 電子發燒友App
電子發燒友App


作者:王旭, 劉瓊, 彭宗舉, 侯軍輝, 元輝, 趙鐵松, 秦熠, 吳科君, 劉文予, 楊鈾
00??引言
6自由度(six degrees of freedom,6DoF)視頻具體表現為在觀看視頻過程中,用戶站在原地時頭部與視頻內容之間的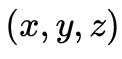 3個自由度的交互和用戶位姿發生移動時與內容之間的另外3個自由度的交互(Boyce等,2021)。
3個自由度的交互和用戶位姿發生移動時與內容之間的另外3個自由度的交互(Boyce等,2021)。
6DoF視頻有多視點視頻、多視點+深度視頻、光場視頻、焦棧圖像和點云序列等多種數據表示方式(Wien等,2019)。用戶可以通過體感、視線、手勢、觸控和按鍵等交互方式來選取任意方向和位置的觀看視角。視頻系統在獲得用戶交互參數后,通過虛擬視點繪制技術完成視角平滑切換,在沉浸式體驗上更加出色。6DoF視頻體現了用戶與視頻內容的高度交互性,全面打破了人們被動接受視頻內容的傳統模式,能夠實現千人千面的視覺體驗,是當前多媒體通信、計算機視覺、人機交互和計算顯示等多個學科領域的交叉與前沿。
一方面,6DoF視頻通過計算重構的方式向用戶提供包括視角、光照、焦距和視場范圍等多個視聽維度的交互與變化,使千里之外的用戶有身臨其境之感,這與元宇宙所具有的感知、計算、重構、協同和交互等技術特征高度重合。因此,6DoF視頻所涵蓋的技術體系可用做實現元宇宙的替代技術框架。另一方面,6DoF視頻從采集、處理、編碼、傳輸、顯示、交互和計算等方面改變了數字媒體端到端全鏈條的生產制作模式,給內容提供商、運營商、設備商和用戶帶來巨大的改變,因此也受到國防訓練、數字媒體和數字教育的高度關注。
本文將圍繞6DoF視頻內容的生產、分發與呈現中存在的關鍵問題(如圖1所示),從內容采集與預處理、編碼壓縮與傳輸優化以及交互與呈現等方面闡述國內外研究進展,并圍繞該領域當下挑戰及未來趨勢開展討論。

圖1??6DoF視頻系統中的關鍵問題
01??6DoF內容采集與預處理
6DoF視頻以3維場景為觀察對象,以3維時空分布的點云、圖像等為數據表達,可用模型
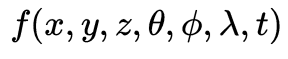
刻畫,包含空間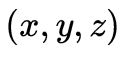 、角度
、角度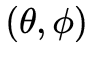 、光譜
、光譜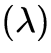 和時間
和時間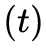 等。如何獲取3維場景的視覺信息是6DoF視頻采集與生成需要實現的任務與目標。相機一直以來作為獲取視覺信息的主要工具,將分布在3維時空
等。如何獲取3維場景的視覺信息是6DoF視頻采集與生成需要實現的任務與目標。相機一直以來作為獲取視覺信息的主要工具,將分布在3維時空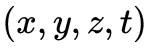 中的光降維到2維時空
中的光降維到2維時空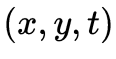 上形成圖像或視頻。基于相機的視覺獲取無法得到深度
上形成圖像或視頻。基于相機的視覺獲取無法得到深度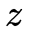 ,因此如何通過相機來實現3維場景的視覺信息獲取,長期以來是一個挑戰性的難題。從技術演進的角度,3維場景的視覺信息獲取可分為多視點聯合采集、多視點與深度聯合采集這兩個方向和階段。
,因此如何通過相機來實現3維場景的視覺信息獲取,長期以來是一個挑戰性的難題。從技術演進的角度,3維場景的視覺信息獲取可分為多視點聯合采集、多視點與深度聯合采集這兩個方向和階段。
1.1 多視點聯合采集
雖然單相機的視覺獲取只能得到平面圖像,但是仿照人眼的雙目視覺系統,只要能夠利用2個及以上的相機進行多視點同步采集,就能夠在得到的多視點圖像基礎上進行立體匹配,從而得到深度的信息(Marr和Poggio,1976)。為此,科研人員以6DoF視頻為目標,研制出了不同類型的多視點視頻采集系統。如圖2所示,以影視內容制作為目標,工程技術人員于1999年首次搭建了由上百臺相機共同構成的多視點聯合采集系統。該系統在幾何排布上具有線性環繞的特點,并形成了著名的“子彈時間”影視效果(Stankiewicz等,2018)。觀眾可通過這種方式在屏幕上直接得到立體的觀感。通過該多視點聯合采集系統所形成的交互式媒體內容具有非常震撼的視覺效果,但同時也有明顯的缺陷,如不能拍動態的視頻、幾何排布復雜不利于后期視覺計算以及成本高昂難以商業推廣等。因此,降低相機數量,簡化幾何排布方式,研發多相機標定方法成為多視點聯合采集面臨的關鍵需求。
為了解決上述問題,研究者提出了幾種典型的幾何排布模式,如圖3所示。圖3(a)所示的平行模式以直線分布、光軸平行的方式進行排布,視點之間的圖像原則上不存在垂直偏移,在交互過程中體現為水平移動。稀疏的(間距20 cm及以上)平行模式是MPEG(motion picture expert group)中典型的多視點視頻數據表達形式(Merkle等,2007),而稠密的平行模式則可較為方便地構成光線空間(ray space)(Tanimoto,2012),從而實現平移之外的縱向交互。圖3(b)所示的發散模式是所有相機的光軸后延線共圓心,從形式上不局限于水平共心,也可以是球面發散的共心方式。這種模式可較方便地形成全景視頻用于3自由度交互,并在許多商業應用中取得了成功。圖3(c)所示的匯聚模式在排布模式上是平行模式的簡單變化,在直線分布的基礎上將光軸匯聚到一個點上,視點之間的圖像原則上不存在垂直偏移,在交互過程中體現為具有弧度的水平移動。然而,在實際操作中匯聚模式有許多問題,如匯聚點的確定、相機間的幾何標定問題等,導致大部分的匯聚模式最后退化到圖2的模式,即交互只在真實相機之間做切換,較少通過視覺計算的方式去繪制虛擬視點。
圖3(d)所示的圍繞模式不局限于平面,也可以進一步拓展成半球體、圓球體的布置形式。與匯聚模式類似,同樣面臨著匯聚點確定、相機間幾何標定的難題,而且難度更大,因為每一個相機一定會有另外一個相機與之完全相對,無法通過構建兩個視點之間公共特征點的匹配關系以完成幾何標定所需的有關參數。華中科技大學團隊突破了這一限制,通過視點傳遞的方式克服了環繞相機陣列(Abedi等,2018)以及球面相機陣列(An等,2020)的幾何標定問題,為后續720°交互奠定了基礎。圖3(e)所示的平面模式在幾何分布上是平行模式的簡單擴充,但是在實際應用中產生了許多變型,并逐步演化成光場采集系統,催生了許多交互式媒體之外的新型應用(Levoy和Hanrahan,1996)和億像素采集系統(Brady等,2012)。
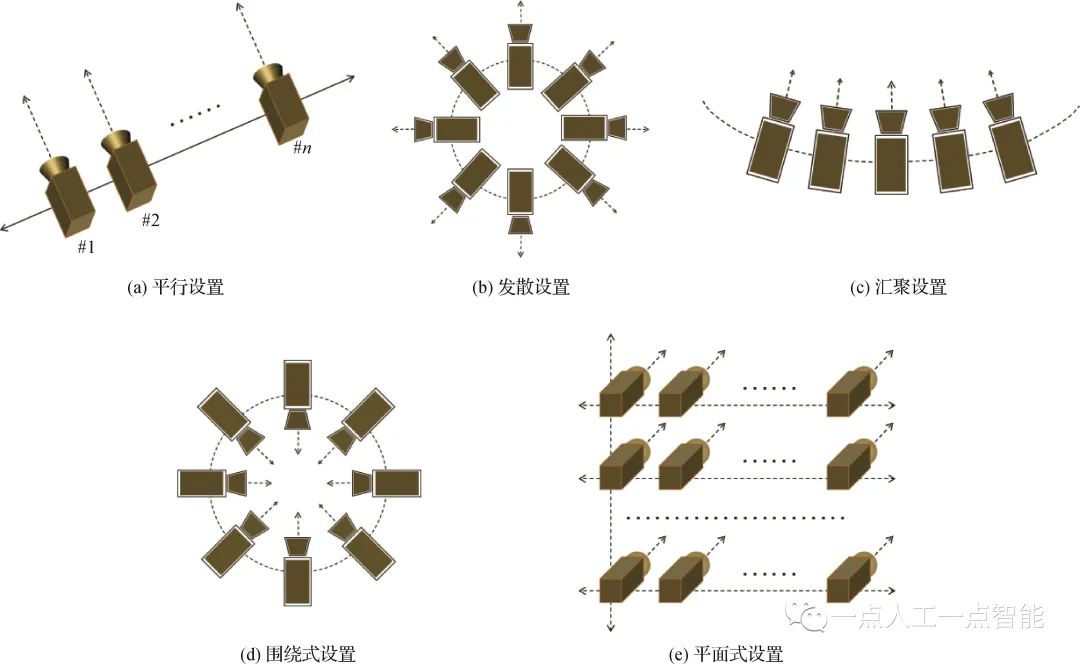
圖3??幾種典型的多視點視頻采集系統的幾何排布方式
1.2 多視點與深度聯合采集
典型的多視點聯合采集需通過后期計算的方式得到深度,如果能夠直接得到深度信息,則可以大幅提升采集效率。然而,直接獲得場景的深度信息并不是一件容易的事情,進而在獲取深度信息的基礎之上是否能夠多視點獲取,又是另外一個難題。 直接獲取場景深度信息的方式大體分為被動式和主動式兩個技術方向。被動式探測以雙目立體匹配為代表(Zhang,2012)。主動式探測方法以結構光技術為代表,并根據光源的不同又分為點掃描(Franca等,2005)、線掃描(Scharstein和Szeliski,2002)和面結構光(Van der Jeught和Dirckx,2016)。點掃描和面掃描中激光器發出點狀或條狀光束,進而通過旋轉或平移,實現完整的3維測量。面結構光方法投射2維編碼圖案,無需移動投影設備即可重建目標表面,具有更高的效率(蘇顯渝 等,2014)。此外,面結構光中投影圖案通常與編碼技術進行結合,提取塊級/像素級/亞像素級的碼字用于視差匹配,以獲得更高的精度和效率。面結構光的編碼通常包括空域編碼、時域編碼和相位編碼,通過多個編碼對場景進行多次掃描來獲得目標場景的深度。上述模式都是通過掃描的方式才能得到場景的深度信息,因此不適宜動態場景的深度獲取。
