 電子發(fā)燒友App
電子發(fā)燒友App


掌上多媒體設(shè)備的增長(zhǎng)極大地改變了終端多媒體芯片供應(yīng)商對(duì)產(chǎn)品的定位需求。這些芯片提供商的IC設(shè)計(jì)目標(biāo)不再僅僅針對(duì)一兩種多媒體編解碼器。消費(fèi)者希望他們的移動(dòng)設(shè)備能夠利用不同的設(shè)備來(lái)播放媒體,能夠采用不同的標(biāo)準(zhǔn)進(jìn)行編碼,并能夠從不同的設(shè)備來(lái)下載或者接收媒體數(shù)據(jù)。視頻譯碼器和編碼器引擎必須滿足多種需求,并具有面積和功耗優(yōu)勢(shì)。
1、設(shè)計(jì)視頻加速引擎的傳統(tǒng)RTL方法
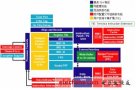
上一代視頻ASIC的設(shè)計(jì)主要對(duì)MPEG-2進(jìn)行編碼和譯碼,因?yàn)檫@是DVD標(biāo)準(zhǔn)。有些視頻ASIC還支持MPEG-1,用于VCD(視頻CD)播放。在多數(shù)情況下,MPEG-2編碼器和譯碼器都采用RTL設(shè)計(jì)方法。一個(gè)典型MPEG-2視頻ASIC體系結(jié)構(gòu)如圖1所示,其中包括由各個(gè)RTL模塊構(gòu)成的視頻子系統(tǒng)、主控制器和片上存儲(chǔ)器。

圖1 MPEG-2視頻ASIC體系結(jié)構(gòu)
采用硬線RTL體系結(jié)構(gòu)支持多種視頻標(biāo)準(zhǔn),然而,這也意味著每個(gè)視頻標(biāo)準(zhǔn)都需要一個(gè)專(zhuān)用的RTL模塊來(lái)實(shí)現(xiàn)。采用硬線RTL模塊實(shí)現(xiàn)一個(gè)多種標(biāo)準(zhǔn)的視頻加速引擎具有一定的局限性。無(wú)論是實(shí)現(xiàn)一個(gè)新的視頻標(biāo)準(zhǔn)、更新已有的標(biāo)準(zhǔn)還是消除其中的故障都需要重新進(jìn)行芯片加工。
2、采用處理器作為視頻加速引擎的優(yōu)勢(shì)
可編程處理器能夠滿足多種視頻標(biāo)準(zhǔn)的靈活性要求。與RTL模塊設(shè)計(jì)方法相比,可編程處理器具有如下幾個(gè)優(yōu)勢(shì):一是易于將編解碼器與處理器接口;二是滿足新的視頻標(biāo)準(zhǔn)要求、更新現(xiàn)有編解碼器或者采用軟件方法在芯片投片后也可以修改故障;三是可以采用軟件更新的方法很容易地提高視頻編解碼器的性能。
然而,傳統(tǒng)的32位處理器存在性能瓶頸,因?yàn)樗鼈兪敲嫦蛲ㄓ么a設(shè)計(jì)的,而不是面向視頻加速引擎設(shè)計(jì)的。嵌入式DSP也并非專(zhuān)門(mén)為視頻量身定做的,而是包括硬件功能部件、指令和接口,專(zhuān)門(mén)應(yīng)用于通用DSP領(lǐng)域。因此,為了在傳統(tǒng)RISC和DSP處理器上實(shí)現(xiàn)視頻編解碼器,就必須使這些處理器運(yùn)行在很高的速度(Mhz)上,需要大量的存儲(chǔ)器空間,因此需要很大的功耗,不適合便攜式應(yīng)用。
通過(guò)研究一個(gè)視頻內(nèi)核程序所需要的計(jì)算量,即可一目了然。比如,一個(gè)絕對(duì)差值累加運(yùn)算SAD,該運(yùn)算是大部分視頻編碼算法中運(yùn)動(dòng)估計(jì)一步常采用的方法。SAD算法將會(huì)在相鄰兩個(gè)連續(xù)視頻幀中找出宏塊的運(yùn)動(dòng)情況,為此,需要計(jì)算兩個(gè)宏塊中每一組對(duì)應(yīng)的像素值之間絕對(duì)差值的累加和。
下面C代碼給出了SAD核心算法的簡(jiǎn)單實(shí)現(xiàn):
