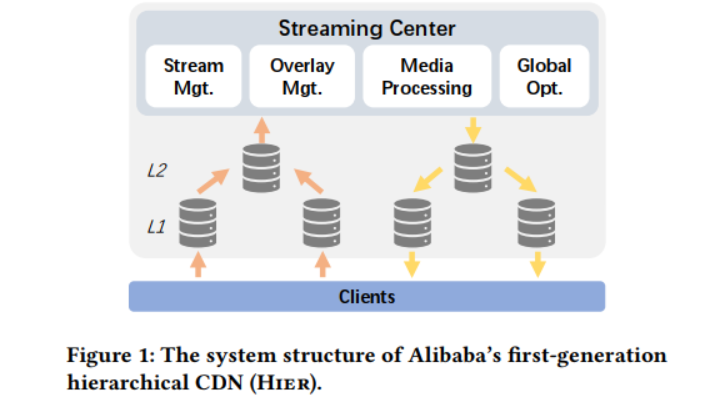 >設計
LiveNet——阿里巴巴基于扁平CDN結構的集中協調低延遲視頻網絡。下面介紹了基于作者之前的操作經驗的三個主要設計選擇:
?
為了擺脫僵化的覆蓋拓撲或節點的預先分配角色,LiveNet建立在一個平面CDN上。它的核心是一組靈活的節點(每個節點都是一組機器),它們可以服務于多個動態分配的角色:生產者(接收和處理廣播者的流),消費者(接收客戶端的請求并對流進行精細控制),以及中繼器(將消費者和生產者以任意覆蓋的拓撲結構連接起來,提供轉發和緩存等服務)。通過將各個節點與任何特定角色解耦,就可以在每個應用程序的基礎上組成最合適的覆蓋拓撲,并平均分配負載,避免了之前的中心熱點。
?
這種靈活性自然伴隨著許多資源分配和管理挑戰,特別是在大規模操作時。因此,第二個設計選擇借鑒了軟件定義網絡(SDN): 作者沒有在每個節點中嵌入控制邏輯,而是設計了一個邏輯集中的CDN控制器(流大腦),負責為節點指定角色,計算它們之間的疊加路徑,并為消費節點選擇路徑。通過在邏輯上集中管理功能,可以輕松地試驗新的拓撲和配置,以繞過有問題的節點或實現每個應用程序的策略。前兩個設計可以參考下圖。
?
>設計
LiveNet——阿里巴巴基于扁平CDN結構的集中協調低延遲視頻網絡。下面介紹了基于作者之前的操作經驗的三個主要設計選擇:
?
為了擺脫僵化的覆蓋拓撲或節點的預先分配角色,LiveNet建立在一個平面CDN上。它的核心是一組靈活的節點(每個節點都是一組機器),它們可以服務于多個動態分配的角色:生產者(接收和處理廣播者的流),消費者(接收客戶端的請求并對流進行精細控制),以及中繼器(將消費者和生產者以任意覆蓋的拓撲結構連接起來,提供轉發和緩存等服務)。通過將各個節點與任何特定角色解耦,就可以在每個應用程序的基礎上組成最合適的覆蓋拓撲,并平均分配負載,避免了之前的中心熱點。
?
