 電子發燒友App
電子發燒友App


? ? 本文由斯坦福大學和普林斯頓大學合作完成。這篇文章聚焦于網絡中的計算,提出網絡計算的核心是較快地獲得正確的結果,因此要建立以計算為中心的網絡。這個工作設計并實現了一個名為Fixpoint的框架,并在初步的測試中獲得了較好的表現。
? ? >背景
? ? 云計算是當前很多大規模應用的解決方案,但是之前的設計殘留著一些問題,包括1)計算關系的模糊性,即對于多個組件而言,他們的計算順序是未知的。2)服務端算法不確定性,即針對同一種用戶行為,可復現性收到懷疑。3)低可重用性,即面臨代碼或者數據的更改,計算的結果可能會有不同。4)以及服務端不明晰計算依賴與程序關系帶來的較慢計算速度,即浪費了過多的時間在I/O上,導致整體性能出現了嚴重的降低。這些問題導致云設施無法較好地滿足租用者的需求。
? ? >設計
? ? 本文實現了一個名為Fixpoint的計算框架,并在此內定義了一個輕量級的數據上計算(computation on data)的語言,以提供在各平臺上可用性。本文認為這種以計算為核心的網絡設計能夠從細粒度的可見性,對于正確性客觀的評價以及I/O的分離與對不確定性的描繪這些因素中得到提高表現的方法。
? ? 因此,本文提出,云計算較好表現需要網絡系統,1)能夠追蹤計算的關系。2)能確保在同樣的用戶行為下,服務端提供的數據是相同的。3)允許在數據或者代碼發生變化后,仍能允許。4)能夠較為靈活地進行任務的讀取與放置,加快處理的速度。
? ? 除此之外,Fixpoint的設計還遵循以下幾種假設:
I/O和計算的分離是可以廣泛取得的。
非確定性的內容是可以被復現的
程序的執行不會帶來較大的性能開銷。
效率的提高對于服務 提供商和用戶雙方都是有好處的。
? 在這些假設的基礎上,本文設計了在數據上計算的語言Fix,并實現了Fixpoint的原型。
? ? >評估
? ? 本文在8-bit的加法程序上做了簡單的實驗。該工作一共選取了6個不同的加法函數,3個是簡單的函數,另外三個是POSIX的程序。每一個設置均進行了4096次的實驗。實驗結果表明,在簡單的加法操作中,Fixpoint以虛函數調用五倍的開銷完成了整體的操作,而在POSIX下,他比傳統的方法好上很多,比Linuxvfork快37倍,而當vfork發生在內部rr中時,它的速度約為531倍,該結果如下圖。
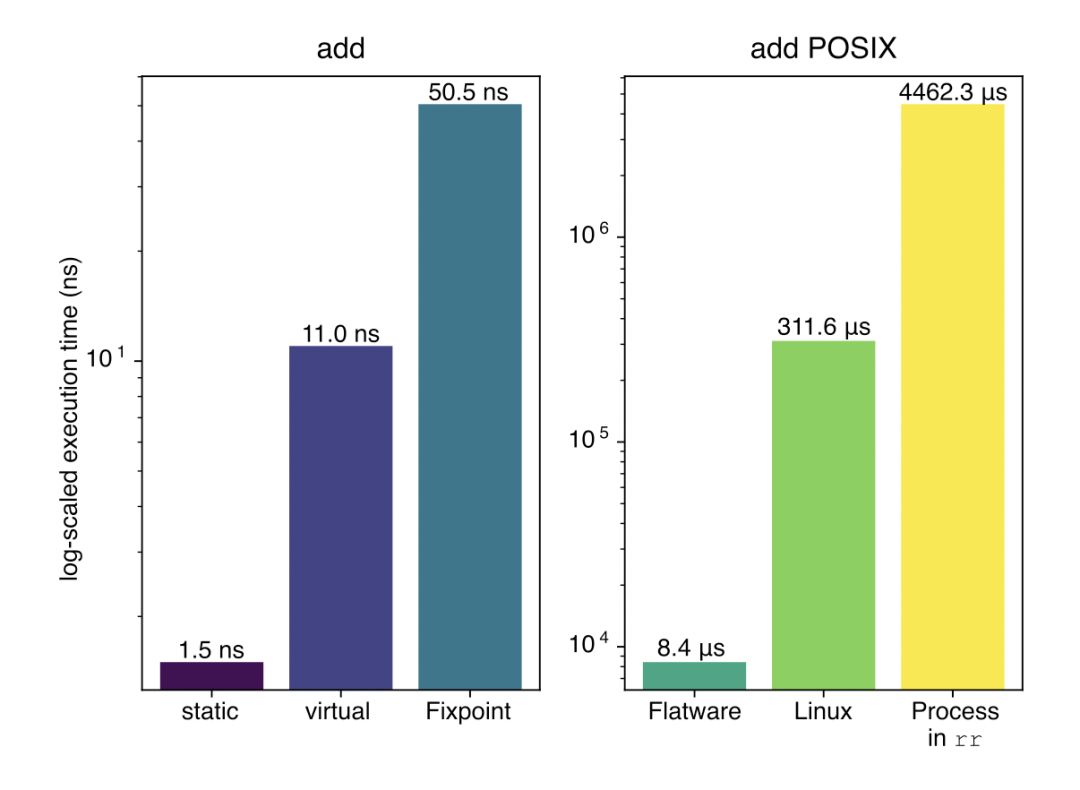
?