采用點—面結合技術的Kinect深度傳感器克服了這個難題(Lilienblum和Al-Hamadi,2015),雖然深度圖的質量、圖像分辨率、時間分辨率和探測距離等基本參數還有很大的提升空間,但是該設備的出現首次將場景的深度感知從靜態提升至了動態,給產業界和學術界同時帶來一輪新的研究熱潮。后來出現了基于光調制的ToF(time of flight)技術及相關設備,包括ToF相機和激光雷達(laser radar,LiDAR)等,大幅度提升了探測距離,但是在深度圖質量、圖像分辨率和時間分辨率等參數上也都與Kinect一樣面臨相同的問題。 將多個深度傳感器與多個彩色相機相互配合對場景進行視覺采集,則形成了多視點與深度聯合采集方案。在這些方案中,幾何排布上可以借鑒多視點聯合采集方案。多視點與深度聯合采集的關鍵難點在于多深度采集中所出現的視點間干擾、彩色視頻與深度視頻時間分辨率不匹配以及空間分辨率差距過大等問題。多深度相機之間的干擾來自其成像原理本身,如不同視角的Kinect會使用相似甚至相同的點—面結構光,不同視角的ToF相機對同一波長的光進行相同的調制,這些都會導致解碼失敗。為了解決這個問題,華中科技大學團隊從機理層面進行了探索,針對多種原理的深度傳感器分別設計了包括M-序列等方法在內的多深度相機聯合采集方案,較好地解決了上述難題(Yan等,2014;Li等,2015;Xiang等,2015)。此外,還進一步針對深度視頻與彩色視頻時間分辨率不匹配的問題,以及由此導致的深度圖運動模糊問題,提出了時域上采樣法(Yang等,2012)和時域校正法(Yang等,2015c;?Gao等, 2015)等多種方法,為運動場景的立體感知提供了豐富的工具集。
1.3 深度圖與點云預處理
如前所述,動態場景的深度圖或點云數據往往具有空間分辨率低、時間分辨率低、畫面噪聲多等問題。為了保證下游任務的精度,需要進行預處理。從處理技術上來分,主要包括深度圖預處理和點云數據預處理兩個類型。
1.3.1 深度圖預處理
深度信息不直接用于人眼觀測,而是作為輔助信息幫助參考視點圖像映射到正確的虛擬視點上。深度圖像上的失真會傳播至虛擬視點圖像,造成主客觀質量的下降。因此,在虛擬視點內容生成前,需通過深度預處理技術盡可能獲得最接近場景實際距離的深度圖像。Ibrahim等人(2020a)較詳細地對深度圖預處理技術工作進行了系統性的梳理。總體而言,深度圖、點云的去噪與圖像去噪技術是同步發展的,但同時也有自身的一些特點。典型的圖像濾波器,如多邊濾波器(Choudhury和Tumblin,2005)、流型濾波器(Gastal和Oliveiray,2012)和非區域均值(Buades等,2005)等都可以直接作用于深度圖的去噪,但這些濾波器都只能解決以像素為單位的深度圖噪聲。一旦噪聲區域過大,如Kinect深度傳感器的噪聲多以成片區域深度值缺失為特點,則傳統的濾波器都會失效(Xie等,2015)。
為了解決這個問題,Kopf等人(2007)提出了聯合雙邊濾波方法。該方法是對雙邊濾波的改進,引入了參考圖像為指導,能夠較好地處理大面積深度值缺失的難題,但同時也引入了彩色圖中的邊緣和紋理信息,給去噪后的深度圖帶來了偽紋理。Liu等人(2017)利用對齊彩色圖像特征來引導深度圖像修復,通過彩色信息引導權重并結合雙邊插值方法來進行深度圖空洞修復。Wang等人(2015)提出一種面向Kinect深度圖像恢復的三邊約束稀疏表示方法,在懲罰項上考慮了參考塊與目標塊間的強度相似度和空間距離的約束,在數據保真度項下考慮了目標塊質心像素的位置約束,通過對紋理圖像的特征學習,預測出深度圖像空洞恢復的最優解。為了有效克服偽紋理的問題,Ibrahim等人(2020b)引入條件隨機場方法以抑制在彩色圖引導過程中的紋理干擾問題。
隨著深度學習技術的發展,人們也開始探索單一深度圖(張洪彬 等,2016)、彩色與深度圖聯合(Zhu等,2017)的濾波方案,總體上遵循了彩色圖濾波的基本架構,包括特征提取、圖像重建等模塊。基于深度學習框架的深度圖濾波雖然能夠取得較好的去噪效果,但是目前仍面臨物體邊緣濾波模糊的難題。 多視點聯合濾波也是一個值得關注的課題。如果將每一個視點的深度圖單獨處理,勢必會導致視點間深度不穩定的問題,為此需要將多個視點聯合在一起考慮。華中科技大學團隊He等人(2020b)提出了跨視點跨模態的聯合濾波框架,建立了視點之間的映射模型與關聯方式,能夠較好地克服多種類型的噪聲在不同視點間的蔓延。針對平面相機陣列,Mieloch等人(2021)考慮到紋理信息的使用會在深度修正中引入誤差,僅用多個視點的深度信息對所選視點的信息進行交叉驗證,通過多次迭代,增強了多個深度圖像的視點間一致性,且可以自由設置需要修正的視點位置和數目。
1.3.2 點云預處理
深度相機和激光雷達傳感器產生的原始點云通常是稀疏、不均勻和充滿噪聲的,需要進行去噪或補全。現有的點云補全的方法大致分為基于幾何或對齊的方法和基于表示學習的方法兩類。 基于幾何或對齊的方法包括基于幾何的方法和基于對齊的方法。基于幾何的方法通過先前的幾何假設,直接從觀察到的形狀部分預測不可見的形狀部分(Hu等,2019)。更具體地,一些方法通過生成平滑插值來局部填充表面孔。例如拉普拉斯平滑(Nealen等,2006)和泊松表面重建(Kazhdan和Hoppe,2013),這些方法直接從觀察區域推斷缺失數據并顯示出令人印象深刻的結果,但是需要為特定類型的模型預定義幾何規則,并且僅適用于不完整程度較小的模型。基于對齊的方法在形狀數據庫中檢索與目標對象相似的相同模型,然后將輸入與模型對齊,隨后對缺失區域進行補全。
目標對象包括整個模型(Pauly等,2005)或其中的一部分(Kim等,2013)。除此以外,還有一些方法使用變形后的合成模型(Rock等,2015)或非3D幾何圖元,例如平面(Yin等,2014)和二次曲面(Chauve等,2010)代替數據庫中的3D形狀。這些方法在3D模型的類型上具有較強的泛化性,但在推理優化和數據庫構建過程中成本高,且對噪聲敏感。 基于表示學習的方法是一種點云補全的方法。Dai等人(2017)提出了基于3D體素的編碼器—解碼器架構3D-EPN(3D-encoder-predictor)。盡管基于3D體素化的表示學習方法可以直接擴展使用定義在2D規則網格上的神經層或算子,但精細對象的重建需要消耗大量顯存和算力。隨著基于點表示學習的PointNet(Qi等,2017a)和PointNet++(Qi等,2017b)等模型的出現,人們提出了TopNet(Tchapmi等,2019)、PCN(point cloud net)(Yuan等,2018)和SA-Net(shuffle attention net)(Wen等,2020a)等基于點編碼器—解碼器框架的點云修復模型。該類模型首先通過編碼器從不完整的點云中提取全局特征,再利用解碼器根據提取的特征推斷完整的點云。
現有基于表示學習的點云補全任務的相關研究主要分為兩類。1)基于先進的深度學習框架。為了提高點云生成的完整形狀的真實性和一致性,人們提出了基于對抗生成網絡的RL-GAN-Net(reinforcement learning generative adversarial network)(Sarmad等,2019)、基于變分自動編碼器的VRCNet(variational relational point completion network)(Pan等,2021)和基于注意力機制的PoinTr(Yu等,2021)、SnowflakeNet(Xiang等,2021)、PCTMA-Net(point cloud transformer with morphing atlas-based point generation network)(Lin等,2021)、MSTr(Liu等,2022)等模型,這些模型能更好地挖掘3D形狀的全局和局部幾何結構,從而更有利于補全點云中的不完整部分。2)基于任務特性的算子。為了保留更多的精細特征信息,SoftPool++(Wang等,2022a)設計了softpool算子替代PointNet中的最大池化算子。Wu等人(2021)提出基于密度感知的倒角距離,以改善原有損失函數對點云局部密度不敏感或精細結構保護不足等缺陷。 考慮實際應用需求,漸進式點云補全任務也開始得到關注,人們提出了CRN(cascaded refinement network)(Wang等,2022b)、PF-Net(point fractal network)(Huang等,2020b)、PMP-Net++(point cloud completion by transformer-enhanced multi-step point moving paths)(Wen等,2023)等模型,以實現3D點云的漸進細化。總體而言,基于學習的點云補全方法在性能提升上效果顯著,但在模型泛化上仍有很大的提升空間。如何結合幾何先驗以提升模型的泛化性是一個潛在的研究方向。
