 電子發燒友App
電子發燒友App


RoCE(RDMA over Converged Ethernet)協議是一種能在以太網上進行RDMA(遠程內存直接訪問)的集群網絡通信協議,它大大降低了以太網通信的延遲,提高了帶寬的利用率,相比傳統的TCP/IP協議的性能有了很大提升。本文將聊一聊我對于將RoCE應用到HPC上這件事的看法。
HPC網絡的發展與RoCE的誕生
在早年的高性能計算(HPC)系統中,往往會采用一些定制的網絡解決方案,例如:Myrinet、Quadrics、InfiniBand,而不是以太網。這些網絡可以擺脫以太網方案在設計上的限制,可以提供更高的帶寬、更低的延遲、更好的擁塞控制、以及一些特有的功能。
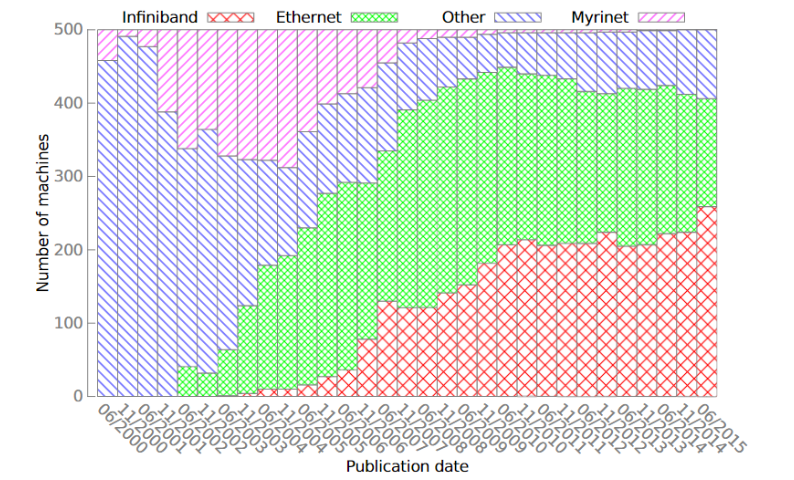
IBTA在2010年發布了RoCE(RDMA over Converged Ethernet)協議技術標準,隨后又在2014年發布了RoCEv2協議技術標準,同時帶寬上也有大幅提升。以太網性能的大幅提升,使越來越多的人想要選擇能兼容傳統以太網的高性能網絡解決方案。這也打破了top500上使用以太網的HPC集群數量越來越少的趨勢,使以太網現在仍然占有top500的半壁江山。 ? 雖然現在Myrinet、Quadrics已經消亡,但InfiniBand仍然占據著高性能網絡中重要的一席之地,另外Cray自研系列網絡,天河自研系列網絡,Tofu D系列網絡也有著其重要的地位。 ?
RoCE協議介紹
RoCE協議是一種能在以太網上進行RDMA(遠程內存直接訪問)的集群網絡通信協議。它將收/發包的工作卸載(offload)到了網卡上,不需要像TCP/IP協議一樣使系統進入內核態,減少了拷貝、封包解包等等的開銷。這樣大大降低了以太網通信的延遲,減少了通訊時對CPU資源的占用,緩解了網絡中的擁塞,讓帶寬得到更有效的利用。
RoCE協議有兩個版本:RoCE v1和RoCE v2。其中RoCE v1是鏈路層協議,所以使用RoCEv1協議通信的雙方必須在同一個二層網絡內;而RoCE v2是網絡層協議,因此RoCE v2協議的包可以被三層路由,具有更好的可擴展性。
RoCE v1協議
RoCE協議保留了IB與應用程序的接口、傳輸層和網絡層,將IB網的鏈路層和物理層替換為以太網的鏈路層和網絡層。在RoCE數據包鏈路層數據幀中,Ethertype字段值被IEEE定義為了0x8915,來表明這是一個RoCE數據包。但是由于RoCE協議沒有繼承以太網的網絡層,在RoCE數據包中并沒有IP字段,因此RoCE數據包不能被三層路由,數據包的傳輸只能被局限在一個二層網絡中路由。
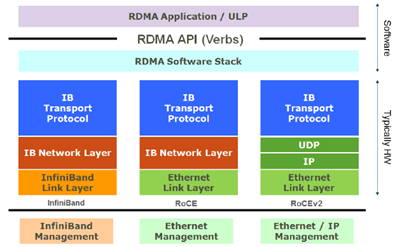
RoCEv2協議
RoCE v2協議對RoCE協議進行了一些改進。RoCEv2協議將RoCE協議保留的IB網絡層部分替換為了以太網網絡層和使用UDP協議的傳輸層,并且利用以太網網絡層IP數據報中的DSCP和ECN字段實現了擁塞控制的功能。因此RoCE v2協議的包可以被路由,具有更好的可擴展性。由于RoCE v2協議現在已經全面取代存在缺陷的RoCE協議,人們在提到RoCE協議時一般也指的是RoCE v2協議,故本文中接下來提到的所有RoCE協議,除非特別聲明為第一代RoCE,均指代RoCE v2協議。
無損網絡與RoCE擁塞控制機制
在使用RoCE協議的網絡中,必須要實現RoCE流量的無損傳輸。因為在進行RDMA通信時,數據包必須無丟包地、按順序地到達,如果出現丟包或者包亂序到達的情況,則必須要進行go-back-N重傳,并且期望收到的數據包后面的數據包不會被緩存。
