 電子發燒友App
電子發燒友App


來源?| OSCHINA 社區
作者 | 華為云開發者聯盟
本文分享自華為云社區《重識云原生系列(四) —— 硬菜軟嚼的云網絡》,作者:黃俊 / 招商證券云原生轉型項目調研負責人。 在傳統 IT 架構中,網絡幾乎就是指物理網絡設備,觸手可及,服務器之間的網絡通訊也是通過網線或者光纖連接實現,其大部分流量管控與訪問控制策略也都是在路由器 / 交換機實現。而到了云計算時代,網絡,除了包含傳統的物理硬件設備,還包含大量虛擬化的網絡設備軟件應用,其運行在普通服務器中。而虛擬網絡設備的連通,不僅需要底層真實硬件的支持,更需要關注軟件形態的虛擬網絡設備中的各種 Overlay 層的轉發策略與流量監測,這對網絡管理員而言也是前所未有的挑戰。
伴生于云計算的云網絡技術
云計算時代,資源的虛擬化和調配的自動化,為用戶提供了可彈性伸縮、靈活配置的計算、存儲資源,進而支持快速簡便的業務系統發布。作為互聯互通的網絡基礎設施,如何實現網絡設備的虛擬化,從而進一步支持業務系統的快速擴縮容和網絡通訊策略的自適應調配,為業務系統提供端到端的網絡快速響應方案,成為了云計算時代急需解的核心關鍵問題。本質上講,云網絡技術就是要實現對數據中心底層物理網絡設備的抽象,以期能在軟件層實現對網絡資源的二次切分、整合或者靈活管控,以便快速靈活地滿足各種業務場景的網絡使用需求,此即是軟件定義網絡(SDN)技術誕生的初衷。 云網絡技術發展至今,就是以云為中心,一方面為支撐數據中心基礎設施全面虛擬化而發展出來的網絡硬件的虛擬化能力,此方面的能力表現為可標準化快速組網、可按需擴展網絡資源容量、可靈活調配網絡安全管控策略、支持計量計費、可全棧監控等;另一方面,因為公有云的蓬勃發展,也孕育出了面向企業租戶的云上網絡類產品與服務,通過對機房級通用網絡設備或功能的模擬,以軟件產品服務的方式提供給云上用戶使用。
云網絡基礎技術演進
就云網絡基礎技術而言,其與計算虛擬化技術類似,也走過了一條精彩紛呈的硬件 “軟化” 之路。
一切從 Spine-Leaf 架構說起
自從 1876 年電話被發明之后,電話交換網絡歷經了人工交換機、步進制交換機、縱橫制交換機等多個階段,而隨著電話用戶數量急劇增加,網絡規模快速擴大,基于 crossbar 模型的縱橫制交換機在能力和成本上都已無法滿足要求。1953 年,貝爾實驗室有一位名叫 Charles Clos 的研究員,發表了一篇名為《A Study of Non-blocking Switching Networks》的文章,介紹了一種 “用多級設備來實現無阻塞電話交換” 的方法,著名的 CLOS 網絡模型就此誕生,其核心思想是 —— 用多個小規模、低成本的單元,構建復雜、大規模的網絡,如下圖所示: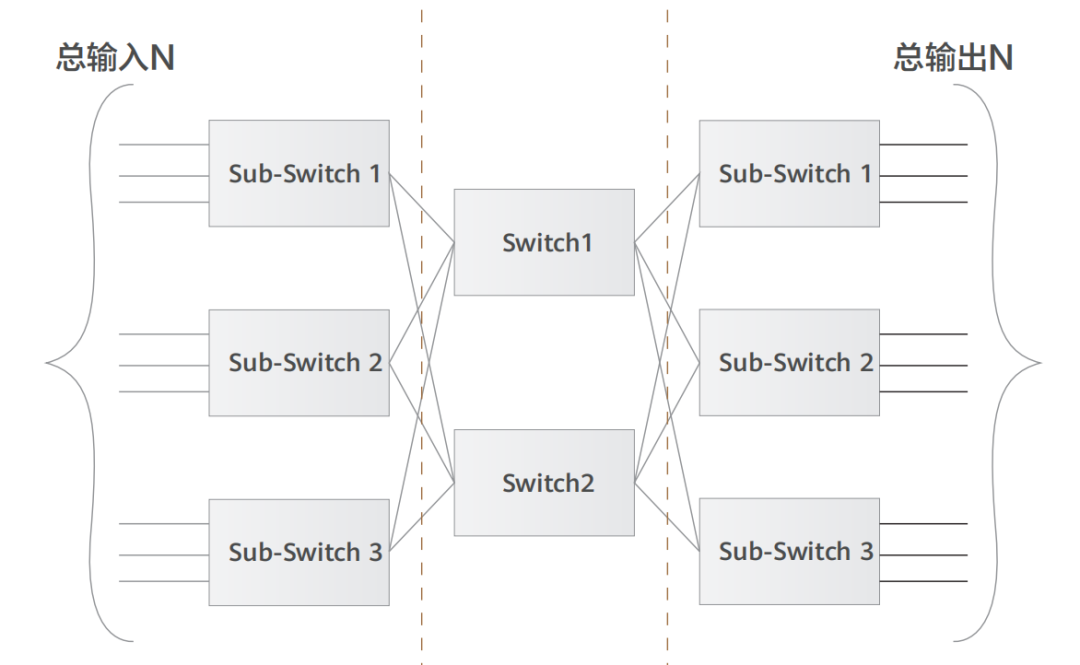 圖中的矩形,都是低成本的轉發單元。當輸入和輸出增加時,中間的交叉點并不需要增加很多。而到了 20 世紀 80 年代,隨著計算機的大量使用,計算機網絡技術也得到了長足的進步,開始出現各種網絡拓撲結構,例如星型、鏈型、環型、樹型結構,最終樹型網絡成為了行業主流架構,不過早期的樹型結構網絡帶寬是收斂的。2000 年之后,互聯網從經濟危機中復蘇,以谷歌和亞馬遜為代表的互聯網巨頭迅速崛起。他們開始推行云計算技術,大量建設數據中心(IDC),甚至超級數據中心。面對日益龐大的計算集群規模,傳統樹型網絡已無法滿足要求,便誕生了一種改進型樹型網絡 —— 胖樹(Fat-Tree)架構。相比于傳統樹型,胖樹(Fat-Tree)更像是真實的樹,越到樹根,枝干越粗(其實是指帶寬)。從葉子到樹根,網絡帶寬無須收斂。胖樹架構被引入到數據中心之后,數據中心便發展成了傳統的三層結構(如下圖所示)。
圖中的矩形,都是低成本的轉發單元。當輸入和輸出增加時,中間的交叉點并不需要增加很多。而到了 20 世紀 80 年代,隨著計算機的大量使用,計算機網絡技術也得到了長足的進步,開始出現各種網絡拓撲結構,例如星型、鏈型、環型、樹型結構,最終樹型網絡成為了行業主流架構,不過早期的樹型結構網絡帶寬是收斂的。2000 年之后,互聯網從經濟危機中復蘇,以谷歌和亞馬遜為代表的互聯網巨頭迅速崛起。他們開始推行云計算技術,大量建設數據中心(IDC),甚至超級數據中心。面對日益龐大的計算集群規模,傳統樹型網絡已無法滿足要求,便誕生了一種改進型樹型網絡 —— 胖樹(Fat-Tree)架構。相比于傳統樹型,胖樹(Fat-Tree)更像是真實的樹,越到樹根,枝干越粗(其實是指帶寬)。從葉子到樹根,網絡帶寬無須收斂。胖樹架構被引入到數據中心之后,數據中心便發展成了傳統的三層結構(如下圖所示)。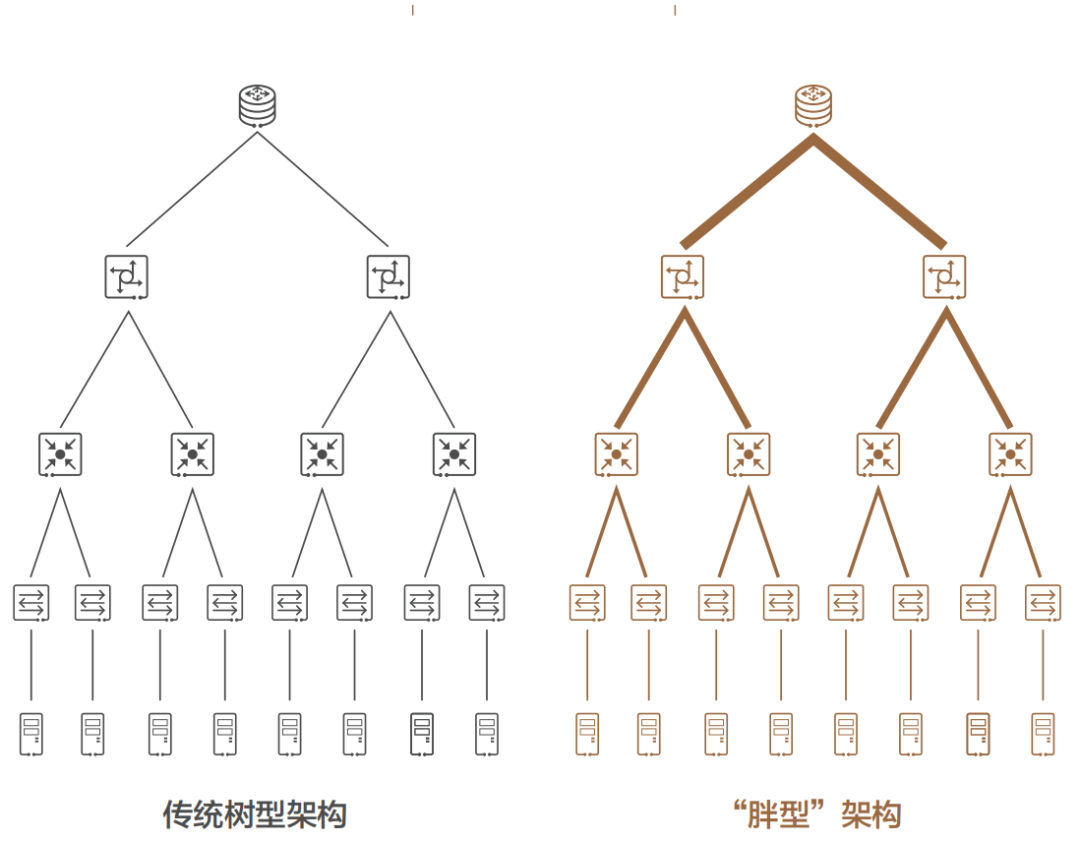 這種架構由核心路由器、聚合路由器(有時叫分發路由器,distribution routers )和接入交換機組成。在很長的一段時間里,三層網絡結構在數據中心十分盛行。但在這種網絡架構下,依然存在如下一些弊端:? 帶寬的浪費,接入交換機的上聯鏈路實際承載流量的只有一條,而其他上行鏈路則被阻塞(如圖中虛線所示);? 故障域較大,在網絡拓撲發生變更時 STP 協議需要重新收斂,容易發生故障,從而影響整個 VLAN 的網絡;? 此架構原生不支持大二層網絡的構建,故難以適應超大規模云平臺網絡需求,更無法支持虛擬機動態遷移;