02??6DoF視頻壓縮與傳輸
6DoF視頻有多視點視頻、多視點+深度視頻、光場圖像、焦棧圖像和點云序列等多種數據表示方式,本節根據各種數據表示方式的特點,對6DoF視頻壓縮與傳輸的研究進展展開介紹。
2.1 多視點視頻編碼
自從1988年CCITT(Consultative Committee International for Telegraph and Telephone)制定了視頻編碼標準H.261后,視頻編碼技術的應用越來越廣泛,并涌現出大量的視頻編碼標準,包括H.264/AVC(Wiegand等,2003)、H.265/HEVC(high efficiency video coding)(Ohm等,2012)和H.266/VVC(versatile video coding)(Bross等,2021)。最簡單的多視點視頻編碼MVC(multi-view video coding)方案是獨立地對各個視點進行編碼,但是這樣不能充分去除視點間冗余,于是產生了時域—視點域結合的編碼壓縮方案研究。 1)多視點視頻擴展國際編碼標準。MPEG-2標準中已采用了多視點視頻配置來編碼立體或者多視點視頻信號。由于壓縮標準的局限性、顯示技術和硬件處理能力的限制,MPEG-2的多視點擴展沒有得到實際應用。2005年,MPEG組織在H.264/AVC的基礎上提出了MVC擴展標準(Vetro等,2011),并形成了聯合多媒體模型(joint multiview model,JMVM)。該模型集成了視點間亮度補償、自適應參考幀濾波、MotionSkip模式以及視點合成預測等基于宏塊的編碼工具。類似于H.264/AVC的MVC,JCT-3V在H.265/HEVC的基礎上提出了擴展編碼標準MV-HEVC(multi-view HEVC)(Tech等,2016)。我國從1996年開始參加MPEG專家組的工作,不斷有提案被接受,在視頻壓縮的技術成果逐漸具備了國際競爭力。2002年6月,我國成立了數字音視頻編解碼技術標準工作組AVS(audio-video standard),目標是制定一個擁有自主知識產權的音視頻編碼標準。至今,其版本已經發展到AVS3。基于國際編碼標準,國內學者在MVC快速算法、率失真控制和基于深度學習的多視點編碼等方面進行了深入研究,取得了極大的進展。 除了高效的壓縮編碼標準之外,精心設計的預測編碼結構能充分利用多視點視頻信號中的時空相關性和視點間的相關性。目前,MVC中廣泛采用的分層B幀編碼結構(hierarchical B pictures,HBP)結合運動估計和視差估計,獲得了較高的壓縮效率和優秀的率失真性能。
2)面向編碼的多視點視頻預處理。
利用多視點視頻擴展編碼標準壓縮多視點視頻信號時,能在編碼標準框架下同時消除時空冗余和視點間冗余。然而,多視點視頻信號往往存在幾何偏差和顏色偏差,影響了編碼壓縮效率。因此,多視點視頻信號的預處理也能提升壓縮性能。Doutre和Nasiopoulos(2009)對多視點視頻信號進行顏色校正,提升了視點之間顏色一致性和MVC的視點間預測性能。Fezza等人(2014)提出了基于視點間對應區域直方圖匹配方法的多視點顏色校正算法,以提升壓縮性能。福州大學團隊Niu等人(2020)針對多視點視頻信號中存在的全局、局部和時間顏色差異,提出了由粗到細的多階段顏色校正算法。
3)多視點視頻快速編碼。
由于各種編碼標準集成了多種復雜技術,且多視點視頻巨大的數據量也會帶來巨大的時間開銷。因此,多視點彩色視頻編碼的計算復雜度問題長期以來都是難題。針對各種編碼標準和多視點擴展編碼標準,學者們廣泛地開展了快速編碼算法研究。典型的手段包括減少搜索點數(Cernigliaro等,2009)、利用MVC的編碼模式的時空相關性和視點相關性減少當前編碼宏塊的搜索數量(Zeng等,2011)以及基于像素級與圖像組級的并行搜索算法(Jiang和Nooshabadi,2016)等。 國內學者也提出了若干快速編碼算法。Li等人(2008)通過減小搜索范圍和參考幀數目來提高MVC速度。在MVC快速宏塊模式選擇方面,Shen等人(2010)利用相鄰視點的宏塊模式輔助當前視點的宏塊模式選擇,提高編碼速度。Ding等人(2008)通過共享視點間編碼信息(例如率失真代價、編碼模式和運動矢量)來降低MVC的運動估計的計算復雜度。MVC中,大量宏塊的最優模式為DIRECT/SKIP模式。根據此特性,Zhang等人(2013b)提出了Direct模式的提前判斷方法,從而避免所有宏塊模式的搜索過程。Yeh等人(2014)利用已編碼視點的最大和最小率失真代價形成閾值條件,用于提前終止當前編碼視點的每個宏塊編碼模式選擇過程。Pan等人(2015)提出了一種Direct模式的快速模式決策算法,并利用MVC特性,設計了運動和視差估計的提前終止算法。Li等人(2016b)利用宏塊模式的一致性和率失真代價的相關性,提出了Direct模式的判定方法。
4)MVC的碼率控制。
碼率控制旨在提高網絡帶寬利用率和視頻重建質量。與單視點視頻編碼的碼率控制不同,MVC的碼率控制需要考慮視點級的碼率分配。Vizzotto等人(2013)在幀級和宏塊級實現了一種分層MVC比特控制方法,該方法充分利用了當前幀和以編碼相鄰幀比特分布的相關性。Yuan等人(2015)提出了視點間編碼依賴關系模型,認為視點間的依賴關系主要由編碼器的跳躍(SKIP)模式導致,并據此提出了理論上最優的多視點視頻碼率分配與控制算法。
5)基于深度學習的MVC。
Lei等人(2022)提出了基于視差感知參考幀生成網絡(disparity-aware reference frame generation network,DAG-Net)生成深度虛擬參考幀。該網絡包含多級感受野模塊、視差感知對齊模塊和融合重建模塊,能轉換不同視點之間的視差關系,生成更可靠的參考幀。這些參考幀插入到3D-HEVC的參考幀列表中,能提升MVC的編碼效率。Peng等人(2022)提出了基于多域相關學習和劃分約束網絡的深度環路濾波方法。其中,多域相關學習模塊充分利用多視點的時間和視點相關性來恢復失真視頻的高頻信息,分割約束重建模塊通過設計分割損失減少壓縮偽影。
2.2 多視點+深度視頻編碼
多視點彩色加深度(multiview video plus depth, MVD)是一種典型的場景表示方式,MVD信號包括多視點視頻信號和對應的深度視頻信號。多視點視頻信號是利用相機陣列對在同一場景從不同位置采集得到,而對應深度視頻可采用深度相機獲取或者利用軟件估計得到。與傳統的視頻信號相比,MVD的數據量隨著相機數目的增加而成倍增加。
1)多視點+深度視頻國際編碼標準。
為了編碼MVD信號,JCT-3V基于HEVC提出了3D-HEVC的擴展編碼標準(Tech等,2016),該標準能充分利用深度視頻的特性和視點之間的相關性,提升MVD信號的編碼性能。針對沉浸式視頻的最新編碼壓縮標準為ISO/IEC MIV(MPEG immersive video),該標準定義了比特流格式和解碼過程。沉浸式視頻參考軟件TMIV(test model for immersive video)包括編碼器、解碼器和渲染器等,并提供了測試用例、測試條件、質量評估方法和實驗性能結果等。在TMIV中,多個紋理和幾何視圖使用傳統的2D視頻編解碼器編碼為補丁的圖集,同時優化比特率、像素率和質量。
2)多視點+深度視頻快速編碼。
在基于H.265/HEVC及多視點視頻擴展標準方面,學者們提出了基于MV-HEVC和3D-HEVC標準的多視點深度視頻快速編碼算法(張洪彬 等,2016)。由于深度視頻編碼深度視頻信息反映3D場景的幾何信息,最簡單的方法是對深度視頻下采樣,降低編碼復雜度和降低碼率,代價為丟失場景信息,導致繪制失真。Tohidypour等人(2016)利用已編碼信息,結合在線學習的方法,調節3D-HEVC編碼中非基礎視點彩色視頻的運動搜索范圍和降低模式搜索的復雜度。Chung等人(2016)提出了新的幀內/幀間預測和快速四叉樹劃分方案,既提高了3D-HEVC的深度視頻的壓縮率,又提高了壓縮速度。Zhang等人(2018)針對3D-HEVC中深度視頻編碼模式引入的額外編碼復雜度,提出了兩種深度視頻的幀內模式決策方法。Xu等人(2021)基于MV-HEVC編碼平臺,提出了復雜度分配和調節,實現了MVC的編碼復雜度優化,已適應于不同的視頻應用系統。在多視點深度視頻方面,Lei等人(2015)利用MVD視頻信號中的視點相關性、彩色和深度視頻的相關性,提出了多視點深度視頻快速編碼算法。Peng等人(2016)和黃超等人(2018)基于3D-HEVC提出了聯合預處理和快速編碼系列算法,增強了MVD信號中深度視頻的時間不一致性,提高了壓縮效率和編碼速度。
