 電子發(fā)燒友App
電子發(fā)燒友App


語音是人類最自然的交互方式。計算機發(fā)明之后,讓機器能夠“聽懂”人類的語言,理解語言中的內(nèi)在含義,并能做出正確的回答就成為了人們追求的目標(biāo)。我們都希望像科幻電影中那些智能先進的機器人助手一樣,在與人進行語音交流時,讓它聽明白你在說什么。語音識別技術(shù)將人類這一曾經(jīng)的夢想變成了現(xiàn)實。語音識別就好比“機器的聽覺系統(tǒng)”,該技術(shù)讓機器通過識別和理解,把語音信號轉(zhuǎn)變?yōu)橄鄳?yīng)的文本或命令。
語音識別技術(shù),也被稱為自動語音識別AutomaTIc Speech RecogniTIon,(ASR),其目標(biāo)是將人類的語音中的詞匯內(nèi)容轉(zhuǎn)換為計算機可讀的輸入,例如按鍵、二進制編碼或者字符序列。語音識別就好比“機器的聽覺系統(tǒng)”,它讓機器通過識別和理解,把語音信號轉(zhuǎn)變?yōu)橄鄳?yīng)的文本或命令。
語音識別是一門涉及面很廣的交叉學(xué)科,它與聲學(xué)、語音學(xué)、語言學(xué)、信息理論、模式識別理論以及神經(jīng)生物學(xué)等學(xué)科都有非常密切的關(guān)系。語音識別技術(shù)正逐步成為計算機信息處理技術(shù)中的關(guān)鍵技術(shù)。
語音識別技術(shù)的發(fā)展
語音識別技術(shù)的研究最早開始于20世紀50年代, 1952 年貝爾實驗室研發(fā)出了 10 個孤立數(shù)字的識別系統(tǒng)。從 20 世紀 60 年代開始,美國卡耐基梅隆大學(xué)的 Reddy 等開展了連續(xù)語音識別的研究,但是這段時間發(fā)展很緩慢。1969年貝爾實驗室的 Pierce J 甚至在一封公開信中將語音識別比作近幾年不可能實現(xiàn)的事情。
20世紀80年代開始,以隱馬爾可夫模型(hidden Markov model,HMM)方法為代表的基于統(tǒng)計模型方法逐漸在語音識別研究中占據(jù)了主導(dǎo)地位。HMM模型能夠很好地描述語音信號的短時平穩(wěn)特性,并且將聲學(xué)、語言學(xué)、句法等知識集成到統(tǒng)一框架中。此后,HMM的研究和應(yīng)用逐漸成為了主流。例如,第一個“非特定人連續(xù)語音識別系統(tǒng)”是當(dāng)時還在卡耐基梅隆大學(xué)讀書的李開復(fù)研發(fā)的SPHINX系統(tǒng),其核心框架就是GMM-HMM框架,其中GMM(Gaussian mixture model,高斯混合模型)用來對語音的觀察概率進行建模,HMM則對語音的時序進行建模。
20世紀80年代后期,深度神經(jīng)網(wǎng)絡(luò)(deep neural network,DNN)的前身——人工神經(jīng)網(wǎng)絡(luò)(artificial neural network, ANN)也成為了語音識別研究的一個方向。但這種淺層神經(jīng)網(wǎng)絡(luò)在語音識別任務(wù)上的效果一般,表現(xiàn)并不如GMM-HMM 模型。