這種架構由核心路由器、聚合路由器(有時叫分發路由器,distribution routers )和接入交換機組成。在很長的一段時間里,三層網絡結構在數據中心十分盛行。但在這種網絡架構下,依然存在如下一些弊端:? 帶寬的浪費,接入交換機的上聯鏈路實際承載流量的只有一條,而其他上行鏈路則被阻塞(如圖中虛線所示);? 故障域較大,在網絡拓撲發生變更時 STP 協議需要重新收斂,容易發生故障,從而影響整個 VLAN 的網絡;? 此架構原生不支持大二層網絡的構建,故難以適應超大規模云平臺網絡需求,更無法支持虛擬機動態遷移;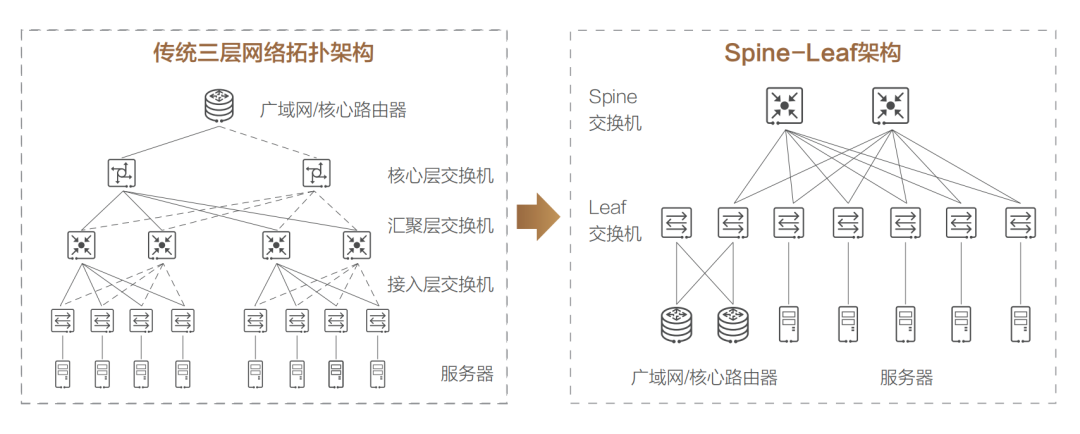 針對以上問題,誕生了一種新的數據中心網絡設計方案,稱作基于 CLOS 網絡的 Spine-Leaf 架構(Clos network-based Spine-and-Leaf architecture,中文也翻譯成葉脊網絡)。實踐已經證明,這種架構可以提供高帶寬、低延遲、非阻塞的數據中心級連接服務。相比于三層架構,Spine-Leaf 架構進行了扁平化處理,變成了兩層架構,如上圖右側所示。 Spine-Leaf 架構的優勢非常明顯: 1、帶寬利用率高,每個葉交換機的上行鏈路都可以負載均衡方式工作; 2、網絡延遲可預測,葉交換機之間的連通路徑均只需經過一臺 Spine 交換機,東西向網絡延時可預測; 3、擴展性好,當上行帶寬不足時,可通過水平擴展方式增加 Spine 交換機數量來快速增加帶寬;當服務器數量增加時,則可通過增加 Leaf 交換機數量來快速擴大數據中心機器規模。 4、降低了對交換機的性能要求,東西向流量均衡分布在多條鏈路上,減少了單價昂貴的高性能高帶寬交換機的采購需求。 5、安全性和可用性高,一臺設備故障時,不需重新收斂,流量繼續在其他正常路徑上通過,網絡連通性不受影響,帶寬也只減少一條路徑的帶寬,性能影響微乎其微。 基于上述優勢,Spine-Leaf 架構從 2013 年一經出現,便很快取代了傳統三層網絡架構的地位,成為現代數據中心的新標準。
針對以上問題,誕生了一種新的數據中心網絡設計方案,稱作基于 CLOS 網絡的 Spine-Leaf 架構(Clos network-based Spine-and-Leaf architecture,中文也翻譯成葉脊網絡)。實踐已經證明,這種架構可以提供高帶寬、低延遲、非阻塞的數據中心級連接服務。相比于三層架構,Spine-Leaf 架構進行了扁平化處理,變成了兩層架構,如上圖右側所示。 Spine-Leaf 架構的優勢非常明顯: 1、帶寬利用率高,每個葉交換機的上行鏈路都可以負載均衡方式工作; 2、網絡延遲可預測,葉交換機之間的連通路徑均只需經過一臺 Spine 交換機,東西向網絡延時可預測; 3、擴展性好,當上行帶寬不足時,可通過水平擴展方式增加 Spine 交換機數量來快速增加帶寬;當服務器數量增加時,則可通過增加 Leaf 交換機數量來快速擴大數據中心機器規模。 4、降低了對交換機的性能要求,東西向流量均衡分布在多條鏈路上,減少了單價昂貴的高性能高帶寬交換機的采購需求。 5、安全性和可用性高,一臺設備故障時,不需重新收斂,流量繼續在其他正常路徑上通過,網絡連通性不受影響,帶寬也只減少一條路徑的帶寬,性能影響微乎其微。 基于上述優勢,Spine-Leaf 架構從 2013 年一經出現,便很快取代了傳統三層網絡架構的地位,成為現代數據中心的新標準。
大二層網絡的時代召喚