3)多視點+深度視頻編碼碼率控制。
與MVC的碼率控制僅需要考慮視點級的碼率分配不同,MVD編碼進一步需要考慮彩色與深度視頻之間的碼率分配。Yuan等人(2011,2014)最早確定了虛擬視點失真和多視點紋理和深度視頻的編碼失真之間的解析關系,進而將多視點+深度視頻編碼碼率控制問題建模為拉格朗日優化問題,并求得理論上的最優解。Chung等人(2014)提出一種基于新型視點綜合失真模型的比特分配算法,在紋理和深度數據之間優化分配有限的比特預算,以最大化合成的虛擬視圖和編碼的真實視圖的質量。Klimaszewski等人(2014)提出一種新的多視點深度視頻壓縮質量控制方法,建立了深度和紋理量化參數計算的數學模型。De Abreu等人(2015)提出一種在相關約束條件下有效選擇預測結構及其相關紋理和深度量化參數的算法,具有較優的壓縮效率和較低的計算復雜度,為交互式媒體應用提供了一種有效的編碼解決方案。
Fiengo等人(2016)利用最新的對凸優化工具,提出了幀級比特最優速率分配的算法,其碼率控制性能超越標準MV-HEVC。Domański等人(2021)提出一種可用于比特率控制的視頻編碼器模型,該模型適用于MVD編碼,從AVC的模型中,可以快速推導出HEVC和VVC的模型。Paul(2018)提出一種基于3維幀參考結構來提高交互和降低計算時間,增加一個參考幀來提高遮擋區域的率失真性能,采用視覺注意的比特分配以提供更好的視頻感知質量。Liu等人(2011)提出一種MVD的視點、彩色/深度級和幀級的聯合碼率控制算法,利用預編碼及數理統計分析方法實現視點級、彩色/深度級的比特分配。Zhang等人(2013a)提出了基于視點合成失真模型的多視點深度視頻編碼的區域位分配和率失真優化算法,測試序列的編碼效率得到顯著提高。Li等人(2021b)提出了一種基于視圖間依賴性和時空相關性新的多視圖紋理視頻編碼位分配方法,建立了一個基于視圖間依賴關系的聯合多視圖率失真模型。該方法在率失真性能方面優于其他最先進的算法。
4)基于深度學習的深度視頻編碼。
相比于彩色視頻,深度視頻具有更加平滑的內容和更大的空域冗余,可以以更小的分辨率進行編碼,以提高編碼效率。針對深度視頻編碼,Li等人(2022)提出了基于深度上采樣的多分辨率預測框架,該框架對于不同復雜度的深度塊,使用最優的分辨率進行編碼,以提高深度視頻編碼效率。
2.3 光場圖像壓縮
光場圖像壓縮的目的在于去除子視點圖像內部冗余以及子視點圖像間冗余。傳統2D圖像編碼中成熟的幀內壓縮技術可以直接應用于光場圖像壓縮去除子視點圖像內部冗余。因此,光場圖像壓縮的相關研究主要致力于去除視點間冗余(Liu等,2019)。光場圖像的各子視點圖像由于視差變化具有不規則變化的顯著特點,根據建模方法,現有的光場圖像壓縮研究大體可分為基于偽視頻序列的方法、基于優化的方法和基于視點重建的方法3類。
1)基于偽視頻序列的方法。
光場圖像壓縮的關鍵在于如何充分利用子視點圖像間的相關性。相鄰的子視點圖像之間存在著極大比例的重復場景,且由于視差引起的場景變化平緩,與傳統視頻中前后幀中的場景變化較為相似。自然而然地,早期的光場圖像壓縮引入了傳統2D視頻編碼的框架,將光場圖像中的子視點圖按照一定的掃描順序重組為偽視頻序列,將視點間冗余轉化為偽視頻序列的幀間冗余,直接利用成熟的視頻壓縮標準中的幀間預測技術去除視點間冗余。因此,此類研究方案的重點在于如何構建合理的子視點排列順序以及預測結構,從而在偽視頻序列的幀間編碼過程中盡量減少編碼視點與參考視點間的殘差信息,增加壓縮效率。針對掃描順序,國內一些早期的工作(Dai等,2015)中提出了橫向、縱向、之字形和環形的掃描方案,且均取得了一定的性能提升。
而在此類工作中,影響力較大的是由中國科學技術大學Li等人(2017)提出的2維層級編碼框架。在此框架中,首先將所有視點圖劃分為4個象限,再在每個象限中按固定位置劃分為4個編碼層次,沿用傳統視頻編碼中多層次編碼的框架,即在編碼過程中首先使用高保真編碼方案壓縮低層次視點圖,并且在高層次視點圖壓縮時作為參考視點。此外,在選取參考視點圖的過程中,通過衡量與不同參考視點間的距離確定最佳的參考視點,進一步提升壓縮效率。此工作為較早提出的完整的光場編碼框架,經常被后續研究引用作為評價標準。此外,Liu等人(2016)將傳統視頻編碼中的可伸縮編碼思想應用到光場壓縮中,提出了一個包括3層分辨率和質量可伸縮的光場編碼框架。 基于偽視頻序列的壓縮方法致力于將視點間的相關性轉換為時域相關性,從而得以利用視頻編碼技術中的幀間預測技術去除偽視頻序列的時域冗余。然而,傳統視頻編碼的幀間預測技術中,只考慮了前后幀場景間的平移運動,用表征上下、左右位移的2維的運動向量表示。而光場圖像中各個子視點圖像場景間更多的是由于視角變化引起的不規則運動,這與傳統視頻存在本質上的差異。所以,由于缺少針對光場圖像特性的適應性優化,基于偽視頻序列的光場編碼方案難以取得最優的壓縮性能。
2)基于優化的方法。
在基于偽視頻序列壓縮方案的基礎上,一部分研究者致力于研究子視點間場景不規則運動的模型,優化原有光場編碼框架中的部分模塊,以期進一步提升編碼效率。這些研究包括基于單應性變化矩陣、圖變換等優化方案。Chang等人(2006)針對視點間物體的不規則變化,首先利用傳統的圖像分割方法獲取物體形狀,繼而提出了一種視差補償算法來估計相鄰子視點圖中該物體的形狀變化,據此提升預測效率。此外,此工作也在光場編碼基礎框架上提出了改進方案,即使用聚類算法對子視點圖像進行排序,根據聚類結果調整偽視頻幀的排序。Jiang等人(2017)提出了基于單應性變化矩陣的光場圖像編碼框架優化方案。具體的,該方法利用單應性或者多應性變化矩陣將所有子視點圖統一映射到一個或者多個深度面上,繼而在此基礎上求取光場圖像的低秩表示。最后,通過單應性矩陣參數與低秩矩陣的聯合優化,以實現光場低秩表示數據的壓縮。Dib等人(2020)基于超射線表示的視差模型提出了一個局部低秩逼近方法。
超射線由與所有子視點圖像都相關的超像素點構建,通過施加形狀與大小的約束,使得超射線得以表達復雜的場景變換,繼而通過參數化的視差模型描述每條超射線表示幀內的視差局部變化。此模型的最佳參數將通過交替搜索估計的方法確定。 由于圖信號也能較好地描述圖像中物體的不規則運動,部分研究者進而將圖變換應用于光場壓縮的視點間預測模塊。基于圖變換的優化框架最早由Su等人(2017)提出,該方法依據深度信息將所有像素分類并構建圖表示,并在此基礎上對子視點圖間場景的不規則變化進行預測。然而此方案依賴于深度信息,并且基于圖變換的運動預測大幅增加了整體模型的復雜度。針對于此,Rizkallah等人(2021)提出了一個局部圖變換的方法,通過圖規約技術以及譜聚類來減少圖的維度,從而控制算法的整體復雜度,并提出了不同規約方案下重建子視點圖的率失真準則模型,以實現在特定復雜度限制下尋找最優圖構建的目的。 在光場圖像壓縮乃至傳統視頻壓縮領域中,如何描述鄰近視點或幀間場景間的不規則運動是一個長久以來懸而未決的難題。類似于圖變化或者單應性變化矩陣等基于人工設計函數的優化方案受限于其預測的準確率,對整體編碼性能提升較為有限,且極大地增加了整體編碼框架的復雜度,給實際應用帶來了挑戰。
3)基于視角重建的方法。
相比于傳統使用手工設計函數描述復雜運動的優化方案,直接使用智能圖像生成技術以重建鄰近視點圖的方案更為簡潔、高效。深度神經網絡中的先驗知識顯著減少了重建光場圖像所需要傳遞的信息,大幅提升了光場圖像壓縮框架的效率,因此成為當前光場壓縮研究的重要方向。 該類方法首先在所有待壓縮的子視角圖中選取數幅作為關鍵視角(Chen等,2018),壓縮并傳送至解碼端。然后,在編碼非關鍵子視角圖時,將重建后的關鍵視角圖作為輸入,利用圖像生成網絡合成非關鍵視角圖。最后,合成的非關鍵視角圖與原圖之間的殘差將被壓縮并傳送至解碼端。如香港城市大學Hou等人(2019)使用基于深度學習的角度超分辨率模型用于預測非關鍵視角圖。北京大學Jia等人(2019)使用對抗生成模型來學習子視角圖像結構中的角度以及空間變化,從而得以實現更準確的預測非關鍵視角幀的預測。針對低碼率條件下的光場壓縮,Ahmad等人(2020)提出了基于剪切小波變換的非關鍵視角預測方法。Bakir等人(2021)提出了一種自適應的非關鍵視點丟棄的策略,并在解碼端對生成的非關鍵幀進行圖像增強后處理,以進一步提升整體壓縮效率。