20世紀90年代開始,語音識別掀起了第一次研究和產(chǎn)業(yè)應(yīng)用的小高潮,主要得益于基于 GMM-HMM 聲學(xué)模型的區(qū)分性訓(xùn)練準(zhǔn)則和模型自適應(yīng)方法的提出。這時期劍橋發(fā)布的HTK開源工具包大幅度降低了語音識別研究的門檻。此后將近10年的時間里,語音識別的研究進展一直比較有限,基于GMM-HMM 框架的語音識別系統(tǒng)整體效果還遠遠達不到實用化水平,語音識別的研究和應(yīng)用陷入了瓶頸。
2006 年 Hinton]提出使用受限波爾茲曼機(restricted Boltzmann machine,RBM)對神經(jīng)網(wǎng)絡(luò)的節(jié)點做初始化,即深度置信網(wǎng)絡(luò)(deep belief network,DBN)。DBN解決了深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程中容易陷入局部最優(yōu)的問題,自此深度學(xué)習(xí)的大潮正式拉開。
2009 年,Hinton 和他的學(xué)生Mohamed D將 DBN 應(yīng)用在語音識別聲學(xué)建模中,并且在TIMIT這樣的小詞匯量連續(xù)語音識別數(shù)據(jù)庫上獲得成功。
2011 年 DNN 在大詞匯量連續(xù)語音識別上獲得成功,語音識別效果取得了近10年來最大的突破。從此,基于深度神經(jīng)網(wǎng)絡(luò)的建模方式正式取代GMM-HMM,成為主流的語音識別建模方式。
語音識別的基本原理
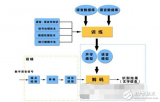
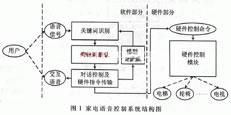
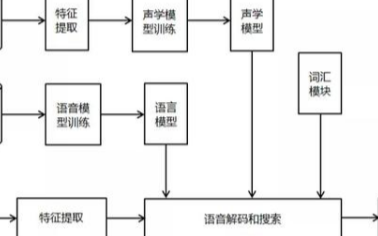
所謂語音識別,就是將一段語音信號轉(zhuǎn)換成相對應(yīng)的文本信息,系統(tǒng)主要包含特征提取、聲學(xué)模型,語言模型以及字典與解碼四大部分,其中為了更有效地提取特征往往還需要對所采集到的聲音信號進行濾波、分幀等預(yù)處理工作,把要分析的信號從原始信號中提取出來;之后,特征提取工作將聲音信號從時域轉(zhuǎn)換到頻域,為聲學(xué)模型提供合適的特征向量;聲學(xué)模型中再根據(jù)聲學(xué)特性計算每一個特征向量在聲學(xué)特征上的得分;而語言模型則根據(jù)語言學(xué)相關(guān)的理論,計算該聲音信號對應(yīng)可能詞組序列的概率;最后根據(jù)已有的字典,對詞組序列進行解碼,得到最后可能的文本表示。
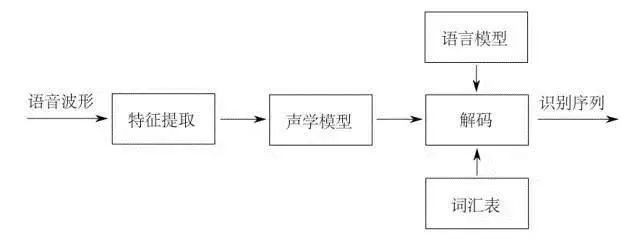
聲學(xué)信號預(yù)處理
作為語音識別的前提與基礎(chǔ),語音信號的預(yù)處理過程至關(guān)重要。在最終進行模板匹配的時候,是將輸入語音信號的特征參數(shù)同模板庫中的特征參數(shù)進行對比,因此,只有在預(yù)處理階段得到能夠表征語音信號本質(zhì)特征的特征參數(shù),才能夠?qū)⑦@些特征參數(shù)進行匹配進行識別率高的語音識別。
首先需要對聲音信號進行濾波與采樣,此過程主要是為了排除非人體發(fā)聲以外頻率的信號與50Hz電流頻率的干擾,該過程一般是用一個帶通濾波器、設(shè)定上下戒指頻率進行濾波,再將原有離散信號進行量化處理實現(xiàn)的;之后需要平滑信號的高頻與低頻部分的銜接段,從而可以在同一信噪比條件下對頻譜進行求解,使得分析更為方便快捷;分幀加窗操作是為了將原有頻域隨時間變化的信號具有短時平穩(wěn)特性,即將連續(xù)的信號用不同長度的采集窗口分成一個個獨立的頻域穩(wěn)定的部分以便于分析,此過程主要是采用預(yù)加重技術(shù);最后還需要進行端點檢測工作,也就是對輸入語音信號的起止點進行正確判斷,這主要是通過短時能量(同一幀內(nèi)信號變化的幅度)與短時平均過零率(同一幀內(nèi)采樣信號經(jīng)過零的次數(shù))來進行大致的判定。