>觀點
Fixpoint實現了一個較為完整的框架,通過獲取數據流的詳細信息來進行任務的處理,在網絡程序中有著較好的表現。將具體的計算以及計算關系考慮在網絡與通信里,是提升整體表現的一個突破點。 ?
Rethinking Cloud-hosted Financial Exchanges for Response Time Fairness
Prateesh Goyal, Ilias Marinos (Microsoft Research); Eashan Gupta (Microsoft Research, UIUC); Chaitnya Bandi (Microsoft Research); Alan Ross (Microsoft); Ranveer Chandra (Microsoft Research)
? 本文由來自微軟和UIUC的研究者合作完成。本文的考慮重點是相應時間的公平性,即對于客戶端的響應時間,以一種新的方式進行排序,并根據這種排序依次提供服務。這種設置可以滿足市場參與者的公平性需求,緩解網絡延遲對于金融交易產生的影響。 ?
>背景
? 現代的金融交易服務是通過網絡提供的。很多金融交易所會在他們內部的數據中心上運行中心交換服務器(CES),而CES則會產生市場數據并進行分發。市場參與者會根據這些市場數據作出反應。這種交易的利潤極大來自于高速反映,因此很多交易者采用各種方法減少網絡延遲。因此,對于市場來說,減少網絡對于交易的公平性是極為重要的。與此同時,將CES帶到云端能在給云服務提供商帶來更大的機會的同時,也帶來一系列挑戰,突出的便是不同延遲帶來的公平性,傳統的高精度時鐘和排序聚合的方式也都有著較大的限制。
? >設計
本文認為限制CES和市場參與者(MP)間的延遲是一個有效的方法,但是難以實現,并且并不必要。而通過獲取市場數據并作出決策這種形式,我們也可以根據每個參與者做出反應所需的時間,進行相應的排序工作,從而確保公平性。 ? 整體的架構如下圖所示,對于每一個MP而言,他們都和一個RB相關聯,而RB則是直接從CES中獲取市場信息。每一個MP會根據市場信息作出決策,將交易信息發送給RB,RB會將一定的順序信息和交易信息綁定,讓CES據此進行排序,從而獲得公平性。 ?
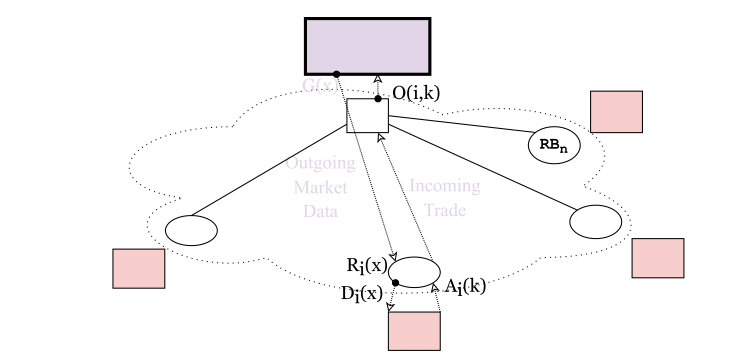
構建系統需要滿足以下假設: ?