這種靈活性自然伴隨著許多資源分配和管理挑戰,特別是在大規模操作時。因此,第二個設計選擇借鑒了軟件定義網絡(SDN): 作者沒有在每個節點中嵌入控制邏輯,而是設計了一個邏輯集中的CDN控制器(流大腦),負責為節點指定角色,計算它們之間的疊加路徑,并為消費節點選擇路徑。通過在邏輯上集中管理功能,可以輕松地試驗新的拓撲和配置,以繞過有問題的節點或實現每個應用程序的策略。前兩個設計可以參考下圖。
?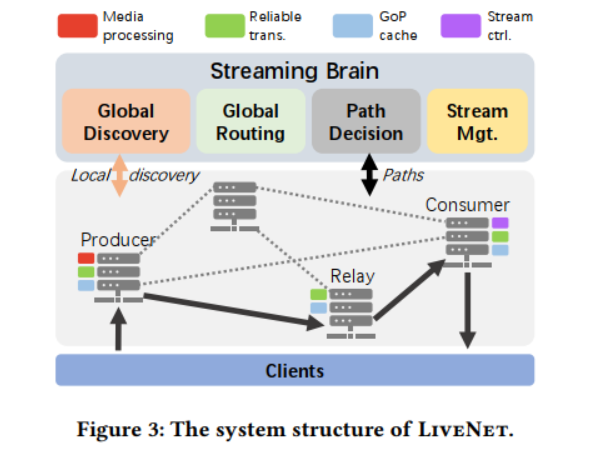 盡管上述架構允許在每一跳(例如,緩存、轉碼等)靈活地組合新的覆蓋拓撲和嵌入式服務,但它也引入了具有挑戰性的開銷。這是因為數據包必須遍歷多個軟件棧,給直播客戶帶來了不必要的延遲。為了緩解這種情況,第三種設計選擇使用了一種新穎的流轉發機制,目的是最小化端到端延遲。它基于每個節點內的兩條并行包處理路徑——一條快路和一條慢路,實現了不同協議堆棧層提供的不同功能。在該模型中,每個節點在接收到RTP數據包后,立即將其轉發到覆蓋層的下一跳,而無需執行傳統的控制功能,如丟失檢測或擁塞控制(快速路徑)。并行地,數據包的一個副本被復制到慢路徑上,這引入了擁塞控制和在快速路徑發生丟失時的丟失恢復,并在每個節點上實現GoP (Group of Pictures)緩存。這優化了LiveNet的延遲——快速路徑以盡可能快的速度交付數據包,而慢路徑提供了可靠的傳輸和內容緩存,這對快速啟動和恢復至關重要。流程可參考下圖。
?
盡管上述架構允許在每一跳(例如,緩存、轉碼等)靈活地組合新的覆蓋拓撲和嵌入式服務,但它也引入了具有挑戰性的開銷。這是因為數據包必須遍歷多個軟件棧,給直播客戶帶來了不必要的延遲。為了緩解這種情況,第三種設計選擇使用了一種新穎的流轉發機制,目的是最小化端到端延遲。它基于每個節點內的兩條并行包處理路徑——一條快路和一條慢路,實現了不同協議堆棧層提供的不同功能。在該模型中,每個節點在接收到RTP數據包后,立即將其轉發到覆蓋層的下一跳,而無需執行傳統的控制功能,如丟失檢測或擁塞控制(快速路徑)。并行地,數據包的一個副本被復制到慢路徑上,這引入了擁塞控制和在快速路徑發生丟失時的丟失恢復,并在每個節點上實現GoP (Group of Pictures)緩存。這優化了LiveNet的延遲——快速路徑以盡可能快的速度交付數據包,而慢路徑提供了可靠的傳輸和內容緩存,這對快速啟動和恢復至關重要。流程可參考下圖。
?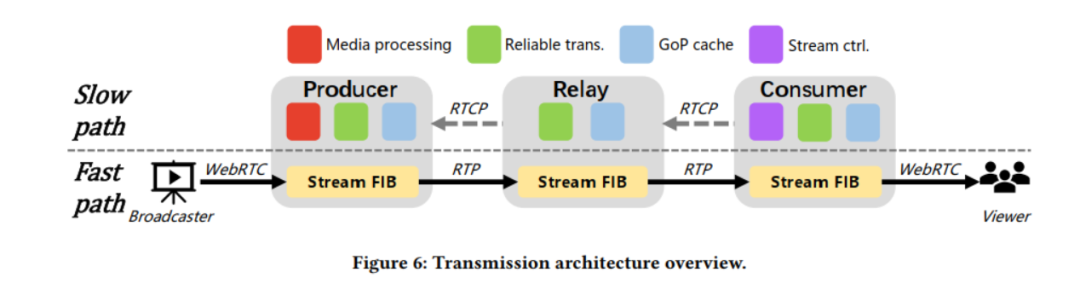 ?>性能
?