在上一節,我們談到 Spine-Leaf 架構出現的時候,其實已經點到了大二層網絡的出現因由。 云計算技術的出現,使得服務器虛擬化之后,除了使得數據中心的主機規模大幅增長,還伴生了一項新需求 —— 虛擬機的動態遷移。虛擬機遷移時,業務不能中斷,這就要求在遷移時,不僅虛擬機的 IP 地址不變,而且虛擬機的運行狀態也必須保持原狀(例如 TCP 會話狀態)。所以虛擬機的動態遷移只能在同一個二層域中進行,而不能跨二層域遷移。而傳統的三層網絡架構就限制了虛擬機的動態遷移只能在一個較小的 VLAN 范圍內進行,應用受到了極大的限制。 為了打破這種限制,實現虛擬機的大范圍甚至跨地域的動態遷移,就要求把 VM 遷移可能涉及的所有服務器都納入同一個二層網絡域,這樣才能實現 VM 的大范圍無障礙遷移。這便是大二層網絡。 近十年間,就大二層網絡的實現,業界先后出現了三類比較典型的實現方案,分別是網絡設備虛擬化類方案、L2 over L3 方案、Overlay 方案。所謂網絡設備虛擬化技術,就是將相互冗余的兩臺或多臺物理網絡設備組合在一起,虛擬化成一臺邏輯網絡設備,在整個網絡中只呈現為一個節點。再配合鏈路聚合技術,就可以把原來的多節點、多鏈路的結構變成邏輯上單節點、單鏈路的結構,環路問題也就順勢而解了。以網絡設備虛擬化 + 鏈路聚合技術構建的二層網絡天然沒有環路,其規模僅受限于虛擬網絡設備所能支持的接入能力,只要虛擬網絡設備允許,二層網絡想做多大都可以。不過,這類設備虛擬化協議大都是網絡設備廠商私有,因此只能使用同一廠商的設備來組網,并且,網絡規模最終還是會受限于堆疊系統本身的規模限制,最大規模的堆疊 / 集群大概可以支持接入 1~2 萬臺主機,對于 10 萬級別的超大型數據中心來說,還是顯得力不從心。 而 L2 over L3 方案的著眼點不是杜絕或者阻塞環路,而是在有物理環路的情況下,怎樣避免邏輯轉發路徑的環路問題。此類方案通過在二層報文前插入額外的幀頭,并且采用路由計算的方式控制整網數據的轉發,不僅可以在冗余鏈路下防止廣播風暴,而且可以做 ECMP(等價路由),這樣就可以將二層網絡的規模擴展到整張網絡,而不會受到核心交換機數量的限制。當然,這需要交換機改變傳統的基于 MAC 的二層轉發行為,而采用新的協議機制來進行二層報文的轉發,這些新的協議包括 TRILL、FabricPath、SPB 等。對于 TRILL 協議,CISCO、華為、Broadcom、Juniper 等都是其支持者;而 Avaya、ALU 等則是 SPB 的擁簇;而像 HP 等廠商,則同時支持這兩類協議。總體而言,像 TRILL 和 SPB 這類技術都是 CT 廠商主推的大二層網絡技術方案,而從事服務器虛擬化技術的 IT 廠商則被晾到了一邊,網絡話語權大幅削弱。 但伴隨著云計算技術迅猛發展的 IT 廠商又豈會坐以待斃,Overlay 方案便是從事服務器虛擬化技術的 IT 廠商主推的大二層網絡解決方案。其原理就是通過用隧道封裝的方式,將源主機發出的原始二層報文封裝后,再在現有網絡中進行透傳,到達目的地之后再解封為原始報文,轉發給目標主機,從而實現主機之間的二層通信。報文的封裝 / 解封裝都是在服務器內部的虛擬交換機 vSwitch 上進行,外部網絡只對封裝后的報文進行普通的二層交換和三層轉發即可,所以網絡技術控制權就都回到了 IT 廠商手里。典型技術實現包括 VXLAN、NVGRE、STT 等。當然,目前 CT 廠商也都積極參與到了 Overlay 方案中來,畢竟云計算是大勢所趨。所以當前的 VXLAN 和 NVGRE 技術也可以把 Overlay 網絡的接入點部署在 TOR 等網絡設備上,由網絡接入設備來完成 VXLAN 和 NVGRE 的報文封裝。這樣的好處是: ? 一方面對于虛擬服務器來說,硬件網絡設備的性能要比軟件形態的 vSwitch 強很多,用 TOR 等設備來進行封裝 / 解封裝,整體云網絡性能自然更好。 ? 另一方面,在 TOR 上部署 Overlay 接入點,也便于把非虛擬化的服務器統一納入 Overlay 網絡,目前主流云廠商的裸金屬方案基本如此。 如此一來,CT 廠商和 IT 廠商都在大二層網絡這個領域實現了和諧共贏,也真因為如此,Overlay 方案成為了當今大二層網絡的主流方案。
Underlay 和 Overlay 正式托起 SDN 的太陽
上一節已經提及,Overlay 技術實際上是一種隧道封裝技術,主流協議有 VXLAN、NVGRE 等,基本原理都是通過隧道封裝的方式將二層報文進行封裝后在現有網絡中進行透明傳輸,到達目的地之后再解封裝得到原始報文,相當于一個大二層網絡疊加(overlay)在現有的網絡之上。而 Underlay 層則變成了一張承載網,囊括各類物理網絡設備,如 TOR 交換機、匯聚交換機、核心交換機、負載均衡設備、防火墻設備等。由此實現邏輯組網與物理組網的隔離,例如,在華為云 / 阿里云解決方案中,均選用了 VXLAN 技術來構建 Overlay 網絡,業務報文運行在 VXLAN Overlay 網絡上,與物理承載網絡分層、解耦。 而對于當前走紅的 SDN 技術,Underlay/Overlay 已經成為了其從理念到實踐都不可或缺的一部分。 在數據中心之內或者數據中心互聯(DCI)的場景下,運營方會先建立一個底層的 Underlay 網絡骨架,通過交換機和路由器將所有硬件單元(比如服務器 / 存儲設備 / 監控設備等)相互連接。在這個 Underlay 網絡內,通過運行 IP 網絡協議比如 ISIS 或者 BGP,來保證各個在網硬件單元之間的可達性。在完成 Underlay 網絡構架之后,管理員可以通過部署 SDN 控制器的方式來對整網所有硬件資源進行調控與編排,再建立租戶之間的 Overlay 網絡連接并承載真正的用戶流量。 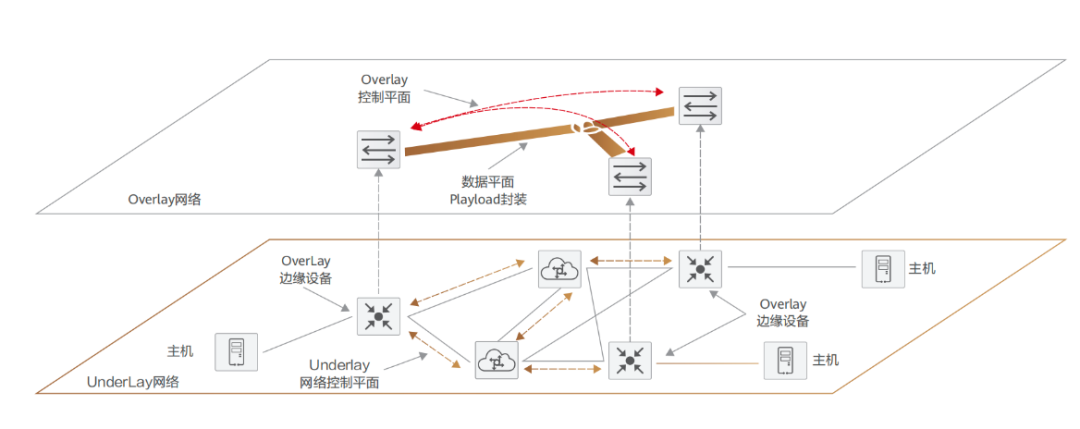