2.4 焦棧圖像壓縮
焦棧圖像是光場圖像的降維,其壓縮是一個全新的課題。相比于傳統2D圖像的固定視點、固定對焦的采樣模式,焦棧圖像需要在某一時刻對不同深度的場景進行稠密采集,以獲取完整的場景圖像數據。焦棧圖像序列與普通視頻具有不同的成像特性和冗余模型,普通視頻幀之間的冗余模型通過運動矢量來刻畫,而焦棧圖像序列則通過焦深來刻畫,因此現有編碼框架不適用于焦棧圖像壓縮的目標。 焦棧圖像編碼方法可分為兩類,即基于靜態圖像的編碼和基于視頻的編碼。在基于靜態圖像的編碼方法中,Sakamoto等人(2012a)將焦棧圖像序列劃分為尺寸為8的3D像素塊,然后對每個3D像素塊進行3D-DCT(3D discrete cosine transform)變換和線性量化,并按照頻率從低到高的順序排列為1D(one dimension)信號,最后利用霍夫曼編碼方法將信號寫入碼流完成編碼。
為了抑制圖像退化噪聲,Sakamoto等人(2012b)進一步利用3D離散小波變換對焦棧圖像進行處理,相比于基于3D離散余弦變換的方法,有效抑制了編碼產生的塊效應失真。Khire等人(2012)提出的方法采用差分脈沖編碼調制和相鄰圖像的信息來估計冗余度,獲得了比JPEG和JPEG2000更高的壓縮效率。 基于視頻的編碼方法考慮了序列各幀之間的相關性,通過運動搜索進行幀間預測,相比于基于靜態圖像的編碼方法可獲得更高的壓縮性能。如van Duong等人(2019)面向光場重聚焦應用,將焦棧圖像排列為視頻序列,直接使用HEVC編碼器進行壓縮。然而,這顯然不能挖掘圖像間的焦深冗余。為此,Wu等人(2020b,2022)分別提出了基于高斯1D維納濾波的塊模式單向/雙向焦深預測,以及分層焦深預測的方法,較早地開展了焦深冗余模型的構建。該類型相比于直接利用視頻編碼的方案,壓縮性能上有了極大提升。然而,需要強調的是,焦棧圖像壓縮的研究剛剛起步,尚有許多未知的問題需要探索和研究。
2.5 點云編碼壓縮
3D點云是具有法線、顏色和強度等屬性的無序3D點集。大規模3D點云數據的高效編碼壓縮技術具有廣泛的市場應用前景。現有研究主要可分為傳統壓縮方法和智能壓縮方法兩類。
1)傳統壓縮方法。
為了實現點云數據的高效壓縮,工業界和學術界提出了多種解決方案(Mekuria等,2017)。點云壓縮方法是通過八叉樹等表示方法將點云進行預處理,主要思路有3種。第1種是通過映射,將3維點云轉換成2維圖像后,采用傳統的圖像或者視頻編碼工具進行編碼操作;第2種是首先直接將數據矢量線性變換為合適的連續值表示,獨立地量化其元素,然后再使用多種無損的熵編碼對得到的離散表示進行熵編碼操作;第3種是將八叉樹空間索引信息直接進行編碼。根據組織機構不同,主要可分為運動圖像專家組(MPEG)提出的點云壓縮(point cloud compression,PCC)標準、音視頻標準組(audio video coding standards workgroup,AVS)提出的點云壓縮參考模型(point cloud reference model,PCRM)和谷歌公司研發的“Draco”編碼軟件3類。 2017年MPEG啟動了關于點云壓縮的技術征集提案,此后一直在評估和提升點云壓縮技術的性能。
根據點云壓縮的不同應用場景,MPEG劃分了3類點云數據,并針對3類點云開發了3種不同的編碼模型,分別是用于自動駕駛的動態獲取點云的模型(LiDAR point cloud compression,L-PCC)、針對用于表示靜止對象和固定場景的靜態點云模型(surface point cloud compression,S-PCC)和針對用于沉浸式多媒體通信的動態點云的模型(video-based point cloud compression,V-PCC)。其中,動態獲取點云指點云獲取設備一直處于運動狀態,獲取的點云場景也處在實時變化之中;靜態點云指被掃描物體與點云獲取設備均處于靜止狀態;動態點云指被掃描物體是運動的,但是點云獲取設備處于靜止狀態。由于L-PCC和S-PCC的編碼框架相似,2018年1月MPEG對現有的L-PCC和S-PCC進行整合,推出了全新的測試模型(geometry-based point cloud compression,G-PCC)。2022年MPEG公布了第1代點云壓縮國際標準V-PCC (ISO/IEC 23090-5)和G-PCC (ISO/IEC 23090-9)(Schwarz等,2019)。
其中,V-PCC適用于點分布相對均勻且稠密的點云,G-PCC適用于點分布相對稀疏的點云。G-PCC的幾何信息編碼部分主要是通過坐標變換和體素化(Schnabel和Klein,2006)的方法進行位置量化與重復點移除,然后通過八叉樹構建將3維空間劃分為層次化結構,將每個點編碼為它所屬的子結構的索引,最后通過熵編碼生成幾何比特流信息。屬性信息部分則是通過預測變換、提升變換(Liu等,2020)和區域自適應分層變換(region-adaptive hierarchical transform,RAHT)(de Queiroz和Chou,2016)等進行冗余消除。V-PCC則通過將輸入點云分解為塊集合,這些塊可以通過簡單的正交投影獨立地映射到常規的2D網格,再通過諸如HEVC和VVC等傳統2維視頻編碼器來處理紋理信息及附加元數據。
為了保障我國數字媒體相關產業的安全發展,AVS也成立了點云工作組,并在2019年12月發布了國內第1個點云壓縮編碼參考模型PCRM(point cloud reference model)。PCRM的核心編碼思想與G-PCC類似,同樣是依據點云的幾何結構直接編碼。PCRM的幾何編碼主要是通過多叉樹結構對點云劃分,利用節點之間的關系和占位信息對點云編碼。PCRM的屬性編碼有兩種方案,一種是直接預測編碼;另一種是基于變換的編碼,即對點云的屬性信息進行離散余弦變換。 Draco架構是谷歌媒體團隊提出的開源3D數據壓縮解決方案,使用k-維樹等多種空間數據索引方法對屬性和幾何信息進行量化、預測壓縮以及熵編碼以達到高效壓縮目的。
2)智能壓縮方法。
隨著深度學習的發展及其在數據編碼領域的應用,研究人員提出了基于深度學習的端到端點云編碼方法。2021年MPEG也開展了基于深度學習的點云編碼(artificial intelligence-point cloud compression,AI-PCC)技術探索,并提出標準測試流程。基于深度學習的端到端點云編碼方法主要涉及基于體素表示、基于點表示和深度熵模型3種方式。 基于體素表示的方法是將點云轉換為體素化的網格表示,再對體素進行編碼與壓縮。Quach等人(2019,2020)和Wang等人(2021b)受基于學習的圖像壓縮方法的啟發,使用基于3D卷積的自編碼器,在體素上提取潛在表示作為點云的幾何編碼并在體素上執行二分類任務以重建點云幾何信息。由于點云的稀疏性,點云占據的體素只占全部空間的小部分,體素網格中的大部分空間保持空白,導致存儲和計算的浪費。
為了克服這一缺陷,南京大學Wang等人(2021a)利用稀疏體素代替稠密體素,并通過Minkowski稀疏卷積來降低內存要求以提升編碼性能。 基于點表示的方法直接使用神經網絡處理點云,而不需要額外的體素化。浙江大學Huang等人(2019)直接使用自編碼器用于點云幾何壓縮。深圳大學Wen等人(2020b)提出了一種用于大規模點云的自適應八叉樹劃分模塊,并使用動態圖卷積神經網絡作為點云自編碼器的核心骨干網絡。為了獲得更好的率失真性能,Wiesmann等人(2021)使用核點卷積,南京大學Gao等人(2021)使用神經圖采樣來充分利用點的局部相關性。 深度熵模型將點云構建成八叉樹形式,并在八叉樹上應用神經網絡估計概率熵模型。Huang等人(2020a)使用簡單多層感知機,根據在八叉樹上收集到的上下文信息來進行熵估計。