聲學(xué)特征提取
完成信號的預(yù)處理之后,隨后進行的就是整個過程中極為關(guān)鍵的特征提取的操作。將原始波形進行識別并不能取得很好的識別效果,頻域變換后提取的特征參數(shù)用于識別,而能用于語音識別的特征參數(shù)必須滿足以下幾點:
1、特征參數(shù)能夠盡量描述語音的根本特征;
2、盡量降低參數(shù)分量之間的耦合,對數(shù)據(jù)進行壓縮;
3、應(yīng)使計算特征參數(shù)的過程更加簡便,使算法更加高效。基音周期、共振峰值等參數(shù)都可以作為表征語音特性的特征參數(shù)。
目前主流研究機構(gòu)最常用到的特征參數(shù)有:線性預(yù)測倒譜系數(shù)(LPCC)和 Mel 倒譜系數(shù)(MFCC)。兩種特征參數(shù)在倒譜域上對語音信號進行操作,前者以發(fā)聲模型作為出發(fā)點,利用 LPC 技術(shù)求倒譜系數(shù)。后者則模擬聽覺模型,把語音經(jīng)過濾波器組模型的輸出做為聲學(xué)特征,然后利用離散傅里葉變換(DFT)進行變換。
所謂基音周期,是指聲帶振動頻率(基頻)的振動周期,因其能夠有效表征語音信號特征,因此從最初的語音識別研究開始,基音周期檢測就是一個至關(guān)重要的研究點;所謂共振峰,是指語音信號中能量集中的區(qū)域,因其表征了聲道的物理特征,并且是發(fā)音音質(zhì)的主要決定條件,因此同樣是十分重要的特征參數(shù)。此外,目前也有許多研究者開始將深度學(xué)習(xí)中一些方法應(yīng)用在特征提取中,取得了較快的進展。
聲學(xué)模型
聲學(xué)模型是語音識別系統(tǒng)中非常重要的一個組件,對不同基本單元的區(qū)分能力直接關(guān)系到識別結(jié)果的好壞。語音識別本質(zhì)上一個模式識別的過程,而模式識別的核心是分類器和分類決策的問題。
通常,在孤立詞、中小詞匯量識別中使用動態(tài)時間規(guī)整(DTW)分類器會有良好的識別效果,并且識別速度快,系統(tǒng)開銷小,是語音識別中很成功的匹配算法。但是,在大詞匯量、非特定人語音識別的時候,DTW 識別效果就會急劇下降,這時候使用隱馬爾科夫模型(HMM)進行訓(xùn)練識別效果就會有明顯提升,由于在傳統(tǒng)語音識別中一般采用連續(xù)的高斯混合模型GMM來對狀態(tài)輸出密度函數(shù)進行刻畫,因此又稱為GMM-HMM構(gòu)架。
同時,隨著深度學(xué)習(xí)的發(fā)展,通過深度神經(jīng)網(wǎng)絡(luò)來完成聲學(xué)建模,形成所謂的DNN-HMM構(gòu)架來取代傳統(tǒng)的GMM-HMM構(gòu)架,在語音識別上也取得了很好的效果。
高斯混合模型
對于一個隨機向量 x,如果它的聯(lián)合概率密度函數(shù)符合公式2-9,則稱它服從高斯分布,并記為 x ~N(μ, Σ)。
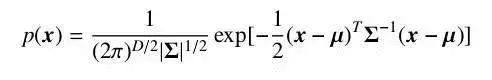
?