SDN 技術讓封閉硬件 “軟化” 開放
軟件定義網絡(Software Define Network,SDN)技術是對傳統網絡架構的一次重構,其核心思想是通過控制面(Control Plane)與數據面(Data Plane)的分離,將網絡的管理權限交給控制層的控制器軟件,在通過 OpenFlow 協議通道,統一下達指令給數據轉發層設備,從而實現網絡控制與數據轉發的充分解耦,一舉破除傳統網絡設備的封閉性。 由于 OpenFlow 協議的開放性,第三方也可以開發相應的應用置于控制層內,從而使得網絡資源的調配更加靈活、更能滿足企業個性化場景。而網絡管理人員只需通過控制器下達指令至數據層設備即可,無需一一登錄設備,從而大幅提高了網絡管理效率,節省了人力成本。可以說,SDN 技術極大地推動了網絡虛擬化的發展進程,也因此,其網絡架構設計思想在當今各大云平臺均得到了充分實現與落地。SDN 有過三種主流實現方式,分別是 OpenFlow 組織主導的開源軟件(包括 Google,IBM,Citrix 等公司支持),思科主導的應用中心基礎設施技術(Application Centric Infrastructure,ACI),以及 VMware 主導的 NSX。顯而易見,開源的 OpenFlow 成為了事實上的行業標準。 
SDN 的價值
支撐網絡業務快速創新
SDN 的可編程性和開放性,使得我們可以快速開發新的網絡業務和加速業務創新。如果希望在網絡上部署新業務,可以通過針對 SDN 軟件的修改實現網絡快速編程,業務快速上線。SDN 架構下,底層硬件只需關注轉發和存儲能力,與業務特性徹底解耦。而網絡設備的種類及功能由軟件配置而定,對網絡的操作控制和運行也由控制層服務器完成,故而對業務響應相對更快,可以定制各種網絡參數(如路由、安全策略、QoS 等),并實時配置到網絡中。如此,新業務的上線周期可從傳統網絡的幾年提升到幾個月甚至更快。
簡化網絡協議結構
SDN 的網絡架構簡化了網絡拓撲結構,可消除很多 IETF 協議。協議的去除,意味著運維學習門檻的下降、運行維護復雜度的降低,進而使業務部署效率提升。因為 SDN 網絡架構下的網絡集中控制,所以被 SDN 控制器所控制的網絡內部很多協議基本就不需要了,比如 RSVP 協議、LDP 協議、MBGP 協議、PIM 組播協議等等。網絡內部的路徑計算和建立全部在控制器完成,控制器計算出流表,直接下發給轉發器就行,并不需要其他協議。
網絡設備白牌化
SDN 架 構 下,控 制 器 和 轉 發器 之間 的 接口協議 逐 漸標 準 化(比 如 OpenFlow 協議),使得網絡設備的 白 牌 化 成 為可 能,比 如 專 門 的 OpenFlow 轉發芯片供應商,控制器廠商等,這也正是所謂的系統從垂直集成開發走向水平集成開發。垂直集成是指由一個廠家提供從軟件到硬件到服務的一體化產品服務,水平集成則是把系統水平分工,每個廠家都完成產品的一個部件,再由集成商把他們集成起來銷售。水平分工有利于系統各個部分的獨立演進和更新,快速迭代優化,促進良性競爭,從而使各個部件的采購單價下降,最終使得整機產品的采購成本大幅降低。
業務自動化
SDN 網絡架構下,由于整個網絡由 SDN 控制器控制,故 SDN 控制器可以自主完成網絡業務部署,并提供各種網絡個性化配置服務,比如 L2VPN、L3VPN 等,對外屏蔽網絡內部細節,提供網絡業務自動化能力。網絡路徑流量智能優化傳統網絡中,網絡路徑的選擇依據是通過各類路由協議計算得出所謂 “最優” 路徑,但此結果反而可能會導致 “最優” 路徑上的流量擁塞,其他非 “最優” 路徑帶寬空閑。而采用 SDN 網絡架構時,SDN 控制器可以根據各鏈路上網絡流量的狀態智能調整網絡流量路徑,從整網角度出發,整體性提升網絡傳輸效率。
SDN 催化的網絡虛擬技術狂飆
接下來,我們分別從網絡設備虛擬化、鏈路虛擬化和虛擬網絡三個層面來看看網絡虛擬化技術的高速發展。
網絡設備虛擬化