3年來,LiveNet一直是阿里巴巴低延遲流媒體技術的基礎。與之前的分層CDN相比,LiveNet將平均傳輸路徑長度(即覆蓋跳數)從4壓縮到2,并將CDN的入口和出口點之間的延遲減少了50%以上。它還顯著提高了用戶可感知的體驗:95%的視圖的啟動延遲小于1秒,98%的視圖沒有檔位。LiveNet的設計選擇和經驗教訓可以廣泛應用于其他大型流媒體場景,如視頻會議和在線教育。>個人觀點
這篇文章描述了一個名為LiveNet的新型直播傳輸網絡,它已經在阿里巴巴運營了幾年,旨在實現低延遲的同時播放高質量的視頻這兩者的平衡。此外,作為一篇經驗論文,從部署和操作LiveNet中學到的經驗教訓對學術界很有價值。論文對低延遲直播的關注對下一代在線媒體服務具有重要意義,并將激發社區在這一重要領域的更多研究。
?>性能
?
3年來,LiveNet一直是阿里巴巴低延遲流媒體技術的基礎。與之前的分層CDN相比,LiveNet將平均傳輸路徑長度(即覆蓋跳數)從4壓縮到2,并將CDN的入口和出口點之間的延遲減少了50%以上。它還顯著提高了用戶可感知的體驗:95%的視圖的啟動延遲小于1秒,98%的視圖沒有檔位。LiveNet的設計選擇和經驗教訓可以廣泛應用于其他大型流媒體場景,如視頻會議和在線教育。>個人觀點
這篇文章描述了一個名為LiveNet的新型直播傳輸網絡,它已經在阿里巴巴運營了幾年,旨在實現低延遲的同時播放高質量的視頻這兩者的平衡。此外,作為一篇經驗論文,從部署和操作LiveNet中學到的經驗教訓對學術界很有價值。論文對低延遲直播的關注對下一代在線媒體服務具有重要意義,并將激發社區在這一重要領域的更多研究。GSO-simulcast: global stream orchestration in simulcast video conferencing systems
Xianshang Lin, Yunfei Ma, Junshao Zhang, Yao Cui, Jing Li, Shi Bai, Ziyue Zhang, Dennis Cai, Hongqiang Harry Liu, Ming Zhang (Alibaba Group)
本文來自于阿里巴巴的研究者,主要研究的是大規模視頻會議系統下,傳統的方法無法同時提供1. 較好的視頻質量;2. 改善較慢參與者的表現;3.應用于任何可接入會議的設備;的問題,并嘗試使用聯播 (Simulcast) 的方式,提供一個可以任意設備接入的,具有較好的會議質量,同時不會因為較慢參與者而導致整體表現不佳的系統。>背景與問題 這個時代,在線視頻會議已經成為了一個日常生活的重要組成部分,在線會議,遠程授課等場景十分常見。