RoCE協議的擁塞控制共有兩個階段:使用DCQCN(Datacenter Quantized Congestion Notification)進行減速的階段和使用PFC(Priority Flow Control)暫停傳輸的階段(雖然嚴格來說只有前者是擁塞控制策略,后者其實是流量控制策略,但是我習慣把它們看成擁塞控制的兩個階段,后文中也這會這么寫)。 ? 當在網絡中存在多對一通信的情況時,這時網絡中往往就會出現擁塞,其具體表現是交換機某一個端口的待發送緩沖區消息的總大小迅速增長。如果情況得不到控制,將會導致緩沖區被填滿,從而導致丟包。因此,在第一個階段,當交換機檢測到某個端口的待發送緩沖區消息的總大小達到一定的閾值時,就會將RoCE數據包中IP層的ECN字段進行標記。當接收方接收到這個數據包,發現ECN字段已經被交換機標記了,就會返回一個CNP(Congestion Notification Packet)包給發送方,提醒發送方降低發送速度。 ? 需要特別注意的是,對于ECN字段的標記并不是達到一個閾值就全部標記,而是存在兩個Kmin和Kmax,如圖2所示,當擁塞隊列長度小于Kmin時,不進行標記。當隊列長度位于Kmin和Kmax之間時,隊列越長,標記概率越大。當隊列長度大于Kmax時,則全部標記。而接收方不會每收到一個ECN包就返回一個CNP包,而是在每一個時間間隔內,如果收到了帶有ECN標記的數據包,就會返回一個CNP包。這樣,發送方就可以根據收到的CNP包的數量來調節自己的發送速度。
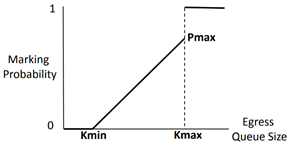
當網絡中的擁塞情況進一步惡化時,交換機檢測到某個端口的待發送隊列長度達到一個更高的閾值時,交換機將向消息來源的上一跳發送PFC的暫停控制幀,使上游服務器或者交換機暫停向其發送數據,直到交換機中的擁塞得到緩解的時候,向上游發送一個PFC控制幀來通知上有繼續發送。由于PFC的流量控制是支持按不同的流量通道進行暫停的,因此,當設置好了每個流量通道帶寬占總帶寬的比例,可以一個流量通道上的流量傳輸暫停,并不影響其他流量通道上的數據傳輸。 ? 值得一提的是,并不是每一款聲稱支持RoCE的交換機都完美的實現了擁塞控制的功能。在我的測試中,發現了某品牌的某款交換機的在產生擁塞時,對來自不同端口但注入速度相同的流量進行ECN標記時概率不同,導致了負載不均衡的問題。
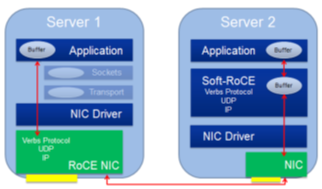
RoCE和Soft-RoCE
雖然現在大部分的高性能以太網卡都能支持RoCE協議,但是仍然有一些網卡不支持RoCE協議。因此IBM、Mellanox等聯手創建了開源的Soft-RoCE項目。這樣,在安裝了不支持RoCE協議的網卡的節點上,仍然可以選擇使用Soft-RoCE,使其具備了能與安裝了支持RoCE協議的網卡的節點使用RoCE協議進行通信的能力,如圖3所示。雖然這并不會給前者帶來性能提升,但是讓后者能夠充分發揮其性能。在一些場景下,比如:數據中心,可以只將其高IO存儲服務器升級為支持RoCE協議的以太網卡,以提高整體性能和可擴展性。同時這種RoCE和Soft-RoCE結合的方法也可以滿足集群逐步升級的需求,而不用一次性全部升級。
將RoCE應用到HPC上存在的問題
HPC網絡的核心需求
我認為HPC網絡的核心需求有兩個:①低延遲;②在迅速變化的流量模式下仍然能保持低延遲。
對于①低延遲,RoCE就是用來解決這個問題的。如前面提到的,RoCE通過將網絡操作卸載到網卡上,實現了低延遲,也減少了CPU的占用。 ? 對于②在迅速變化的流量模式下仍然能保持低延遲,其實就是擁塞控制的問題。但是關鍵在于HPC的流量模式是迅速變化的,而RoCE在這個問題上表現是欠佳的。