網絡設備虛擬化技術是云網絡技術發展最為迅猛且影響最大的領域,其 主要包括網卡虛擬化(NIC Virtualization)與常規網絡設備虛擬化兩大方向。 一、網卡虛擬化 網卡虛擬化技術演進路線與我們在《重識云原生第三篇:軟飯硬吃的計算》一文中對于 I/O 虛擬化的演進路線基本一致,也是經歷了純軟虛擬化(即 Qemu、VMware Workstation 虛擬網卡實現方案)、半虛擬化(Virtio、Vhost-net、Vhost-user 系列方案),再到硬件直通方案(SR-IOV),最后到硬件卸載(vPDA、DPU 等)。 網卡虛擬化的產品形態即是公有云常見的虛擬網卡,其主要通過軟件控制各個虛擬機共享同一塊物理網卡實現,虛擬網卡可以有單獨的 MAC 地址、IP 地址,早期結構如下圖所示。所有虛擬機的虛擬網卡通過虛擬交換機以及物理網卡連接至物理交換機。虛擬交換機負責將虛擬機上的數據報文從物理網口轉發出去。根據需要,虛擬交換機還可以支持安全控制等功能。 虛擬網卡包括 e1000、Virtio 等實現技術。Virtio 是目前最為通用的技術框架,其提供了虛擬機和物理服務器數據交換的通用方案,得到了大多數 Hypervisor 的支持,成為事實上的標準。 Virtio 是一種半虛擬化的解決方案,在半虛擬化方案中,Guest OS 知道自己是虛擬機,通過前端驅動和后端模擬設備互相配合實現 IO 虛擬化。這種方式與全虛擬化相比,可以大幅度提高虛擬機的 IO 性能。 最初的 Virtio 通信機制中,Guest 與用戶空間的 Hypervisor 通信,會有多次數據拷貝和 CPU 特權級的切換。Guest 發包給外部網絡,需要切換到內核態的 KVM,然后 KVM 通知用戶空間的 QEMU 處理 Guest 網絡請求。很顯然,這種通信方式效率并不高。很快,Virtio 技術演進中便出現了內核態卸載的方案 Vhost-net。 Vhost-net 是 Virtio 的一種后端實現方案,與之相匹配的是一套新的 Vhost 協議。Vhost 協議允許 VMM 將 Virtio 的數據面 Offload 到另一個組件上,而這個組件是 Vhost-net。Vhost-net 在 OS 內核中實現,其與 Guest 直接通信,旁路了 KVM 和 QEMU。QEMU 和 Vhostnet 使用 ioctl 來交換 Vhost 消息,并且用 eventfd 來實現前后端的事件通知。當 Vhost-net 內核驅動加載后,它會暴露一個字符設備標識在 /dev/Vhost-net, 而 QEMU 會打開并初始化這個字符設備,并調用 ioctl 來與 Vhost-net 進行控制面通信,其內容包含 Virtio 的特性協商、將虛擬機內存映射傳遞給 Vhost-net 等。對比最原始的 Virtio 網絡實現,控制平面在原有執行基礎上轉變為 Vhost 協議定義的 ioctl 操作(對于前端而言仍是通過 PCI 傳輸層協議暴露的接口),基于共享內存實現的 Vring 數據傳遞轉變為 Virtio-net 與 Vhost-net 共享;數據平面的另一方轉變則為 Vhost-net,前后端通知方式也轉為基于 eventfd 來實現。 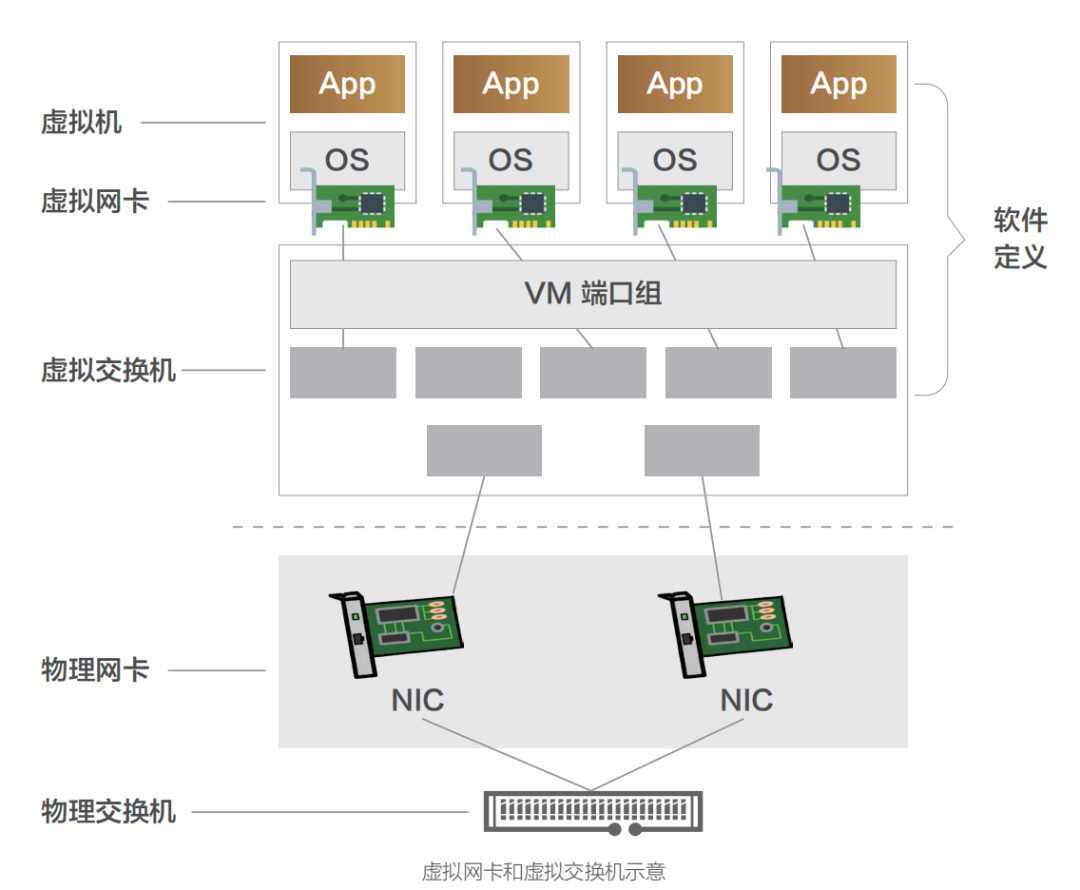 ?
?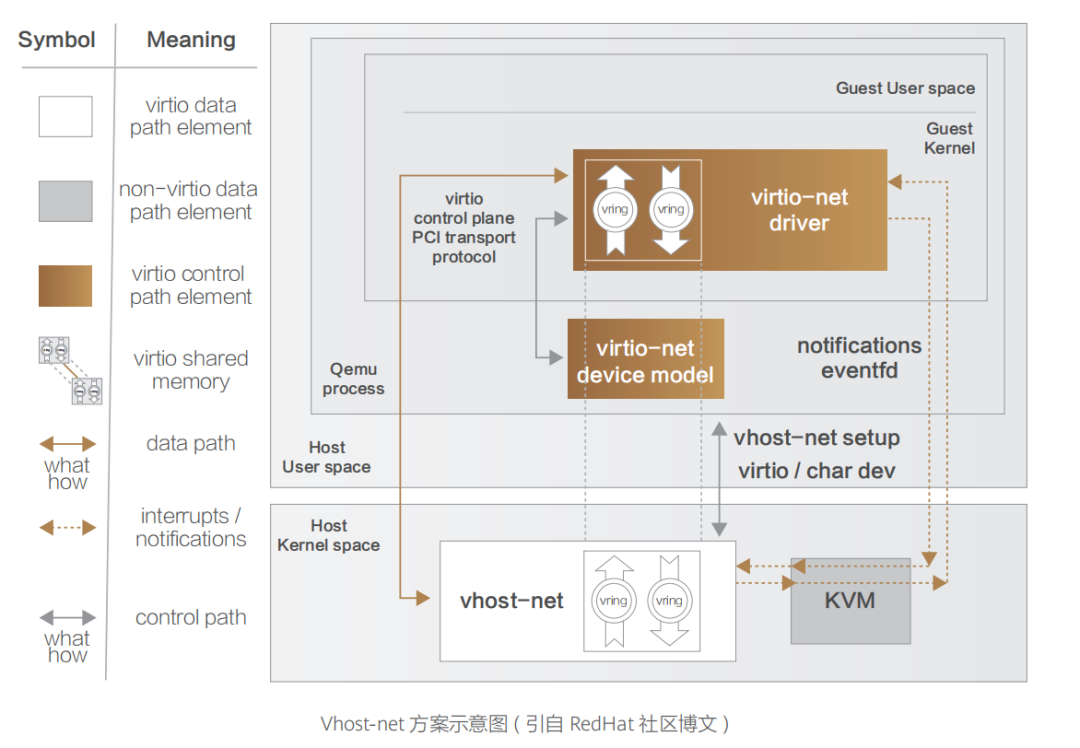 在單次收發的過程中,數據通道減少了兩次用戶態與內核態的上下文切換過程,實現了數據通道在內核態的卸載,從而較大程度提升了數據傳輸效率。 但是,對于某些用戶態進程間的通信,比如數據面的通信方案(例如 Open vSwitch 和與之類似的 SDN 解決方案),Guest 仍需要和 Host 用戶態的 vSwitch 進行數據交換,如果采用 Vhost-net 方案,Guest 和 Host 之間還是存在多次上下文切換和數據拷貝,為了避免這種情況,業界就想出將 Vhost-net 從內核態移到用戶態的方案,這就是 Vhost-user 方案的實現思路。
在單次收發的過程中,數據通道減少了兩次用戶態與內核態的上下文切換過程,實現了數據通道在內核態的卸載,從而較大程度提升了數據傳輸效率。 但是,對于某些用戶態進程間的通信,比如數據面的通信方案(例如 Open vSwitch 和與之類似的 SDN 解決方案),Guest 仍需要和 Host 用戶態的 vSwitch 進行數據交換,如果采用 Vhost-net 方案,Guest 和 Host 之間還是存在多次上下文切換和數據拷貝,為了避免這種情況,業界就想出將 Vhost-net 從內核態移到用戶態的方案,這就是 Vhost-user 方案的實現思路。 