而這種大規模的多方在線會議,帶來了兩個問題:1)不同的參與者,網絡狀態是不同的。2)參與者間的訂閱關系是復雜的。傳統的設計主要集中于以下三個方案:代碼轉換:代碼轉換(transcoding)可以給下游網絡路徑提供適配的視頻流,但在大規模場景中,對服務器的性能具有較高的需求,在昂貴的花銷上是不合算的。SVC:SVC可以把一個流適配到多種比特率上,但SVC的問題是它嚴重依賴于編解碼方案,而部分終端不具備對于SVC的編解碼能力。聯播:聯播 (Simulcast) 可以將視頻流編碼成多種比特率,并且并行發送。但是,傳統的聯播方法,沒有對于鏈路間和參與者的協調,流策略也不夠靈活,導致視頻和網絡之間的失配,以及大規模網絡下的低可管理性。 在傳統的設計下,聯播無法滿足大規模多方會議的需求,那么,就需要全局的信息進行參與者的協調與流策略的設置,這就帶來了以下幾個挑戰:1)如何實現實時的控制。2)如何對不同的流進行優先級的管理。3)如何獲取全局的信息。4)可以利用現有的架構進行實現。>設計 本文認為,是全局信息的缺失與流策略的僵硬,導致聯播方式的較差表現。因此,本文提出了GSO-Simulcast,通過全局信息進行流策略管理。從而滿足以下三個目標,即1)更低的鏈路擁塞。2)更少的視頻和網絡失配狀況。3)更好的流策略。為此,本文提出了一個三層的網絡架構,如下圖所示: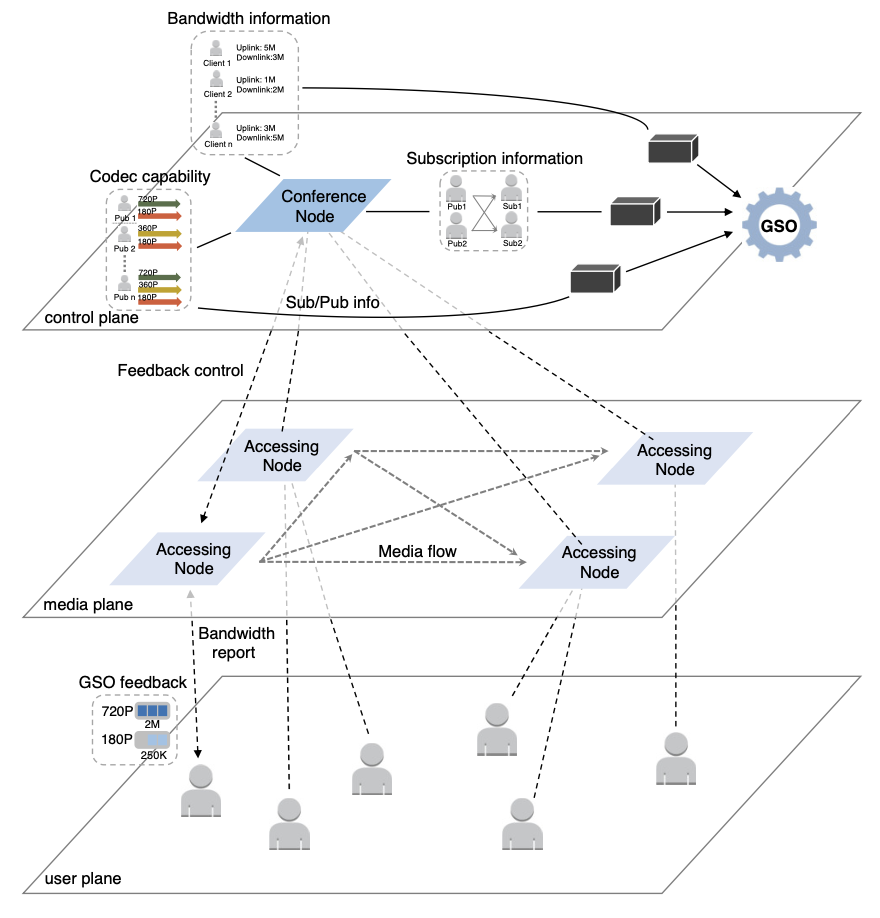 ?控制算法:本文將問題設置為一個優化問題,并以三部分作為限制條件,分別是:1)帶寬的限制。2)編解碼能力的限制。3)訂閱的限制。而這三部分,則是對應背包,合并,規約三部分算法。控制算法通過多次迭代計算,從而快速得到對應的解。獲取全局信息:為了實現中心化的方案,本文從多個方面獲取不同的全局信息:1)訂閱信息的收集可以通過信號信道進行傳播。2)編解碼信息則是在SDP協商時發送的,這包括了一些附加信息,用來收集分辨率和比特率。3)在發送端可以直接獲取帶寬信息,而在接受端則利用RTCP進行帶寬計算。反饋控制:當控制器找到了新的解決方案,則會想參與者發送控制反饋以配置流。配置流的信息是在TMMBR中攜帶的,并以TMMBN作為接受反饋。以這種帶內的方法來提高反饋的及時性。管理流:1)對于流的優先級,我們可以給一些流更高的QoE優先級,從而確保該流能被分配盡可能多的帶寬。2)對于同一個發送者的多個流,我們可以重用控制算法的第一部分,將其作為兩個獨立的流,在后續部分合并,進行統一的調度分配。>性能