其中,μ 為分布的期望,Σ 為分布的協(xié)方差矩陣。高斯分布有很強的近似真實世界數(shù)據(jù)的能力,同時又易于計算,因此被廣泛地應(yīng)用在各個學(xué)科之中。但是,仍然有很多類型的數(shù)據(jù)不好被一個高斯分布所描述。這時候我們可以使用多個高斯分布的混合分布來描述這些數(shù)據(jù),由多個分量分別負責(zé)不同潛在的數(shù)據(jù)來源。此時,隨機變量符合密度函數(shù)。
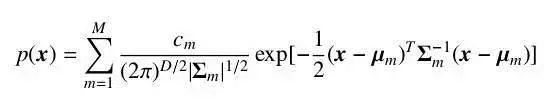
其中,M 為分量的個數(shù),通常由問題規(guī)模來確定。
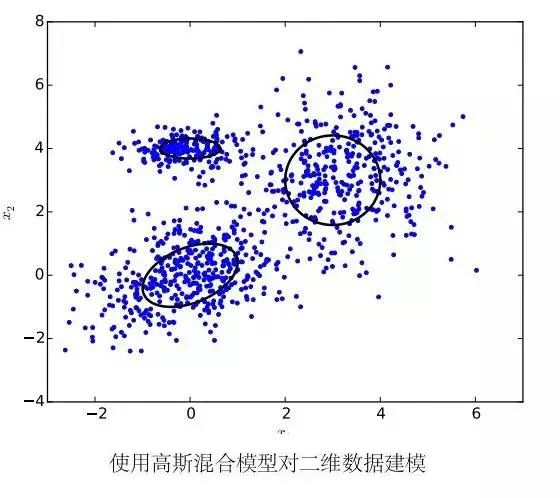
我們稱認為數(shù)據(jù)服從混合高斯分布所使用的模型為高斯混合模型。高斯混合模型被廣泛的應(yīng)用在很多語音識別系統(tǒng)的聲學(xué)模型中。考慮到在語音識別中向量的維數(shù)相對較大,所以我們通常會假設(shè)混合高斯分布中的協(xié)方差矩陣 Σm 為對角矩陣。這樣既大大減少了參數(shù)的數(shù)量,同時可以提高計算的效率。
使用高斯混合模型對短時特征向量建模有以下幾個好處:首先,高斯混合模型的具有很強的建模能力,只要分量總數(shù)足夠多,高斯混合模型就可以以任意精度來逼近一個概率分布函數(shù);另外,使用 EM 算法可以很容易地使模型在訓(xùn)練數(shù)據(jù)上收斂。對于計算速度和過擬合等問題,人們還研究出了參數(shù)綁定的 GMM 和子空間高斯混合模型 (subspace GMM) 來解決。除了使用 EM 算法作最大似然估計以外,我們還可以使用和詞或音素錯誤率直接相關(guān)的區(qū)分性的誤差函數(shù)來訓(xùn)練高斯混合模型,能夠極大地提高系統(tǒng)性能。因此,直到在聲學(xué)模型中使用深度神經(jīng)網(wǎng)絡(luò)的技術(shù)出現(xiàn)之前,高斯混合模型一直是短時特征向量建模的不二選擇。
但是,高斯混合模型同樣具有一個嚴重的缺點:高斯混合模型對于靠近向量空間上一個非線性流形 (manifold) 上的數(shù)據(jù)建模能力非常差。例如,假設(shè)一些數(shù)據(jù)分布在一個球面兩側(cè),且距離球面非常近。如果使用一個合適的分類模型,我們可能只需要很少的參數(shù)就可以將球面兩側(cè)的數(shù)據(jù)區(qū)分開。但是,如果使用高斯混合模型描繪他們的實際分布情況,我們需要非常多的高斯分布分量才能足夠精確地刻畫。這驅(qū)使我們尋找一個能夠更有效利用語音信息進行分類的模型。
隱馬爾科夫模型
我們現(xiàn)在考慮一個離散的隨機序列,若轉(zhuǎn)移概率符合馬爾可夫性質(zhì),即將來狀態(tài)和過去狀態(tài)獨立,則稱其為一條馬爾可夫鏈 (Markov Chain)。若轉(zhuǎn)移概率和時間無關(guān),則稱其為齊次 (homogeneous) 馬爾可夫鏈。馬爾可夫鏈的輸出和預(yù)先定義好的狀態(tài)一一對應(yīng),對于任意給定的狀態(tài),輸出是可觀測的,沒有隨機性。如果我們對輸出進行擴展,使馬爾可夫鏈的每個狀態(tài)輸出為一個概率分布函數(shù)。這樣的話馬爾可夫鏈的狀態(tài)不能被直接觀測到,只能通過受狀態(tài)變化影響的符合概率分布的其他變量來推測。我們稱以這種以隱馬爾可夫序列假設(shè)來建模數(shù)據(jù)的模型為隱馬爾可夫模型。