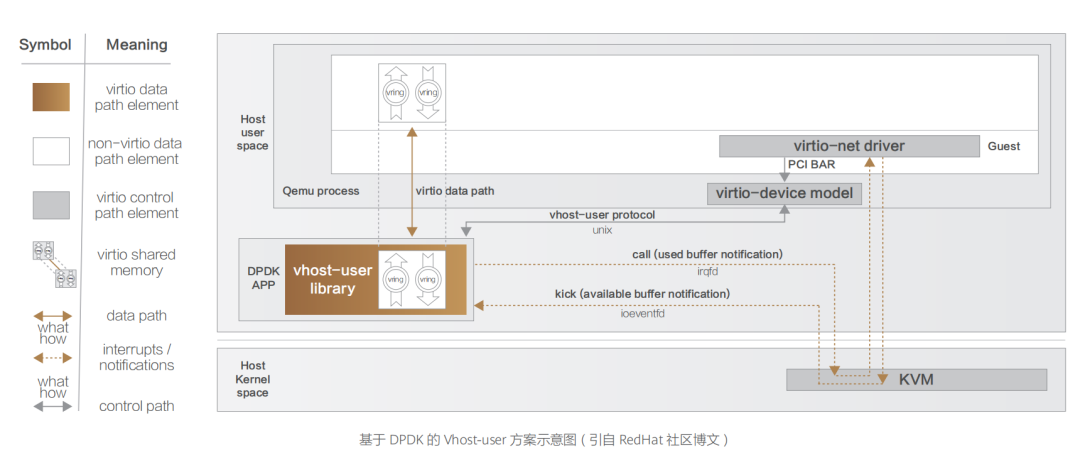 基于 Vhost 協議,DPDK 設計了一套新的用戶態協議 ——Vhost-user。該協議將網絡包處理(數據平面)卸載到用戶態的 DPDK 應用中,控制平面仍然由 QEMU 來配置 Vhost-user。除此之外,DPDK 優化實現了處理器親和性管理、NUMA 調度、使用大頁內存代替普通內存、采用無鎖技術解決資源競爭問題、輪詢模式驅動等技術,由此,大名鼎鼎的 DPDK 網絡卸載方案蔚然成型。 縱如此,技術迭代演進是永無止境的,雖然上述方案對網絡性能的提升非常顯著,但總體而言,Virtio 網絡虛擬化方案一直都聚焦在軟件層實現,在 Host 上因軟件虛擬化而產生的額外開銷始終無法避免。為了進一步提升云端網絡服務的性能,RedHat 的技術專家們提出可以將 Virtio 功能 Offload 到專用硬件,將與業務無關的任務 Bypass 操作系統和 CPU,轉而直接交給專用硬件執行,從而進一步提升網絡性能,這便是 vDPA 硬件卸載方案的設計初衷,也是 Virtio 半硬件虛擬化方案的早期硬件方案實現思路。 該框架由 Redhat 提出,實現了 Virtio 數據平面的硬件卸載。控制平面仍然采用原來的控制平面協議,當控制信息被傳遞到硬件中,硬件完成數據平面的配置之后,數據通信過程由硬件設備 SmartNIC(即智能網卡)完成,Guest 虛擬機與網卡之間直接通信。中斷信息也由網卡直接發送至 Guest 而不需要 Host 主機的干預。這種方式在性能方面能夠接近 SR-IOV 硬件直通方案,同時能夠繼續使用 Virtio 標準接口,保持云服務的兼容性與靈活性。但是其控制面處理邏輯比較復雜,通過 OVS 轉發的流量首包依然需要由主機上的 OVS 轉發平面處理,對應數據流的后續報文才能由硬件網卡直接轉發,硬件實現難度較大。 不過,隨著越來越多的硬件廠商開始原生支持 Virtio 協議,將網絡虛擬化功能 Offload 到硬件上,把嵌入式 CPU 集成到 SmartNIC(即智能網卡)中,網卡能處理所有網絡數據,而嵌入式 CPU 負責控制路徑的初始化并處理異常情況。這種具有硬件 Offload 能力的 SmartNIC 就是如今越來越火的 DPU。
基于 Vhost 協議,DPDK 設計了一套新的用戶態協議 ——Vhost-user。該協議將網絡包處理(數據平面)卸載到用戶態的 DPDK 應用中,控制平面仍然由 QEMU 來配置 Vhost-user。除此之外,DPDK 優化實現了處理器親和性管理、NUMA 調度、使用大頁內存代替普通內存、采用無鎖技術解決資源競爭問題、輪詢模式驅動等技術,由此,大名鼎鼎的 DPDK 網絡卸載方案蔚然成型。 縱如此,技術迭代演進是永無止境的,雖然上述方案對網絡性能的提升非常顯著,但總體而言,Virtio 網絡虛擬化方案一直都聚焦在軟件層實現,在 Host 上因軟件虛擬化而產生的額外開銷始終無法避免。為了進一步提升云端網絡服務的性能,RedHat 的技術專家們提出可以將 Virtio 功能 Offload 到專用硬件,將與業務無關的任務 Bypass 操作系統和 CPU,轉而直接交給專用硬件執行,從而進一步提升網絡性能,這便是 vDPA 硬件卸載方案的設計初衷,也是 Virtio 半硬件虛擬化方案的早期硬件方案實現思路。 該框架由 Redhat 提出,實現了 Virtio 數據平面的硬件卸載。控制平面仍然采用原來的控制平面協議,當控制信息被傳遞到硬件中,硬件完成數據平面的配置之后,數據通信過程由硬件設備 SmartNIC(即智能網卡)完成,Guest 虛擬機與網卡之間直接通信。中斷信息也由網卡直接發送至 Guest 而不需要 Host 主機的干預。這種方式在性能方面能夠接近 SR-IOV 硬件直通方案,同時能夠繼續使用 Virtio 標準接口,保持云服務的兼容性與靈活性。但是其控制面處理邏輯比較復雜,通過 OVS 轉發的流量首包依然需要由主機上的 OVS 轉發平面處理,對應數據流的后續報文才能由硬件網卡直接轉發,硬件實現難度較大。 不過,隨著越來越多的硬件廠商開始原生支持 Virtio 協議,將網絡虛擬化功能 Offload 到硬件上,把嵌入式 CPU 集成到 SmartNIC(即智能網卡)中,網卡能處理所有網絡數據,而嵌入式 CPU 負責控制路徑的初始化并處理異常情況。這種具有硬件 Offload 能力的 SmartNIC 就是如今越來越火的 DPU。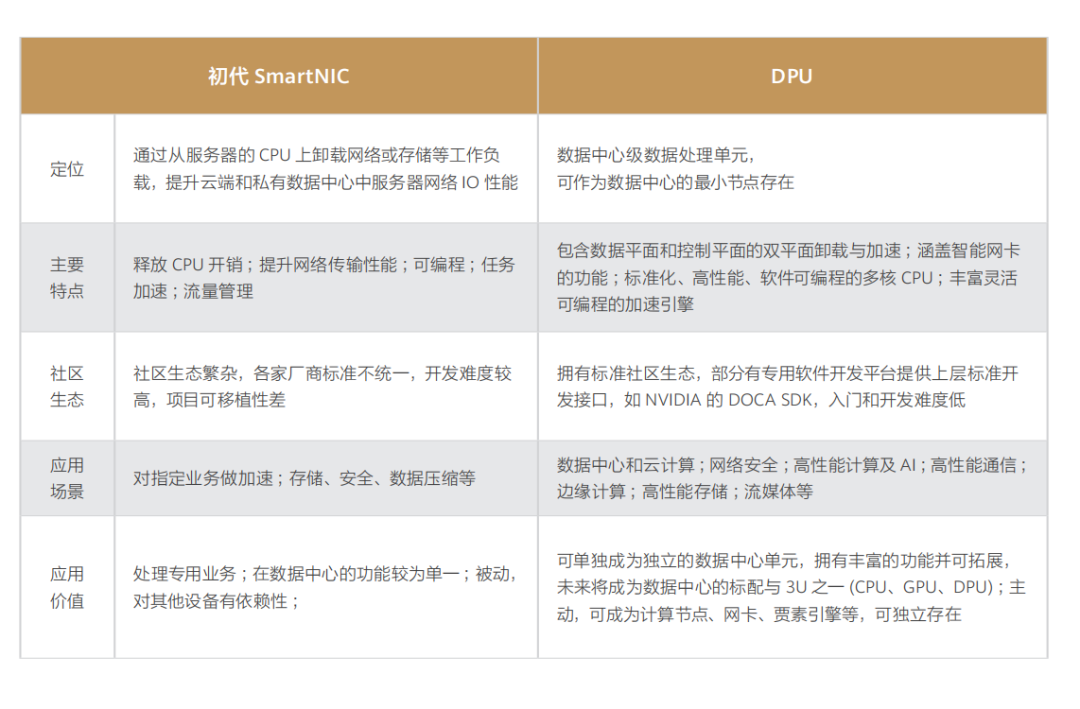 二、網絡設備虛擬化 硬件設備虛擬化主要有兩個方向:在傳統的基于 x86 架構機器上安裝特定操作系統來實現路由功能。 