RB和MP在地理位置上很近,因此他們之間的時延不會影響到公平性。
RB和CES間通過可靠數據連接TCP進行通信。
考慮到成熟的備份方案,我們認為CES和RB不會出現實效的問題。
? 考慮到實際的使用,本為提供了幾類公平性分類:
強公平性
所有MP的任務都是按順序的,且相同市場數據的交易訂單會根據響應時間進行排序。
受限的公平性
不要求同一個MP的所有任務都是按順序相應的。針對某一個相同的市場數據,如果某個MP響應時間在一定的限制內,那么只要比其他MP響應時間更短。就會被先執行。
近似公平性
對于同一個市場數據,只要某個MP響應時間比另一個MP的快一定的范圍內,就會被先執行。
? >評估
本文在兩種場景做了測試。分別是受限公平下的設置以及RB間有同步時鐘的設置。針對RB間擁有的同步時鐘的場景,在出現延遲尖峰時,則會從強公平性變為近似公平性,以提供性能保證。模擬試驗結果表示,和傳統的CloudEx相比,場景1獲得了更好的延遲,在一定的響應時間內,獲得了完美的公平性,但當響應時間增大時,公平性會降低。而場景2的延遲更大一些,場景2是通過犧牲一定的延遲來獲得理想的公平性,同時,他對于延遲峰值的處理比CloudEX更好一些。 ?
>觀點
? 本文將金融交易的實際場景面臨的挑戰和網絡架構的關系結合在一起,通過邏輯設置而不是對于架構的硬性更改獲得了較好的表現,并提出集中公平性的限制方法,來獲得較好的表現。關于本文,可以進一步探究公平性的影響以及架構方面的設置,獲取更安全的公平性。 ?
Load Balancers Need In-Band Feedback Control
Bhavana Vannarth Shobhana, Srinivas Narayana, Badri Nath (Rutgers University)
? 這篇文章是由來自羅格斯大學的研究者完成的,該文章的著眼點是精細化的服務下,如何通過負載均衡來提高服務的性能與可用性。本文認為負載均衡需要調整請求路由以適應快速變化的服務器性能來主動優化應用程序響應時間,因此提出使用帶內反饋控制的方法來優化端到端的延遲。 ?
>背景
負載均衡(LB)是將負載均勻分布在不同服務器,以獲得較好的服務表現和服務可用性的技術,這種技術能避免大批量的請求集中在某幾臺服務器,造成服務質量的降低。但是,隨著微服務、無服務與機架規模計算的出現,在較小的時間維度上也會出現嚴重的服務降級問題,與此同時,傳統的一些方法例如請求重復、需求驅動的規模調整往往不能起到應有的作用。 ?