對應(yīng)到語音識別系統(tǒng)中,我們使用隱馬爾可夫模型來刻畫一個音素內(nèi)部子狀態(tài)變化,來解決特征序列到多個語音基本單元之間對應(yīng)關(guān)系的問題。
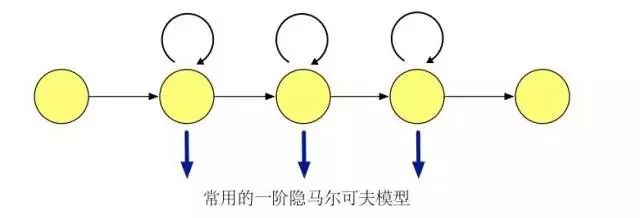
在語音識別任務(wù)中使用隱馬爾可夫模型需要計算模型在一段語音片段上的可能性。而在訓(xùn)練的時候,我們需要使用 Baum-Welch 算法[23] 學(xué)習(xí)隱馬爾可夫模型參數(shù),進行最大似然估計 (Maximum Likelihood Estimation, MLE)。Baum-Welch 算法是EM (Expectation-Maximization) 算法的一種特例,利用前后項概率信息迭代地依次進行計算條件期望的 E 步驟和最大化條件期望的 M 步驟。
語言模型
語言模型主要是刻畫人類語言表達的方式習(xí)慣,著重描述了詞與詞在排列結(jié)構(gòu)上的內(nèi)在聯(lián)系。在語音識別解碼的過程中,在詞內(nèi)轉(zhuǎn)移參考發(fā)聲詞典、詞間轉(zhuǎn)移參考語言模型,好的語言模型不僅能夠提高解碼效率,還能在一定程度上提高識別率。語言模型分為規(guī)則模型和統(tǒng)計模型兩類,統(tǒng)計語言模型用概率統(tǒng)計的方法來刻畫語言單位內(nèi)在的統(tǒng)計規(guī)律,其設(shè)計簡單實用而且取得了很好的效果,已經(jīng)被廣泛用于語音識別、機器翻譯、情感識別等領(lǐng)域。
最簡單又卻又最常用的語言模型是 N 元語言模型 (N-gram Language Model,N-gram LM) 。N 元語言模型假設(shè)當(dāng)前在給定上文環(huán)境下,當(dāng)前詞的概率只與前N-1 個詞相關(guān)。于是詞序列 w1, . . . , wm 的概率 P(w1, . . . , wm) 可以近似為
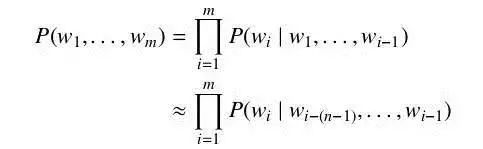
為了得到公式中的每一個詞在給定上文下的概率,我們需要一定數(shù)量的該語言文本來估算。可以直接使用包含上文的詞對在全部上文詞對中的比例來計算該概率,即
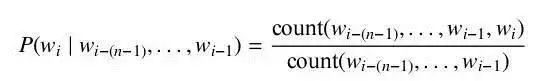
對于在文本中未出現(xiàn)的詞對,我們需要使用平滑方法來進行近似,如 Good-Turing估計或 Kneser-Ney 平滑等。
解碼與字典
解碼器是識別階段的核心組件,通過訓(xùn)練好的模型對語音進行解碼,獲得最可能的詞序列,或者根據(jù)識別中間結(jié)果生成識別網(wǎng)格 (lattice) 以供后續(xù)組件處理。解碼器部分的核心算法是動態(tài)規(guī)劃算法 Viterbi。由于解碼空間非常巨大,通常我們在實際應(yīng)用中會使用限定搜索寬度的令牌傳遞方法 (token passing)。