前者的早期典型產品是 Mikrotik 公司開發的 RouterOS,其基于 Linux 內核開發,可以安裝在標準的 x86 架構的機器上,從而使普通 Linux 服務器也可以當成路由器使用。此類設備以其低廉的價格和不受硬件平臺約束等特性,占據了不少低端路由器市場。現如今,國內外主流云廠商對于 SDN 控制面的實現思路大抵都是如此。 而后者主要是應第一代云計算技術的市場需求催生,在計算虛擬化之后,數據中心通訊規模大幅增長,傳統路由器中的單張路由表已經不能滿足需求,因此催生了虛擬路由轉發(Virtual Routing and Forwarding,VRF)技 術,即 是 將 路 由 信 息 庫(Forwarding Information Base,FIB)虛擬化成多個路由轉發表。此技術誕生背景主要為增加大型通訊設備的端口利用率,減少設備成本投入,將一臺物理設備虛擬化成多臺虛擬設備,每臺虛擬設備僅維護自身的路由轉發表即可,比如思科的 N7K 系列交換機可以虛擬化成多臺 VDC。所有 VDC 共享物理機箱的計算資源,但又各自獨立工作,互不影響。此外,為了便于維護、管理和控制,將多臺物理設備虛擬化成一臺虛擬設備的融合虛擬化技術也有一定市場,比如 H3C 公司的 IRF 技術。
二、網絡設備虛擬化 硬件設備虛擬化主要有兩個方向:在傳統的基于 x86 架構機器上安裝特定操作系統來實現路由功能。 前者的早期典型產品是 Mikrotik 公司開發的 RouterOS,其基于 Linux 內核開發,可以安裝在標準的 x86 架構的機器上,從而使普通 Linux 服務器也可以當成路由器使用。此類設備以其低廉的價格和不受硬件平臺約束等特性,占據了不少低端路由器市場。現如今,國內外主流云廠商對于 SDN 控制面的實現思路大抵都是如此。 而后者主要是應第一代云計算技術的市場需求催生,在計算虛擬化之后,數據中心通訊規模大幅增長,傳統路由器中的單張路由表已經不能滿足需求,因此催生了虛擬路由轉發(Virtual Routing and Forwarding,VRF)技 術,即 是 將 路 由 信 息 庫(Forwarding Information Base,FIB)虛擬化成多個路由轉發表。此技術誕生背景主要為增加大型通訊設備的端口利用率,減少設備成本投入,將一臺物理設備虛擬化成多臺虛擬設備,每臺虛擬設備僅維護自身的路由轉發表即可,比如思科的 N7K 系列交換機可以虛擬化成多臺 VDC。所有 VDC 共享物理機箱的計算資源,但又各自獨立工作,互不影響。此外,為了便于維護、管理和控制,將多臺物理設備虛擬化成一臺虛擬設備的融合虛擬化技術也有一定市場,比如 H3C 公司的 IRF 技術。
鏈路虛擬化
鏈路虛擬化是日常使用最多的網絡虛擬化技術之一,增強了網絡的可靠性與便利性。常見的鏈路虛擬化技術有鏈路聚合和隧道協議,此部分內容在《第四篇 - 硬菜軟嚼的網絡 (上)》篇已有詳細闡述,此處只簡單提一下。 鏈路聚合(Port Channel)是最常見的二層虛擬化技術。鏈路聚合將多個物理端口捆綁在一起,虛擬成為一個邏輯端口。當交換機檢測到其中一個物理端口鏈路發生故障時,就停止在此端口上發送報文,根據負載分擔策略在余下的物理鏈路中選擇報文發送的端口。鏈路聚合可以增加鏈路帶寬、實現鏈路層的高可用性。 隧道協議(Tunneling Protocol)指一種技術 / 協議的兩個或多個子網穿過另一種技術 / 協議的網絡實現互聯。隧道協議將其他協議的數據幀或包重新封裝然后通過隧道發送。新的幀頭提供路由信息,以便通過網絡傳遞被封裝的負載數據。隧道可以將數據流強制送到特定的地址,并隱藏中間節點的網絡地址,還可根據需要,提供對數據加密的功能。當前典型的隧道的協議便是 VXLAN、GRE 和 IPsec。當今各大云廠商的云平臺的網絡實現方案莫不基于此。
虛擬網絡
虛擬網絡(Virtual Network)是由虛擬鏈路組成的網絡。虛擬網絡節點之間的連接并不使用物理線纜連接,而是依靠特定的虛擬化鏈路相連。典型的虛擬網絡包括在數據中心使用較多的虛擬二層延伸網絡、虛擬專用網絡以及 Overlay 網絡。 虛 擬 二 層 延伸網絡(V i r t u a l L 2 Extended Network)其實也可以算是 Overlay 網絡的早期解決方案。為滿足虛擬機動態遷移需求,傳統的 VPL(MPLS L2VPN)技術,以及新興的 Cisco OTV、H3C EVI 技術,都借助隧道的方式,將二層數據報文封裝在三層報文中,跨越中間的三層網絡,來實現兩地二層數據的互通。 而虛擬專用網(VPN,全稱 Virtual Private Network),是一種應用非常久遠,常用于連接中、大型企業或團體與團體間的私人網絡的通信方法。虛擬專用網通過公用的網絡架構(比如互聯網)來傳送內聯網的信息。利用已加密的隧道協議來達到保密、終端認證、信息準確性等安全效果。這種技術可以在不安全的網絡上傳送可靠的、安全的信息,總體而言早于云計算技術在企業中落地。 而 Overlay 網絡也已在上篇有詳細闡述,此處就不再復述了。