Biswas等人(2020)考慮點云序列間的上下文,并將該上下文信息引入到神經網絡估計的熵模型中,以提升點云序列編碼與壓縮的性能。北京大學Fu等人(2022)基于注意力機制,充分利用長距離的上下文信息,以進一步提升編碼與壓縮性能。為了避免過多的上下文信息所引入的額外編解碼復雜度,南京大學Wang等人(2022a)提出了輕量級SparsePCGC(sparse point cloud grid compression)模型,該模型已參與了最新的MPEG AI-PCC的基線評測。目前,使用深度學習技術進行點云屬性壓縮的工作較少,是一個有待于進一步探索的領域。目前代表性的方法是由中山大學Fang等人(2022)提出的3DAC(three dimensional attribute coding)算法,該方法首先將帶有屬性的點云構建為RAHT樹,并使用神經網絡為RAHT樹構建上下文熵模型,以消除統計冗余。此外,Tang等人(2018,2020)提出基于隱函數表示的自編碼器結構,以實現3D/4D點云數據的高效壓縮。
2.6 6DoF視頻傳輸優化
6DoF視頻的典型應用是擴展現實(extended reality,XR)(Hu等,2020)。XR業務的典型特征是高數據速率和嚴格的時延預算,因此被歸類在5.5G愿景中的eMBB(enhanced mobile broadband)和URLLC(ultra reliable low latency communication)業務之間。早在2016年,3GPP(3rd generation partnership project)已開展支撐XR業務的標準化工作,其中服務和系統工作組定義了高速率和低延遲XR應用程序。2018年,多媒體編解碼器、系統和服務工作組繼續開展這項工作,報告了相關流量特征。與此同時,系統架構和服務工作組標準化了新的5G服務質量標識符,以支持包括XR在內的交互式服務。各種XR應用程序和服務都有其用戶設置、流量和服務質量指標,3GPP SA4為XR業務確定了20多個XR用例,對無線解決方案的性能評估提出了挑戰。在此基礎上,3GPP建議將XR用例分為3個基本類別,即虛擬現實(virtual reality,VR)、增強現實(augmented reality,AR)和云游戲(cloud game,CG)。對于無線傳輸來說,XR業務的兩個關鍵性能指標是容量和功耗。
在方案對比之前,所有參會組織為容量和延遲約束定義了以用戶為中心的聯合度量方式,即滿足用戶數。由于XR業務對時延敏感,因此延遲接收到的數據包與丟失的數據包是等同的,這些超時接收到的數據包將被統計到誤包率中。 目前較為主流的VR服務模式是基于視場角的數據流(viewport-dependent streaming,VDS)。VDS是一種自適應流方案,使用網絡狀態和用戶姿勢信息來調整3D視頻的比特率(Yaqoob等,2020)。具體而言,就是基于用戶的位置和方向將全景視頻在3D空間上劃分為獨立的子圖像,流服務器通過存儲不同質量(即視頻分辨率、壓縮和幀率)的子圖像提供多種表示,由用戶動作來觸發新視頻內容的傳輸。下載視場(field of view,FOV)中的所有子圖后,用戶的XR終端設備將進行渲染,然后進行顯示。
VDS的使用意味著VR服務伴隨著上行頻繁更新的動作、控制信號,會帶來高速的下行傳輸速率。對于XR CG,控制信號包括手持控制器輸入和3DoF/6DoF運動樣本,即旋轉數據(“滾動”、“俯仰”和“偏航”)以及用戶設備的3D空間位移數據。相關研究工作主要包括基于用戶視口軌跡的預測方案和基于混合方法的預測方案兩類。
1)基于用戶視口軌跡的預測方案。
Nasrabadi等人(2020)提出了一種基于聚類的視口預測方法,該方法結合當前用戶的視口變化軌跡和以前觀看者的視口軌跡。算法每隔一定的時間將以前的用戶基于他們的視口模式進行聚類,并決定當前用戶所屬類別,從而利用該類中的視口變化模式預測當前用戶的未來視口。Feng等人(2020)提出的LiveDeep方法采用了一種混合方法來解決VR直播流媒體的訓練數據不足的問題,并基于卷積神經網絡(convolutional neural network,CNN)模型分析視頻內容,通過長短時記憶循環神經網絡對用戶感知軌跡進行預測,以消除單一模型造成的不準確性。類似地,Xu等人(2018)為了避免頭部運動預測錯誤,提出了一種概率視口預測模型,該模型利用了用戶方向的概率分布。Yuan等人(2020)采用高斯模型估計用戶未來運動視角,并采用Zipf模型估計不同視角的優先級,進而保障用戶觀看視角的時間—空間質量一致性。
Hou等人(2021)提出了基于長短時記憶循環神經網絡的視口預測模型。該模型使用過去的頭部運動來預測用戶注視點的位置,實現了最優段預取方法。 Fan等人(2020)提出利用傳感器和內容特性來預測未來幀中每個Tile的觀看概率。為了提高預測性能,提出了幾種新的增強方法,包括生成虛擬視口、考慮未來內容、降低特征采樣率以及使用更大的數據集進行訓練。Chen等人(2021)提出了一種用戶感知的視口預測算法Sparkle。該方法首先進行測量研究,分析真實的用戶行為,觀察到視圖方向存在急劇波動,用戶姿勢對用戶的視口移動有顯著影響。此外,跨用戶的相似性在不同的視頻類型中是不同的。基于此,該方法進一步設計了基于用戶感知的視口預測算法,通過模擬用戶在分片地圖上的視口運動,并根據用戶的軌跡和其他類似用戶在過去時間窗口的行為來確定用戶將如何改變視口角度。
2)基于混合方法的預測方案。
該類方法在視口預測時除了考慮用戶的頭部跟蹤歷史數據,還結合了其他能反映視頻內容特性的數據。Nguyen等人(2018)將全景顯著性檢測模型與頭部跟蹤歷史數據相結合,以實現頭部運動預測的精細化預測。Ban等人(2018)利用360°視頻自適應流媒體中的跨用戶行為信息進行視口預測,試圖同時考慮用戶的個性化信息和跨用戶行為信息來預測未來的視口。與以往基于圖像像素級信息的視口預測方法不同,Wu等人(2020a)提出了基于語義內容和偏好的視口預測方法,從嵌入的觀看歷史中提取用戶的語義偏好作為空間注意,以此幫助網絡找到未來視頻中感興趣的區域。類似地,Feng等人(2021b)提出的LiveROI(live region of interest)視口預測方案采用實時動作識別方案來理解視頻內容,并根據用戶軌跡動態更新用戶偏好模型,在不需要歷史用戶或視頻數據的情況下有效預測視口。
實時視口預測機制LiveObj(live object)通過對視頻中的對象進行語義檢測并跟蹤,再通過強化學習算法實時推斷,從而實現用戶的視口預測。Zhang等人(2021b)將頭部運動預測任務建模為稀疏有向圖學習問題。在最新的研究中,Maniotis和Thomos(2022)將VR視頻在邊緣緩存網絡中的內容放置看做馬爾可夫決策過程,然后利用深度強化學習算法確定最優緩存放置。Kan等人(2022)提出了一種名為RAPT360(rate adaptive with prediction and trilling 360)的策略,通過擬合不同預測長度下基于拉普拉斯分布的預測誤差概率密度函數,以提高視口預測方法的準確性。提出的視口感知自適應平鋪方案可根據視口的2維投影的形狀和位置分配3種類型的平鋪粒度。 當前,6DoF視頻傳輸優化的研究重心已逐漸從全景視頻碼流轉向點云碼流。隨著數據量的顯著增大,6DoF視頻傳輸優化不僅需要考慮視口的自適應預測,還要在編碼壓縮時考慮到碼流容錯和糾錯能力。此外,為了應對移動終端算力不足的限制,還需要考慮邊緣服務器的動態配置與卸載。
03??6DoF視頻交互與顯示
6DoF視頻允許用戶自由選擇觀看視角,這就需要給用戶提供大量可供自由選擇的視點內容。然而,對任意視角進行視覺內容的采集需要記錄的數據量非常大,給采集、存儲和傳輸過程造成很大的負擔。因此,在實際的場景環境中,通常采集場景中有限的視點信息,并借助已有視點信息,依靠虛擬視點繪制技術繪制出未采集的視點(即虛擬視點)畫面,以供用戶自由切換。 現有的虛擬視點圖像繪制技術研究正向6DoF方向發展(Jin等,2022)。虛擬視點技術的相關研究與應用大部分還停留在水平基線繪制階段。考慮到平移自由度是沉浸式視頻系統中向用戶提供運動視差的關鍵,MPEG開展了關于平移自由度的探索實驗。其中,基于4參考視點的虛擬視點視覺內容繪制算法可以在用戶切換觀看視點時提供更多的平移自由度,成為近年來的研究熱點。繪制算法存在影響用戶感知的偽影、背景滲透等繪制失真,且3維映射環節存在計算冗余導致繪制速度較慢,同時參考視點的數量增長進一步增加了3維映射環節的時間消耗,所以繪制技術還存在改進的空間。以下將從解碼后濾波增強和虛擬視點合成兩個角度展開討論。
3.1 解碼后濾波增強
3.1.1 深度圖濾波