GSO-Simulacst獲得了較好的性能表現。如下圖所示,(a)表示GSO-Simulcast方法具有較好的性能表現,而線性的增長表示大規模的參與者場景也具有較好的表現。(b)則表示在不同比特率下, 該方面都有較好的表現。(c)則表示,隨著比特率或者參與者的線性增長,整體的時間也是在線性增長的,也就是體現了較好的可擴展性。其中,元組被表示為(#放映者,#參與者,#比特率)。
?控制算法:本文將問題設置為一個優化問題,并以三部分作為限制條件,分別是:1)帶寬的限制。2)編解碼能力的限制。3)訂閱的限制。而這三部分,則是對應背包,合并,規約三部分算法。控制算法通過多次迭代計算,從而快速得到對應的解。獲取全局信息:為了實現中心化的方案,本文從多個方面獲取不同的全局信息:1)訂閱信息的收集可以通過信號信道進行傳播。2)編解碼信息則是在SDP協商時發送的,這包括了一些附加信息,用來收集分辨率和比特率。3)在發送端可以直接獲取帶寬信息,而在接受端則利用RTCP進行帶寬計算。反饋控制:當控制器找到了新的解決方案,則會想參與者發送控制反饋以配置流。配置流的信息是在TMMBR中攜帶的,并以TMMBN作為接受反饋。以這種帶內的方法來提高反饋的及時性。管理流:1)對于流的優先級,我們可以給一些流更高的QoE優先級,從而確保該流能被分配盡可能多的帶寬。2)對于同一個發送者的多個流,我們可以重用控制算法的第一部分,將其作為兩個獨立的流,在后續部分合并,進行統一的調度分配。>性能
GSO-Simulacst獲得了較好的性能表現。如下圖所示,(a)表示GSO-Simulcast方法具有較好的性能表現,而線性的增長表示大規模的參與者場景也具有較好的表現。(b)則表示在不同比特率下, 該方面都有較好的表現。(c)則表示,隨著比特率或者參與者的線性增長,整體的時間也是在線性增長的,也就是體現了較好的可擴展性。其中,元組被表示為(#放映者,#參與者,#比特率)。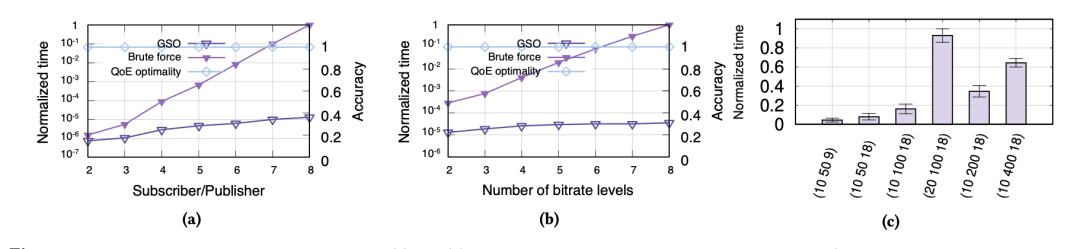 >個人觀點
本文主要解決的問題是在多方視頻會議下表現較差的問題。為了設備的兼容性,本文采用了聯播的方式進行設計,并通過多層的網絡架構與集中式的調度器進行流策略的管理。而通過不改變網絡本身的架構,該系統得到了較好的表現。但是,本文的整體設計主要依賴于集中式的控制器,而將其推廣到分布式的設計也是一個可行的思路。
>個人觀點
本文主要解決的問題是在多方視頻會議下表現較差的問題。為了設備的兼容性,本文采用了聯播的方式進行設計,并通過多層的網絡架構與集中式的調度器進行流策略的管理。而通過不改變網絡本身的架構,該系統得到了較好的表現。但是,本文的整體設計主要依賴于集中式的控制器,而將其推廣到分布式的設計也是一個可行的思路。編輯:黃飛














 工商網監
工商網監
評論