for (row = 0; row < numrows; row++) {
for (col = 0; col < numcols; col++) {
accum += abs(macroblk1[row][col] - macroblk2[row][col]);
} /* column loop */
} /* row loop */
SAD核心算法的基本計(jì)算方法如圖2所示。正像圖中所示的那樣,SAD核心算法首先執(zhí)行減法操作,然后取絕對(duì)值,最后對(duì)前面的結(jié)果進(jìn)行累加。
圖2 差值絕對(duì)值累加(SAD)主要計(jì)算方法
在一個(gè)RISC處理器上計(jì)算一個(gè)由兩個(gè)16x16宏塊組成的SAD運(yùn)算需要256次減法運(yùn)算、256次絕對(duì)值運(yùn)算和256次累加運(yùn)算,共需要768次算術(shù)運(yùn)算,這還不包括因數(shù)據(jù)轉(zhuǎn)移需要的取數(shù)和存數(shù)操作。由于這需要對(duì)每一幀的所有宏塊進(jìn)行操作,因此,隨著分辨率的提高引起視頻幀增加,使得計(jì)算成本極度昂貴。
事實(shí)上,對(duì)于一個(gè)一般的通用RISC處理器而言(包括一些DSP指令,如乘法指令和乘累加指令),執(zhí)行一個(gè)H.264基準(zhǔn)譯碼算法需要250 MHz的性能(CIF分辨率),而執(zhí)行一個(gè)H.264基準(zhǔn)編碼算法則需要超過(guò)1 GHz的性能(CIF分辨率)。完成上述運(yùn)算,僅處理器內(nèi)核就需要500mW的功耗,更不要說(shuō)由訪存和視頻SOC的其它部件所用的功耗。
3、可配置處理器方法
在一個(gè)處理器上實(shí)現(xiàn)SAD核心算法的一個(gè)更加有效的途徑是建立 “減法-絕對(duì)值-加法”專(zhuān)用指令。這將大大降低算術(shù)運(yùn)算的開(kāi)銷(xiāo),對(duì)一個(gè)16x16宏塊而言,運(yùn)算次數(shù)將從768次降為256次。而且,由于采用一個(gè)功能部件就可以實(shí)現(xiàn)多個(gè)簡(jiǎn)單算術(shù)運(yùn)算的融合操作,因此上面的運(yùn)算只需一個(gè)指令周期就可以完成,這相當(dāng)于原來(lái)的256個(gè)周期。 用戶不能往一個(gè)標(biāo)準(zhǔn)的32位RISC處理器中添加指令,但是,完全可以往一個(gè)可配置處理器中添加專(zhuān)用指令。可配置處理器允許設(shè)計(jì)人員從可配置選項(xiàng)菜單中選擇相關(guān)配置命令來(lái)擴(kuò)展處理器功能,包括增加專(zhuān)用指令、寄存器文件和接口等。
下面是現(xiàn)代可配置處理器(例如Tensilica公司的 Xtensa處理器)提供的配置和擴(kuò)展選項(xiàng),這對(duì)于傳統(tǒng)的固定模式處理器而言是做不到的。
(i) 配置選項(xiàng):選項(xiàng)菜單包括下面幾項(xiàng):
a. 設(shè)計(jì)人員需要或者不需要的指令。例如,16x16的乘法或者乘累加、移位、浮點(diǎn)指令等等。
b. 零開(kāi)銷(xiāo)循環(huán)、五級(jí)或者七級(jí)流水線、局部數(shù)據(jù)加載或者存儲(chǔ)部件個(gè)數(shù)等。
c. 是否需要存儲(chǔ)器保護(hù)、存儲(chǔ)器地址轉(zhuǎn)換或者存儲(chǔ)器管理部件(MMU)
d. 包含或者不包含系統(tǒng)總線接口
e. 系統(tǒng)總線寬度和局部存儲(chǔ)器接口寬度
f. 局部(緊密耦合)存儲(chǔ)器大小和數(shù)量。