RoCE的低延遲
實機測試
RoCE的延遲有幸有機會與IB實測對比了一下:以太網用的是25G Mellanox ConnectX-4 Lx 以太網卡,和Mellanox SN2410交換機;IB用的是100G InfiniBand EDR網卡(Mellanox ConnectX-4),和Mellanox CS7520。測試中以太網交換機擺位于機架頂部,IB交換機擺在比較遠的機柜,因而IB的會因為線纜的實際長度較長而有一點劣勢。測試使用OSU Micro-Benchmarks中的osu_latency對IB、RoCE、TCP協議進行延遲測試,結果如下。
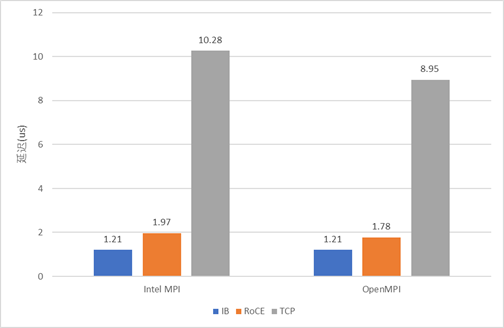
雖然IB用的是100G的,RoCE用的是25G的,但是這里我們關注的是延遲,應該沒有關系。 ? 可以看出,雖然RoCE協議的確能大幅降低通信延遲,比TCP快了5倍左右,但仍然比IB慢了47%-63%。
官方紙面數據
上面用到的以太網交換機SN2410的官方延遲數據是300ns,雖然IB交換機CS7520沒找到官方延遲數據,不過找到了同為EDR交換機的SB7800的官方數據,延遲為90ns。 ? 不過上面這些是有些舊的前兩年的設備了,新一點的Mellanox以太網交換機SN3000系列的200G以太網交換機官方延遲數據是425ns,更新的Mellanox SN4000系列400G以太網交換機,在官方文檔沒有找到延遲數據。新一點的Mellanox IB交換機QM8700系列HDR交換機的官方延遲數據是130ns,最新的QM9700系列NDR交換機,在官方文檔中也沒有找到延遲數據。(不知道為啥都是新一代的比舊的延遲還大一點,而且最新一代的延遲都沒放出來) ? 定制網絡的Cray XC系列Aries交換機延遲大約是100ns,天河-2A的交換機延遲也大約是100ns。 ? 可見在交換機實現上,以太網交換機與IB交換機以及一些定制的超算網絡的延遲性能還是有一定差距的。
RoCE的包結構
假設我們要使用RoCE發送1 byte的數據,這時為了封裝這1 byte的數據包要額外付出的代價如下:
以太網鏈路層:14 bytes MAC header + 4 bytes CRC
以太網IP層:20 bytes
以太網UDP層:8 bytes
IB傳輸層:12 bytes Base Transport Header (BTH)
總計:58 bytes
假設我們要使用IB發送1 byte的數據,這時為了封裝這1 byte的數據包要額外付出的代價如下:
IB鏈路層:8 bytes Local Routing Header(LHR) + 6 byte CRC
IB網絡層:0 bytes 當只有二層網絡時, 鏈路層Link Next Header (LNH)字段可以指示該包沒有網絡層
IB傳輸層:12 bytes Base Transport Header (BTH)
總計:26 bytes 如果是定制的網絡,數據包的結構可以做到更簡單,比如天河-1A的Mini-packet (MP)的包頭是有8 bytes。 ? 由此可見,以太網繁重的底層結構也是將RoCE應用到HPC的一個阻礙之一。 ? 數據中心的以太網交換機往往還要具備許多其他功能,還要付出許多成本來進行實現,比如SDN、QoS等等,這一塊我也不是很懂。 ? 對于這個以太網的這些features,我挺想知道:以太網針這些功能與RoCE兼容嗎,這些功能會對RoCE的性能產生影響嗎?