云網絡產品的發展
云網絡產品整體而言,主要經過了三次大的演進,從最初的經典云網絡,到私有網絡(Virtual Private Cloud),再到連接范圍更大的云聯網。云網絡技術的發展也是企業數字化、全球化發展的一個縮影。
經典(基礎)云網絡
從 2006 年 AWS 推出 s3 和 ec2 云服務,開始為公有云用戶提供云上服務開始,到 2010 年,阿里云正式推出 Classic 經典云網絡方案,實現了對云計算用戶的網絡支持,再后續騰訊云、華為云也提供過類似的基礎網絡產品。 這些都是公有云早期的云產品,當時用戶對云網絡的主要需求是提供公網接入能力。經典云網絡的產品特點是云上所有用戶共享公共網絡資源池,所有云服務器的內網 IP 地址都由云廠商統一分配,無法自定義網段劃分、IP 地址。
私有網絡 VPC
而從 2011 年左右開始,隨著移動互聯網的發展,越來越多企業選擇上云,企業對云上網絡安全隔離能力、互訪能力、企業自建數據中心與云上網絡互聯并構建混合云的能力,以及在云上實現多地域部署后的多地域網絡互聯能力都提出了很多需求。此時,經典網絡方案已經無法滿足這些需求,AWS 適時推出云上 VPC 產品服務 (即私有專用網絡服務,全稱 Virtual Private Cloud),VPC 是企業用戶在云上建立的一塊邏輯隔離的網絡空間 —— 在 VPC 內,用戶可以自由定義網段劃分、自由分配網段內 IP 地址、自定義路由策略。而后又陸續推出 NAT 網關、VPN 網關、對等連接等云網絡產品,極大地豐富了云網絡的連接能力,基本實現了私有網絡方案最初的設計目標。 當前,以 VPC 為核心的云網絡產品體系依然在不斷發展壯大,又陸續誕生了負載均衡器、彈性網卡、彈性公網 IP、云防火墻等配套類衍生網絡產品。
云聯網
而近幾年,隨著經濟全球化高速發展,大數據與 AI 類應用異軍突起,需要云平臺網絡提供更廣泛靈活的接入能力與分發能力,便催生了私網連接、云企業網、云連接器、云聯網等各類場景的接入類云網產品,以此來滿足企業全球化場景下的各類復雜互聯互通需求。 與此同時,傳統的 CDN 分發服務,經過與云聯網的深度融合,也煥發了第二春,如今各大云廠商均有推出 CDN 全球內容分發服務與應用加速服務。同時 SD-WAN 接入服務的不斷完善,也使得企業信息架構一體化的物理邊際向著全球大踏步邁進。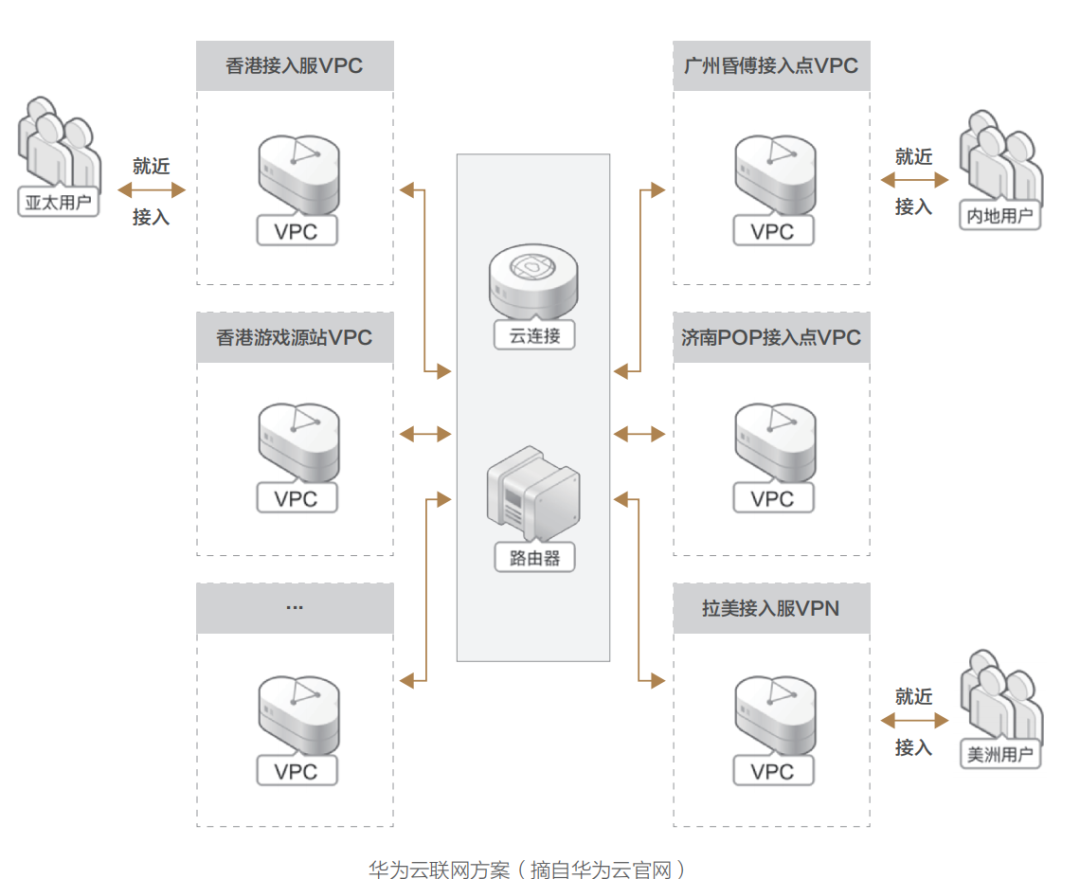
云網絡技術后續演進展望
云網絡從基礎核心技術的演進來看,是對網絡編址靈活性和網絡傳輸性能提升的持續優化過程:經典云網絡和 VPC 網絡在編址方案上,都使用了 Overlay 技術,在物理網絡之上疊加了一個支持多租戶的虛擬網絡層,從而有效支持了云上租戶間的網絡隔離安全性、租戶內應用的互聯互通靈活性訴求;而在網絡性能提升方面, 通過重構網絡設備形態,在不喪失轉發控制靈活性基礎上,來持續持續提升數據轉發性能是為當今主流技術演進方向,以虛擬交換機為例,伴隨著硬件服務器網絡帶寬從 10G 升級到 25G,乃至到 100G,vSwitch 技術經歷了經典網絡的 Linux 內核態數據交換、DPDK 用戶態數據交換、硬件直通、再到智能網卡硬件卸載(vPDA、DPU 等)等演進歷程。 而從產品層面看,云網產品經過經典網絡,VPC 網絡,云聯網三代產品的發展,云網絡產品的能力范圍得到了極大延展 —— 從聚焦數據中心內部網絡虛擬化,到聚焦數據中心之間的互聯互通,再進一步通過 sd-wan 接入能力把企業的網絡接入能力進行虛擬化從而支持各類場景接入。云網絡產品已不僅僅用于連接云內的計算與存儲資源,云下接入范圍也逐漸擴展到連接企業的總部 / 分支網絡以及云外各類終端,以期最終使企業能在云上構建完整的 IT 信息服務生態體系。 而在云計算技術發展到第三代云原生時代的當下,隨著各類虛擬化技術的成熟,各類軟件定義硬件的云能力得以落地運用,伴隨著容器技術的大規模商用,終會使業務研發與基礎運維一體化協作的技術隔閡會徹底破除,業務應用的全棧可觀測性述求必將使業務服務監控下鉆到基礎網絡層,讓網絡流量監測帶上業務屬性,從而使業務全鏈路監控真正具備生產力價值。而這又都將取決于容器網絡與云網絡技術的融合深度與應用廣度,這一領域也必將成為今后各大云廠商決勝云原生時代的戰略制高點!
編輯:黃飛
?










 工商網監
工商網監
評論