g. 中斷數(shù)量及中斷類(lèi)型和中斷優(yōu)先級(jí)。
(ii) 擴(kuò)展選項(xiàng):增加設(shè)計(jì)人員自己定義的功能部件,包括:
a. 寄存器和寄存器文件。
b. 多周期、仲裁復(fù)雜指令功能部件。
c. 單指令流多數(shù)據(jù)流SIMD功能部件。
d. 將單發(fā)射處理器變?yōu)槎喟l(fā)射處理器。
e. 用戶定制接口,可以直接對(duì)數(shù)據(jù)通路進(jìn)行讀寫(xiě)操作,例如,類(lèi)似GPIO(通用輸入/輸出)引腳的處理器內(nèi)核端口或者引腳,用于擴(kuò)展先進(jìn)先出FIFO隊(duì)列的隊(duì)列接口(可以與其它邏輯或者處理器內(nèi)核進(jìn)行接口)。
配置選項(xiàng)的好處是讓設(shè)計(jì)人員通過(guò)僅選擇與其應(yīng)用有關(guān)的選項(xiàng),就可以構(gòu)建一個(gè)規(guī)模適度的處理器,并能夠滿足其特定應(yīng)用。擴(kuò)展選項(xiàng)的好處是讓設(shè)計(jì)人員根據(jù)應(yīng)用定制處理器,包括建立專(zhuān)用指令、寄存器文件、功能部件和相關(guān)接口,用于加速系統(tǒng)應(yīng)用算法的執(zhí)行。
4、自動(dòng)化軟件開(kāi)發(fā)工具套件支持
可配置和可擴(kuò)展的關(guān)鍵是不僅能夠自動(dòng)產(chǎn)生預(yù)先經(jīng)過(guò)驗(yàn)證的RTL代碼,用于設(shè)計(jì)人員定制處理器(包括所有系統(tǒng)擴(kuò)展功能),而且還能夠自動(dòng)產(chǎn)生完整的軟件工具,包括一個(gè)與處理器相匹配并經(jīng)過(guò)優(yōu)化的開(kāi)發(fā)工具套件、一個(gè)基于時(shí)鐘周期的指令集仿真器以及系統(tǒng)模型。
這種自動(dòng)化意味著編譯器知道設(shè)計(jì)人員所添加的新指令、相關(guān)的寄存器以及寄存器文件。因此,編譯器能夠?qū)τ脩舳x的指令進(jìn)行調(diào)度,并執(zhí)行寄存器分配操作。類(lèi)似地,軟件開(kāi)發(fā)人員在調(diào)試時(shí)除了處理器本身的基本寄存器,還能夠了解設(shè)計(jì)人員定義的寄存器和寄存器文件;同時(shí),軟件開(kāi)發(fā)人員能夠利用指令集仿真器對(duì)設(shè)計(jì)人員定義的新指令進(jìn)行仿真。與處理器相關(guān)的實(shí)時(shí)操作系統(tǒng)RTOS端口和系統(tǒng)模型也能夠自動(dòng)產(chǎn)生。Tensilica的軟件工具能夠在一個(gè)小時(shí)內(nèi)自動(dòng)產(chǎn)生上述軟件工具,這是對(duì)使用可配置處理器用戶的核心承諾,能夠執(zhí)行諸如SAD運(yùn)算,而不必采用RTL那樣的實(shí)現(xiàn)方法。
5、采用可配置處理器構(gòu)建視頻加速引擎建立多操作功能部件
將SAD這樣的融合操作加到一個(gè)可配置處理器中是一件麻煩的事情。一條稱(chēng)為“sub.abs.ac”的新指令可以完成“減法-絕對(duì)值-累加”運(yùn)算操作。這條新指令能夠?qū)D2中的操作變成圖3中的復(fù)操作。
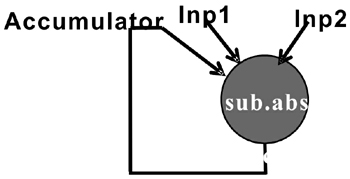
圖3 使用新指令計(jì)算“減法-絕對(duì)值-累加”操作
將該指令添加到處理器中后,C編譯器能夠識(shí)別這條新的“sub.abs.ac”指令,并調(diào)度相關(guān)指令;調(diào)度器將顯示“sub.abs.ac”功能部件所使用的內(nèi)部信號(hào);匯編器能夠處理這條新指令;指令集仿真器ISS能夠按照時(shí)鐘周期模式進(jìn)行仿真。