>設計 ? 現在的網絡設計中有著以下幾種問題: ?
缺乏對于網絡時延細粒度的探究
現在的微服務等應用涉及了多個服務器的響應,而最慢的微服務是整體服務響應時間的瓶頸。而相比較與執行較快但有著阻塞路徑的服務器,選擇較慢但路徑負載較低的服務器可能會更好。 ?
服務器性能的可變性
隨著時間的推移,服務器的性能會發生變化,典型的方法耗費了太多的時間。 ?
需要應用的修改
獲取帶外的信息來調整請求路由也許很有效,但對于應用程序的修改會帶來極大的挑戰性。 ?
無法獲取響應信息
很多響應信息會繞過LB,導致LB無法根據響應信息進行調整。 ? 為了解決這些問題,本文設計了一個帶內控制系統,以達到: ?
將網絡和服務器處理延遲納入請求路由決策。
對服務器性能變化做出快速反應。
使用純本地觀察,避免需要修改應用程序或外部存儲。
只觀察從客戶端到服務器的一個方向的流量。
同時能滿足標準LB要求。
? 優化端到端的響應延遲是整體性能提升的重點。而在LB場景下分為4部分,分別是:
用戶端到LB的時延。
LB到服務端的時延。
服務端到LB的時延。
LB到客戶端的時延。
? 很明顯,評價性能指標,可以從LB和服務端的往返時延來分析。當然,3)的時延很有可能無法觀測到。因此,我們需要分析相應觸發的新的傳輸,以判斷往返的時延, 如下圖。
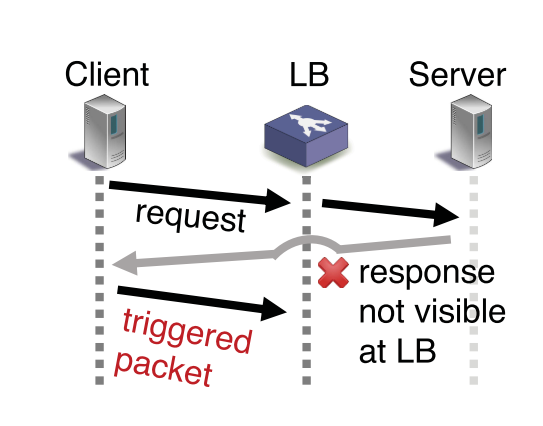
除此之外,在測量的過程中,會有這兩個問題,一個是LB測量的時間和響應時延不同,另一個是LB不清楚是被觸發的包是被哪一個觸發的,如下圖。
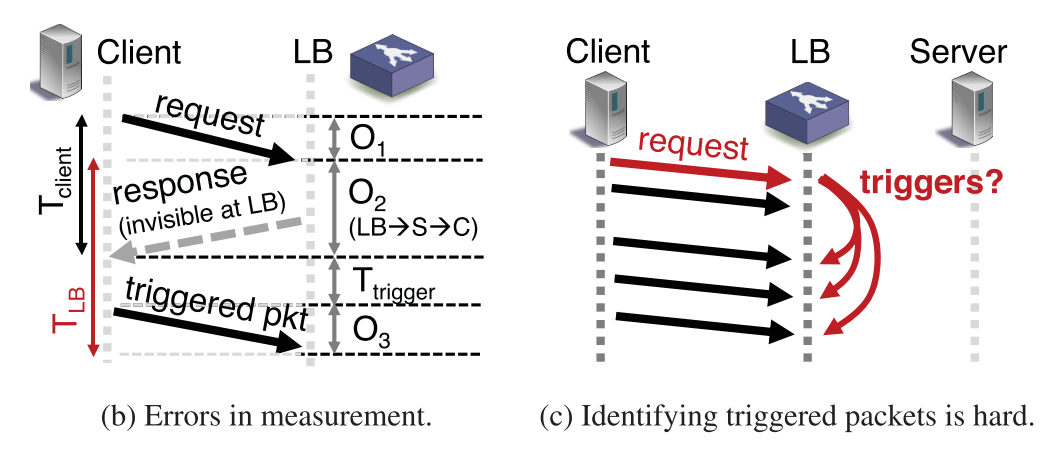
因此,對于時間的測量,一方面要計算出正確的時間,另一方面可以通過傳輸的間隔來識別被觸發的傳輸。 ? 在LB識別不同的負載LB后,則會執行一個簡單的負載均衡算法,將最擁塞的服務器上的部分負載均分到其他的服務器上。 ?
>評估
本文做了簡單的時延,實驗結果如下圖所示。從實驗結果可以看到,與傳統的方法相比,該方法在后續仍保持著較低的延遲。
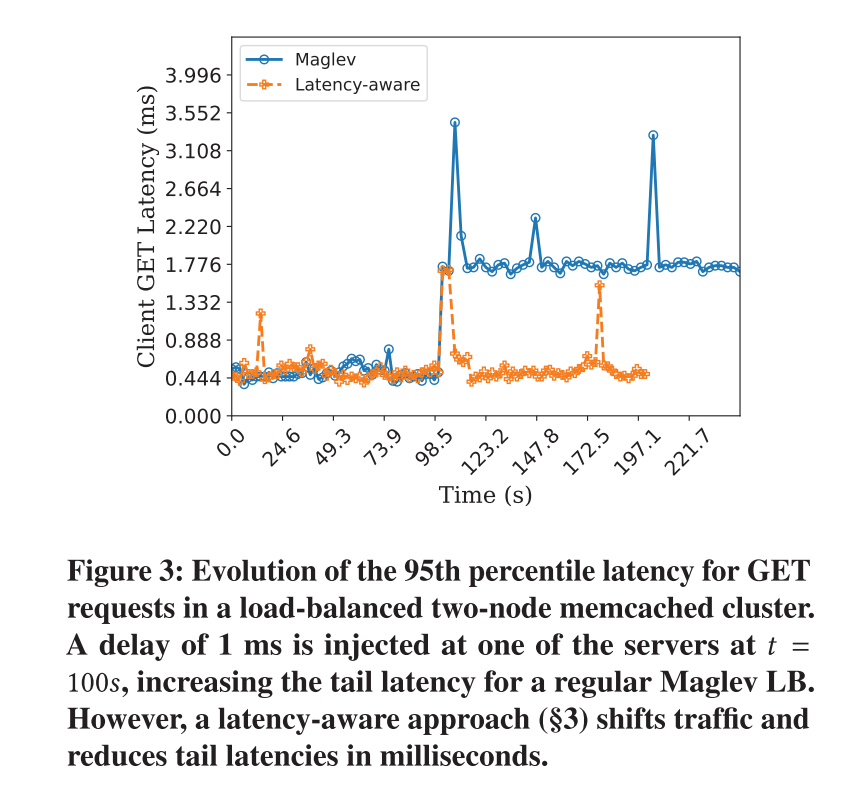
?
>個人觀點
本文以帶內控制的思想進行負載均衡的調度,在較長時間的維度上仍能獲得較好的表現。可以考慮將應用的場景抽象成協同流等的方式,進一步提高服務的性能。
編輯:黃飛
?













 工商網監
工商網監
評論