傳統(tǒng)解碼器會完全動態(tài)生成解碼圖 (decode graph),如著名語音識別工具HTK(HMM Tool Kit) 中的 HVite 和 HDecode 等。這樣的實現(xiàn)內(nèi)存占用較小,但考慮到各個組件的復(fù)雜性,整個系統(tǒng)的流程繁瑣,不方便高效地將語言模型和聲學(xué)模型結(jié)合起來,同時更加難以擴展。現(xiàn)在主流的解碼器實現(xiàn)會一定程度上使用預(yù)生成的有限狀態(tài)變換器 (Finite State Transducer, FST) 作為預(yù)加載的靜態(tài)解碼圖。這里我們可以將語言模型 (G),詞匯表(L),上下文相關(guān)信息 (C),隱馬爾可夫模型(H)四個部分分別構(gòu)建為標(biāo)準(zhǔn)的有限狀態(tài)變換器,再通過標(biāo)準(zhǔn)的有限狀態(tài)變換器操作將他們組合起來,構(gòu)建一個從上下文相關(guān)音素子狀態(tài)到詞的變換器。這樣的實現(xiàn)方法額外使用了一些內(nèi)存空間,但讓解碼器的指令序列變得更加整齊,使得一個高效的解碼器的構(gòu)建更加容易。同時,我們可以對預(yù)先構(gòu)建的有限狀態(tài)變換器進行預(yù)優(yōu)化,合并和剪掉不必要的部分,使得搜索空間變得更加合理
語音識別技術(shù)的工作原理
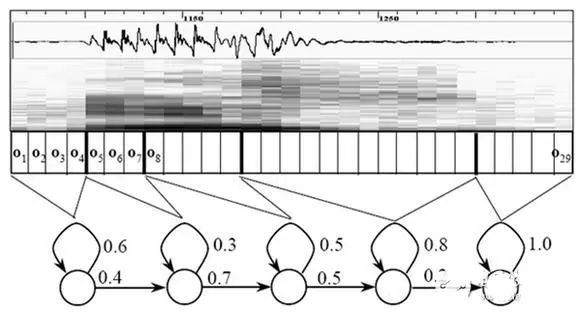
首先,我們知道聲音實際上是一種波。常見的mp3等格式都是壓縮格式,必須轉(zhuǎn)成非壓縮的純波形文件來處理,比如Windows PCM文件,也就是俗稱的wav文件。wav文件里存儲的除了一個文件頭以外,就是聲音波形的一個個點了。下圖是一個波形的示例。
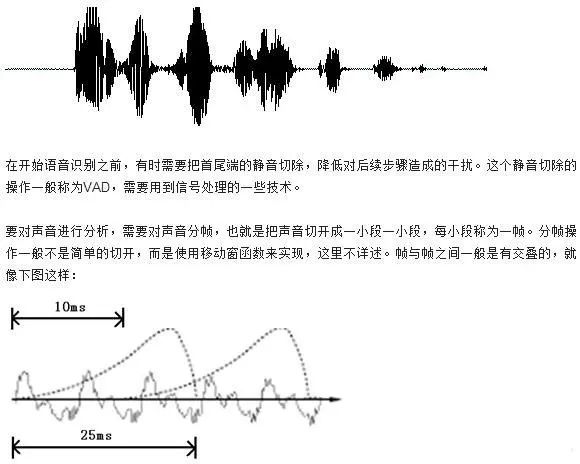
圖中,每幀的長度為25毫秒,每兩幀之間有25-10=15毫秒的交疊。我們稱為以幀長25ms、幀移10ms分幀。
分幀后,語音就變成了很多小段。但波形在時域上幾乎沒有描述能力,因此必須將波形作變換。常見的一種變換方法是提取MFCC特征,根據(jù)人耳的生理特性,把每一幀波形變成一個多維向量,可以簡單地理解為這個向量包含了這幀語音的內(nèi)容信息。這個過程叫做聲學(xué)特征提取。
至此,聲音就成了一個12行(假設(shè)聲學(xué)特征是12維)、N列的一個矩陣,稱之為觀察序列,這里N為總幀數(shù)。觀察序列如下圖所示,圖中,每一幀都用一個12維的向量表示,色塊的顏色深淺表示向量值的大小。
接下來就要介紹怎樣把這個矩陣變成文本了。首先要介紹兩個概念:
音素:單詞的發(fā)音由音素構(gòu)成。對英語,一種常用的音素集是卡內(nèi)基梅隆大學(xué)的一套由39個音素構(gòu)成的音素集。漢語一般直接用全部聲母和韻母作為音素集,另外漢語識別還分有調(diào)無調(diào),不詳述。
狀態(tài):這里理解成比音素更細致的語音單位就行啦。通常把一個音素劃分成3個狀態(tài)。
語音識別是怎么工作的呢?實際上一點都不神秘,無非是:
第一步,把幀識別成狀態(tài)。
第二步,把狀態(tài)組合成音素。
第三步,把音素組合成單詞。
如下圖所示:
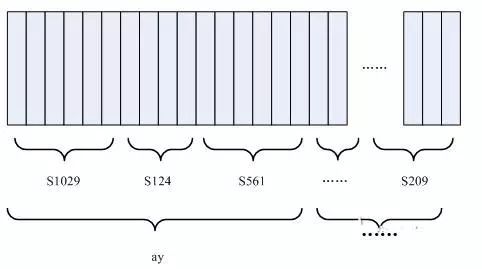
圖中,每個小豎條代表一幀,若干幀語音對應(yīng)一個狀態(tài),每三個狀態(tài)組合成一個音素,若干個音素組合成一個單詞。也就是說,只要知道每幀語音對應(yīng)哪個狀態(tài)了,語音識別的結(jié)果也就出來了。
那每幀音素對應(yīng)哪個狀態(tài)呢?有個容易想到的辦法,看某幀對應(yīng)哪個狀態(tài)的概率最大,那這幀就屬于哪個狀態(tài)。比如下面的示意圖,這幀在狀態(tài)S3上的條件概率最大,因此就猜這幀屬于狀態(tài)S3。
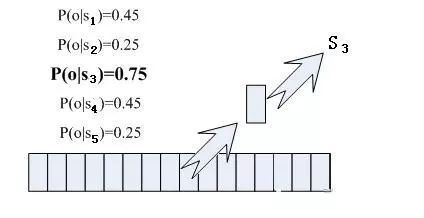
那這些用到的概率從哪里讀取呢?有個叫“聲學(xué)模型”的東西,里面存了一大堆參數(shù),通過這些參數(shù),就可以知道幀和狀態(tài)對應(yīng)的概率。獲取這一大堆參數(shù)的方法叫做“訓(xùn)練”,需要使用巨大數(shù)量的語音數(shù)據(jù)。
但這樣做有一個問題:每一幀都會得到一個狀態(tài)號,最后整個語音就會得到一堆亂七八糟的狀態(tài)號,相鄰兩幀間的狀態(tài)號基本都不相同。假設(shè)語音有1000幀,每幀對應(yīng)1個狀態(tài),每3個狀態(tài)組合成一個音素,那么大概會組合成300個音素,但這段語音其實根本沒有這么多音素。如果真這么做,得到的狀態(tài)號可能根本無法組合成音素。實際上,相鄰幀的狀態(tài)應(yīng)該大多數(shù)都是相同的才合理,因為每幀很短。
解決這個問題的常用方法就是使用隱馬爾可夫模型(Hidden Markov Model,HMM)。這東西聽起來好像很高深的樣子,實際上用起來很簡單:
第一步,構(gòu)建一個狀態(tài)網(wǎng)絡(luò)。
第二步,從狀態(tài)網(wǎng)絡(luò)中尋找與聲音最匹配的路徑。
這樣就把結(jié)果限制在預(yù)先設(shè)定的網(wǎng)絡(luò)中,避免了剛才說到的問題,當(dāng)然也帶來一個局限,比如你設(shè)定的網(wǎng)絡(luò)里只包含了“今天晴天”和“今天下雨”兩個句子的狀態(tài)路徑,那么不管說些什么,識別出的結(jié)果必然是這兩個句子中的一句。
那如果想識別任意文本呢?把這個網(wǎng)絡(luò)搭得足夠大,包含任意文本的路徑就可以了。但這個網(wǎng)絡(luò)越大,想要達到比較好的識別準(zhǔn)確率就越難。所以要根據(jù)實際任務(wù)的需求,合理選擇網(wǎng)絡(luò)大小和結(jié)構(gòu)。
搭建狀態(tài)網(wǎng)絡(luò),是由單詞級網(wǎng)絡(luò)展開成音素網(wǎng)絡(luò),再展開成狀態(tài)網(wǎng)絡(luò)。語音識別過程其實就是在狀態(tài)網(wǎng)絡(luò)中搜索一條最佳路徑,語音對應(yīng)這條路徑的概率最大,這稱之為“解碼”。路徑搜索的算法是一種動態(tài)規(guī)劃剪枝的算法,稱之為Viterbi算法,用于尋找全局最優(yōu)路徑。
這里所說的累積概率,由三部分構(gòu)成,分別是:
觀察概率:每幀和每個狀態(tài)對應(yīng)的概率