RoCE擁塞控制存在的問題
RoCE協議的兩段擁塞控制都存在一定的問題,可能難以在迅速變化的流量模式下仍然能保持低延遲。
采用PFC(Priority Flow Control)采用的是暫停控制幀來防止接收到過多的數據包從而引起丟包。這種方法比起credit-based的方法,buffer的利用率難免要低一些。由其對于一些延遲較低的交換機,buffer會相對較少,此時用PFC(Priority Flow Control)就不好控制;而如果用credit-base則可以實現更加精確的管理。 ? DCQCN與IB的擁塞控制相比,其實大同小異,都是backward notification:通過通過先要將擁塞信息發送到目的地,然后再將擁塞信息返回到發送方,再進行限速。但是在細節上略有不同:RoCE的降速與提速策略根據論文Congestion Control for Large-Scale RDMA Deployments,是固定死的一套公式;而IB中的可以自定義提速與降速策略;雖然大部分人應該實際上應該都用的是默認配置,但是有自由度總好過沒有叭。還有一點是,在這篇論文中測試的是每N=50us最多產生一個CNP包,不知道如果這個值改小行不行;而IB中想對應的CCTI_Timer最小可以為1.024us,也不知道實際能不能設置這么小。 ? 最好的方法當然還是直接從擁塞處直接返回擁塞信息給源,即Forward notification。以太網受限于規范不這么干可以理解,但是IB為啥不這么干呢?
RoCE在HPC上的應用案例
Slingshot
美國的新三大超算都準備用Slingshot網絡,這是一個改進的以太網,其中的Rosetta交換機兼容傳統的以太網同時還對RoCE的一些不足進行了改進,如果一條鏈路的兩端都是支持的設備(專用網卡、Rosetta交換機)就可以開啟一些增強功能:
將IP數據包最小幀大小減小到32 bytes
相鄰交換機的排隊占用情況(credit)會傳播給相鄰的交換機
更加nb的擁塞控制,但是具體怎么實現的論文里沒細說
最后達到的效果是交換機平均延遲是350ns,達到了較強的以太網交換機的水平,但是還沒沒有IB以及一些定制超算交換機延遲低,也沒有前一代的Cray XC超算交換機延遲低。 ? 但是在實際應用的表現似乎還行,但是論文An In-Depth Analysis of the Slingshot Interconnect中似乎只是和前一代的Cray超算比,沒有和IB比。
CESM與GROMACS測試
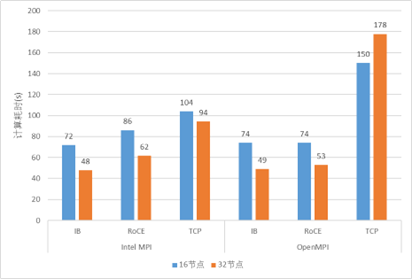
我也用前面測試延遲的25G以太網和100G測了CESM與GROMACS來對比了應用的性能。雖然兩者之間帶寬差了4倍,但是也有一點點參考價值。
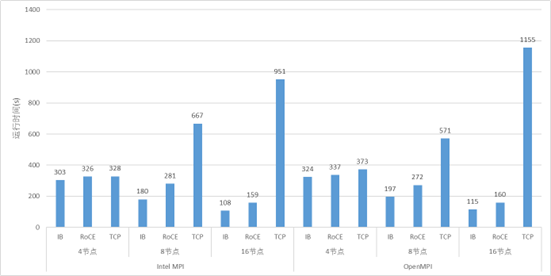
GROMACS測試結果
一些期待
如果能有人將100G或者200G的IB和以太網組一個大規模集群來對比兩者之間的性能差距,其實就能說明很多問題,但是成本實在太高,到目前為止還沒發現有哪里做了這樣的實驗。
總結與結論
將RoCE應用到HPC中有我覺得如下問題:
以太網交換機的延遲相比于IB交換機以及一些HPC定制網絡的交換機要高一些
RoCE的流量控制、擁塞控制策略還有一些改進的空間
以太網交換機的成本還是要高一些
但是從實測性能上來看,在小規模情況下,性能不會有什么問題。但是在大規模情況下,也沒人測過,所以也不知道。雖然Slingshot的新超算即將出來了,但是畢竟是魔改過的,嚴格來說感覺也不能算是以太網。但是從他們魔改這件事情來看,看來他們也覺得直接應用RoCE有問題,要魔改了才能用。
編輯:黃飛
?




















 工商網監
工商網監
評論