由于深度圖紋理較少,通常會在編碼端以高壓縮比進行編碼,從而使得解碼端的深度圖質量較低,這給虛擬視點繪制帶來挑戰。Yang等人(2015a)提出了直接利用編碼參數(如運動矢量、塊模式等)來進行深度圖濾波的方法。Yuan等人(2012)證明3D視頻編碼誤差服從平穩白噪聲的分布規律,并據此首次提出了基于維納濾波的深度圖濾波和虛擬視圖濾波方法。Yang和Zheng(2019)提出了一種新型局部雙邊濾波器,為不太可能受到噪聲影響的像素賦予了更高的權重,但沒有徹底解決邊緣輪廓中的不連續性問題。Yang等人(2019)和He等人(2020a)提出了一種跨視點的多邊濾波方法,最終提升了虛擬視點繪制質量。He等人(2020b)針對有損編碼造成的深度失真提出了一種跨視點優化濾波方法,該方法設計了一個互信息度量來模擬跨視點質量一致性的約束,其中包括數據精度和空間平滑性,可以恰當地處理對象邊緣上的振鈴和錯位偽影。 3.1.2 點云上采樣 點云上采樣任務的目標是對低分辨率稀疏點云進行上采樣,生成一個密集、完整且均勻的點云,并需要保持目標物體的形狀。現有的點云上采樣的方法大致可以分為基于優化和基于深度學習兩大類。
1)基于優化方法的模型。
該類型方法一般依賴于幾何先驗知識或者一些額外的場景屬性。為了上采樣稀疏點集,Alexa等人(2003)提出在局部切線空間的Voronoi圖頂點處插入點。Lipman等人(2007)引入了局部最優投影算子來重新采樣點并基于L1范數重建曲面。Huang等人(2009)設計了一種帶迭代正態估計的加權策略,以整合具有噪聲、異常值和非均勻性的點集。Huang等人(2013)提出邊緣感知的點集重采樣方法,以實現漸進式點集上采樣。Wu等人(2015)通過引入新的點集表示方法,以改善孔洞和缺失區域的填充質量。由于上述方法在建模時依賴于目標點云的先驗假設,僅適用于光滑平面,對含有大量噪聲的稀疏點云上采樣效果有限。
2)基于數據驅動的模型。
Yu等人(2018b)首次提出了基于數據驅動的點云上采樣模型PU-Net(point cloud upsampling network)。相比基于優化方法的模型,PU-Net顯著提升了點云上采樣的性能。為了充分利用點云中的全局與局部幾何結構,EC-Net(edge-aware point set consolidation network)(Yu等,2018a)實現了邊緣感知點云上采樣,進一步提高了表面重建質量。為了處理大規模點集,Wang等人(2019)提出的MPU模型在訓練集生成時,將上采樣目標物體分割成小尺度的片元。 根據模型改進的手段不同,現有的研究工作主要可分為4類。 1)基于先進的神經網絡架構。如PU-GAN(point cloud upsampling adversarial network)(Li等,2019a)通過利用生成對抗網絡學習合成潛伏空間中均勻分布的點。PU-GCN(Qian等,2021)基于圖卷積網絡來高效提取點云局部結構信息。PU-Transformer(Qiu等,2022)借助多頭自注意力機制和位置編碼,以增強模型的表示學習能力。PUFA-GAN(Liu等,2022)通過分析點云的頻域信息,進一步增強模型的表達和學習能力。 2)基于幾何先驗的模型設計。
如PUGeo-Net(geometry-centric network for 3D point cloud upsampling)(Qian等,2020)不僅利用點云的坐標信息,還使用了點云的法向量信息來顯式學習目標物體的局部幾何表示。深圳大學Zhang等人(2021a)提出了基于可微渲染的點云上采樣網絡,通過最小化含有重建損失和渲染損失的復合損失函數來生成高質量的稠密點云。Dis-PU(point cloud upsampling via disentangled refinement)(Li等,2021a)首先生成一個能覆蓋物體表面的稠密點云,然后再通過微調點的位置來保證點云的分布均勻性。 3)任意倍數上采樣策略。Meta-PU(meta point cloud upsampling)(Ye等,2022)采用元學習的方式動態調節上采樣模塊的權重,從而使得模型訓練一次就可以支持不同倍率上采樣需求。在線性近似理論的基礎上,Qian等人(2021)自適應地學習插值權重以及高階近似誤差。Mao等人(2022)在歸一化流約束下的特征空間中構建可學習的插值過程。Zhao等人(2022)選擇多個靠近物體隱式表面的體素化的點云中心作為種子點,再將種子點密集且均勻地投射到物體的隱式表面,最后通過最遠點采樣,實現任意倍率的點云上采樣任務。 4)自監督學習策略。為了提升模型的泛化性。SPU-Net(self-supervised point cloud upsampling)(Liu等,2022)將自監督學習應用在點云上采樣任務中。總體而言,現有基于學習的方法依賴于數據集特性,在實際應用時的泛化性能仍有很大提升空間。未來結合優化和數據驅動方法,提升點云上采樣任務的性能是一個很有潛力的研究方向。
3.2 虛擬視點合成
按照繪制機理不同,虛擬視點合成方法可根據6DoF視頻內容劃分為基于模型的繪制(model based rendering,MBR)和基于圖像的繪制(image based rendering,IBR)兩類。MBR是利用3維網格或者點云數據建立3維立體模型,從而重建出趨于真實的場景(Chen等,2019)。其中,在基于網格的表示方式中,通過基于三角形的方式來表示場景中的對象,對于靜態場景可以較好地通過數十、數百或者數千幅輸入圖像的匹配特征進行劃分,獲得明確的3D模型。然而,由于網格的不規則性和低細節,從重建的場景中生成動態的新對象是一項困難的任務。MBR方法適用于簡單場景,復雜場景中數據量會隨著場景復雜度的增加而急劇增長,不適用于追求強烈交互感的沉浸式場景。IBR方法是使用獲取的圖像的顏色值來恢復場景的外觀,目前有兩種方式,即基于光場圖像的繪制方法和基于深度圖像的繪制方法(depth image-based rendering,DIBR)(Bonatto等,2021)。
與DIBR技術相比,基于光場圖像的繪制由于光場數據中含有大量不易壓縮的高頻信息,實際采集、存儲、傳輸以及終端內容生成的任務都更重,而且產生重影、偽影等失真的概率也更大。DIBR使用的數據更簡單,易于處理,技術復雜度低,對設備要求不高,可以生成更具真實感的視覺內容。隨著深度估計算法和多視點視覺內容獲取技術的長足進步,DIBR技術已成為實現6DoF視頻的基礎技術。基于神經輻射場的視點合成方法得到了廣泛關注(Xu等,2021)。本部分將重點介紹基于深度圖像的虛擬視點繪制技術和基于神經輻射場的視點合成技術。 ?
3.2.1 基于深度圖像的虛擬視點繪制
DIBR技術包括3維映射(3D-Warping)、視點融合和空洞填補3個環節,考慮到深度圖的質量對繪制虛擬視點質量也具有重要意義,因此圍繞DIBR技術的研究可劃分為3D-Warping優化與加速、視點融合優化和空洞填補優化。
? 1)3D-Warping優化與加速。
3D-Warping是DIBR的核心環節,這一環節對虛擬視點生成的質量和速度有重要影響。Nonaka等人(2018)提出了利用圖形處理器并行編程的實時虛擬視點視覺內容繪制方法,大幅降低了繪制一幀圖像所需的時間。但這類方法對用戶使用的硬件配置提出了較高的要求,另一方面,在算法層面上不去除冗余,仍會占用一定的開銷。 針對由3D-Warping環節所引起的繪制質量不佳問題,Ni等人(2009)提出了一種針對匯聚相機陣列的啟發式融合插值算法,融合插值過程中考慮了深度、映射像素位置和視點位置,然而難以自適應地確定合適尺寸的窗口。Fachada等人(2018)提出一種支持寬基線場景的視點繪制方法,參考視點圖像被劃分為以像素中心為頂點的三角形,在映射圖像中重新形成的三角形中的像素通過三線性插值進行填充,提高了切向曲面的繪制質量。 針對由3D-Warping環節所引起的繪制速度過慢問題,國內研究者提出利用專用的現場可編程邏輯門陣列設備(Li等,2008)和超大規模集成電路設備(黃超 等,2018)來解決。為了從算法層面提升繪制速度,Jin等人(2016)提出了區域級的映射方法,根據區域的不同特征將區域分類,僅對包含重要信息的區域進行映射操作,避免計算中的冗余信息,大幅減少了映射時間,但由于不同區域利用的是來自不同視點的信息,生成的圖像中存在明顯的區域邊界。在提升繪制質量方面,Fu等人(2017)提出一種基于變換域的用于多視點混合分辨率圖像的超分辨率方法,并基于目標低分辨率視點和輔助高分辨率視點之間相關性的最優權重分配算法,可以為低分辨率幀的視點圖像提供更多細節信息。Nie等人(2017)針對寬基線街道圖像提出了一種新穎的單應性限制映射公式,該公式通過利用映射網格的一階連續性來增強相鄰超像素間單應性傳播的平滑度,可以消除重疊、拉伸等小偽影。 ?