轉(zhuǎn)移概率:每個狀態(tài)轉(zhuǎn)移到自身或轉(zhuǎn)移到下個狀態(tài)的概率
語言概率:根據(jù)語言統(tǒng)計規(guī)律得到的概率
其中,前兩種概率從聲學(xué)模型中獲取,最后一種概率從語言模型中獲取。語言模型是使用大量的文本訓(xùn)練出來的,可以利用某門語言本身的統(tǒng)計規(guī)律來幫助提升識別正確率。語言模型很重要,如果不使用語言模型,當(dāng)狀態(tài)網(wǎng)絡(luò)較大時,識別出的結(jié)果基本是一團亂麻。
這樣基本上語音識別過程就完成了,這就是語音識別技術(shù)的工作原理。
語音識別技術(shù)的工作流程
一般來說,一套完整的語音識別系統(tǒng)其工作過程分為7步:
1、對語音信號進行分析和處理,除去冗余信息。
2、提取影響語音識別的關(guān)鍵信息和表達語言含義的特征信息。
3、緊扣特征信息,用最小單元識別字詞。
4、按照不同語言的各自語法,依照先后次序識別字詞。
5、把前后意思當(dāng)作輔助識別條件,有利于分析和識別。
6、按照語義分析,給關(guān)鍵信息劃分段落,取出所識別出的字詞并連接起來,同時根據(jù)語句意思調(diào)整句子構(gòu)成。
7、結(jié)合語義,仔細分析上下文的相互聯(lián)系,對當(dāng)前正在處理的語句進行適當(dāng)修正。
語音識別原理有三點:
1、對語音信號中的語言信息編碼是按照幅度譜的時間變化來進行;
2、由于語音是可以閱讀的,也就是說聲學(xué)信號可以在不考慮說話人說話傳達的信息內(nèi)容的前提下用多個具有區(qū)別性的、離散的符號來表示;
3、語音的交互是一個認知過程,所以絕對不能與語法、語義和用語規(guī)范等方面分裂開來。
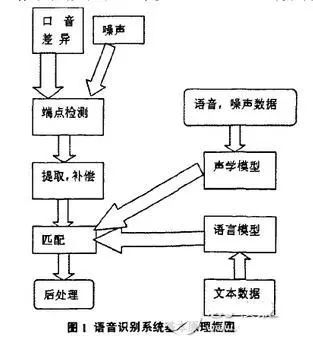
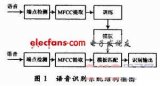
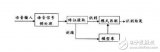
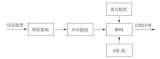
預(yù)處理,其中就包括對語音信號進行采樣、克服混疊濾波、去除部分由個體發(fā)音的差異和環(huán)境引起的噪聲影響,此外還會考慮到語音識別基本單元的選取和端點檢測問題。反復(fù)訓(xùn)練是在識別之前通過讓說話人多次重復(fù)語音,從原始語音信號樣本中去除冗余信息,保留關(guān)鍵信息,再按照一定規(guī)則對數(shù)據(jù)加以整理,構(gòu)成模式庫。再者是模式匹配,它是整個語音識別系統(tǒng)的核心部分,是根據(jù)一定規(guī)則以及計算輸入特征與庫存模式之間的相似度,進而判斷出輸入語音的意思。
前端處理,先對原始語音信號進行處理,再進行特征提取,消除噪聲和不同說話人的發(fā)音差異帶來的影響,使處理后的信號能夠更完整地反映語音的本質(zhì)特征提取,消除噪聲和不同說話人的發(fā)音差異帶來的影響,使處理后的信號能夠更完整地反映語音的本質(zhì)特征。
審核編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論