2)視點融合優化。
不同的融合策略會影響虛擬視點繪制圖像絕大部分區域的內容。Vijayanagar等人(2013)根據1維鄰域中非空洞像素的數量來優化左右參考視點映射圖像的融合權重,但該方法僅能改善空洞附近的失真。Lee等人(2016)利用邊緣信息提取出深度圖的不可靠區域,根據顏色相似性、深度可靠性和深度值進行視點融合,減少了偽影和模糊。Wegner等人(2016)采用Z-Buffer技術對深度差區域進行視點融合,但該方法需要準確的深度圖。Ceulemans等人(2018)提出了一種針對寬基線相機陣列的多視點繪制框架,首先對深度圖進行預處理以避免不可靠的信息在整個幀中傳播,并且利用加權顏色混合結合直方圖匹配確保了參考攝像機的顏色直方圖之間的平滑過渡。Sharma和Ragavan(2019)利用幾何信息得到紋理匹配概率,自適應地融合參考視點的紋理和深度信息。
de Oliveira等人(2021)采用快速分層超像素算法來計算視差和顏色相似性,增強了圖像中結構的一致性。 針對平面相機陣列,Chang和Hang等人(2017)提出了一種改進的多參考視點融合算法,選擇距離最接近的參考視點作為主導參考視點,并根據其他輔助參考視點的深度和顏色信息修復深度邊緣區域中的錯誤像素。但由于視點切換過程中主導參考視點會發生變化,用戶自由巡航時易產生不連續感和出畫感。Kim等人(2021)通過直方圖匹配去除了由于圖像對比度不一致而導致的誤差,解決了圖像之間差異較大時出現的失真。Qiao等人(2019)采用多項式擬合方法進行視點亮度校正,提升了虛擬視點融合準確度。 ?
3)空洞填補優化。
由于遮擋、采樣精度不夠高、計算中的舍入誤差以及視野的局限性等原因,融合后的虛擬視點圖像中存在部分缺失信息的區域需要填補以協調圖像的整體視覺效果。空洞填補是利用DIBR過程進行虛擬視點繪制的困難挑戰之一,根據參考信息來源可以分為基于圖像修復的方法、基于時域的方法和基于空域的方法。 Criminisi等人(2004)提出的修復方法可以在不引入模糊偽影的情況下填充較大的空洞。該方法通過復制來自虛擬視點圖像非空洞區域的最佳匹配塊來填充空洞,但是有時會錯誤地采用前景紋理來填充孔洞。因此,基于鄰域信息傳播的算法會在空洞附近產生模糊偽影。Kim和Ro(2017)提出了一種具有時空一致性和雙目對稱性的可靠標簽傳播方法,將相鄰視圖和前一幀中使用的可靠標簽傳播到要填充的目標圖像,可以避免前景用于空洞填充的發生。Kanchana等人(2022)基于深度學習的方法進行空洞填補,結合時間先驗和歸一化深度圖來預測填充向量,可以提高繪制視點的時空一致性。 實際上,當視點切換時,捕捉時域上的信息更難,所以一些研究者提出了基于空域信息的空洞填補方法。Yao等人(2014)利用時域信息來輔助空洞填補。
首先利用紋理和深度信息的時間相關性來生成背景參考圖像,然后將其用于填充與場景的動態部分關聯的孔洞;而對于靜態部分,則使用傳統的修補方法。該方法可以避免部分區域的閃爍效應,但是會產生時延現象。Luo等人(2018)提出一種基于快速馬爾可夫隨機場的空洞填補方法,將圖像修復作為能量優化問題并通過循環置信傳播來解決,而且利用深度信息來阻止前景紋理錯誤填充。Lie等人(2018)提出一種建立背景子畫面模型填充空洞的方法,通過將視頻的空間和時間信息逐步整合到統一的背景子模型中,從而利用真實的背景信息來恢復空洞,但其需要每一幀模型的更新維護和額外的過程,會導致時間復雜度增加。
Rahaman和Paul等人(2018)采用高斯混合模型(Gaussian mixed model,GMM)方法來分離背景和前景像素,并通過對相應的GMM模型和映射圖像像素亮度的自適應加權平均來恢復映射過程中引入的缺失像素,但其學習率需預先訓練得到且無法改變,魯棒性較差。Thatte和Girod(2019)通過挖掘空洞區域的特性,設計出一種統計模型來預測視點切換而導致虛擬視點圖像中丟失數據的可能性,但只能用于單自由度視點切換的情況。Zhu和Gao(2019)針對GMM對于往復運動的局限性,提出了一種改進方法,使用深度信息來調整GMM的學習率,提高了辨別前景像素和背景像素的準確性。Luo等人(2020)提出了一種包括前景提取、運動補償、背景重構和空洞填補4個模塊的空洞填充框架,可使用或擴展現有的大部分背景重建方法和圖像修復方法作為該框架的模塊。 現有的空洞填補算法存在一定的局限,且不可避免地會引入邊緣模糊,無法完全恢復出空洞中的真實信息。基于四參考視點的DIBR算法通過引入更多參考視點的方式顯著減少了空洞區域,尤其是消除了位于視野邊界的空洞,僅剩余部分公共小塊空洞,提升了虛擬視點圖像的主客觀質量。 ?
3.2.2 基于神經輻射場的視點合成
Mildenhall等人(2020)提出了基于神經輻射場的視點合成方法NeRF(nueral radiance field),該算法使用全連接(非卷積)深度網絡表示場景,其輸入是單個連續5D坐標(3維空間位置和觀察方向),輸出是可支持任意視角查看的3維體素場景。算法通過沿相機光線查詢5D坐標來合成視圖,并使用經典的體渲染技術將輸出顏色和密度投影到圖像中。因為體積渲染是自然可微的,所以優化表示所需的唯一輸入是一組具有已知相機姿勢的圖像。該算法描述了如何有效地優化神經輻射場以渲染具有復雜幾何和外觀的場景的逼真的新穎視圖,并展示了優于先前神經渲染和視點合成工作的結果。
在此基礎上,Barron等人(2021)提出了Mip-NeRF的解決方案,擴展了NeRF以連續值的比例表示場景。通過有效地渲染抗鋸齒圓錐截頭體而不是射線,Mip-NeRF減少了鋸齒偽影并顯著提高了NeRF表示精細細節的能力。針對全景視頻輸入,Barron等人(2022)提出了解決采樣和混疊問題的NeRF變體Mip-NeRF360,使用非線性場景參數化、在線蒸餾和基于失真的正則化器來克服無界場景帶來的模糊或低分辨率的渲染問題。Wang等人(2021c)提出了一種雙向陰影渲染方法來實時渲染全景視頻中真實和虛擬對象之間的陰影。Hong等人(2022)將神經輻射場與人體頭部的參數表示相結合,提出了基于NeRF的參數化頭部模型HeadNeRF,可以在GPU(graphics processing unit)上實時渲染高保真頭部圖像,并支持直接控制生成圖像的渲染姿勢和各種語義屬性。總體而言,基于神經輻射場的視點合成方法已得到產業界和學界的廣泛關注,隨著模型訓練速度的大幅提升和漸進式渲染技術的廣泛研究,將具有非常大的應用潛力。
04??發展趨勢與展望
6DoF視頻技術的發展將為未來元宇宙時代的到來奠定基礎,并且將呈現多維度的發展,包括感官豐富程度的提升、分辨率和碼率的提升、時延和可靠性需求的提升以及與現實的交互程度的提升。從這些維度出發,對6DoF視頻技術的內容采集與預處理、壓縮與傳輸以及交互與顯示提出了更高的要求與挑戰。 ?
1)6DoF內容采集與預處理。
內容采集的難度以及后期制作技術的復雜程度直接影響了6DoF視頻內容制作的難度,因此長期以來是限制6DoF視頻發展的主要原因。從發展需求來看,未來的研發方向包括兩個方面:(1)輕量化和低成本的視頻采集系統。例如,手持彩色3維掃描儀、手持多視點采集系統等裝備已經開始具有這些特點,但是距離實際應用還有較長的演進路線;(2)高效、智能的視頻內容處理技術。當前技術在幾何標定、深度圖去噪等方面已經有較好的積累,但適用范圍還比較有限,亟需適應面更廣、處理流程更智能的技術。 ?
2)6DoF視頻壓縮與傳輸。
該方向的研究熱點主要集中于高效點云壓縮和數據傳輸策略。一方面,現有的點云壓縮算法仍存在數據分布刻畫難、場景先驗利用少和計算復雜度高等挑戰。基于3維場景智能分析的大規模3D點云壓縮研究,可以實現非結構化點云數據的場景—目標—要素多目標層次化表示,然后根據應用場景類型和目標特性做針對性壓縮,以改善重建點云中存在的細節丟失和全局形變等問題,進而實現高效的點云數據編碼壓縮,是潛在的發展趨勢。另一方面,相對于傳統視頻流式傳輸場景,點云視頻特有的傳輸方式對資源調度優化引入了新的挑戰。例如,在碼流傳輸過程中需要考慮預測視口大小與點云質量等指標之間的平衡。將強化學習在傳統視頻流式傳輸場景中的應用遷移到點云視頻流式傳輸場景中,并針對新場景進行適應性的改進與優化,是一個有潛力的研發方向。 ?
3)6DoF視頻交互與顯示。
未來云渲染架構下,大量的視點合成和渲染計算工作都位于云端服務器上完成,可以有效降低終端的計算負載和功耗,同時也使終端的佩戴重量盡可能降低。同時,借助終端的異步時間扭曲技術,實時視頻的端到端時延要求可放松至70 ms,實現無眩暈感的沉浸式視頻體驗。如何對端、管、云三者高效協同,將是未來6DoF視頻交互與顯示的重要技術方向。
編輯:黃飛
?












 工商網監
工商網監
評論