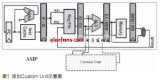
新的專(zhuān)用視頻功能部件插入處理器后的數(shù)據(jù)通路簡(jiǎn)圖如圖4所示。注意到,除了產(chǎn)生功能部件邏輯外,硬件生成工具還能夠自動(dòng)插入前饋通路、控制邏輯以及旁路邏輯,以便將新的功能部件與數(shù)據(jù)通路中的其它邏輯互連。
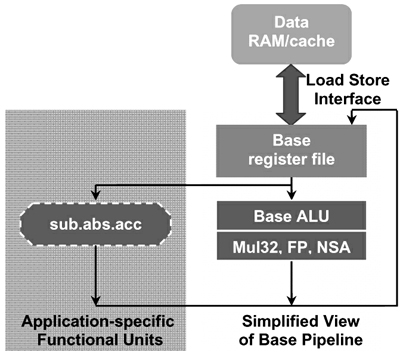
圖4 插入sub.abs.ac視頻專(zhuān)用功能部件后的簡(jiǎn)化數(shù)據(jù)通路示意圖
包含新指令的C代碼描述的SAD算法如下:
for (row = 0; row < numrows; row++) {??for (col = 0; col < numcols; col++) {
sub.abs.ac( accum, macroblk1[row][col], macroblk2[row][col]);
} /* column loop */
} /* row loop */
正如前面提到的,對(duì)于一個(gè)16x16宏塊而言,增加新指令后程序主循環(huán)中的操作數(shù)減少到256個(gè)(即numrows = numcols = 16)。
6、建立單指令流多數(shù)據(jù)流SIMD功能部件
前面的SAD程序還可以進(jìn)一步優(yōu)化。程序中的內(nèi)循環(huán)將宏塊中16列做相同的運(yùn)算。這對(duì)于SIMD(單指令多數(shù)據(jù))功能部件而言是理想選擇,相應(yīng)的指令“sub.abs.ac16”針對(duì)16個(gè)像素同時(shí)完成sub.abs.ac操作,如圖5所示。

圖5 對(duì)16個(gè)像素同時(shí)進(jìn)行sub.abs.ac指令的單指令流多數(shù)據(jù)流計(jì)算操作
相應(yīng)的C語(yǔ)言過(guò)程名為sub.abs.ac16,利用此過(guò)程名重新改寫(xiě)的SAD內(nèi)核C程序代碼如下:
for (row = 0; row < numrows; row++) {
sub.abs.ac16( accum, macroblk1[row], macroblk2[row]);
} /* row loop */
通過(guò)改寫(xiě)后的SAD內(nèi)核程序從768個(gè)算術(shù)操作減少為僅16個(gè)算術(shù)操作。
然而,僅僅只有上述C程序代碼是不夠的。因?yàn)橹噶顂ub.abs.ac16需要從兩個(gè)宏塊中讀取128位的數(shù)據(jù),這需要兩個(gè)方面的支持:一個(gè)128位的寄存器文件和一個(gè)寬數(shù)據(jù)位的取數(shù)/存數(shù)接口,可配置處理器均支持這些功能。
7、建立用戶定制的寄存器文件
在Xtensa可配置處理器中,說(shuō)明一個(gè)任意寬度的定制寄存器文件就像寫(xiě)一行程序那么簡(jiǎn)單。例如,稱(chēng)為“myRegFile128”的過(guò)程語(yǔ)句建立一個(gè)寬度為128位的寄存器文件,長(zhǎng)度為4,并建立一個(gè)相應(yīng)的新的C數(shù)據(jù)類(lèi)型,“myRegFile128”能夠用于C/C++程序代碼說(shuō)明變量。軟件工具也建立“MOVE”操作,用于將各種C數(shù)據(jù)類(lèi)型轉(zhuǎn)換為新的定制數(shù)據(jù)類(lèi)型。因此,采用sub.abs.ac16過(guò)程和新寄存器文件后的SAD內(nèi)核C程序代碼如下:
for (row = 0; row < numrows; row++) {
myRegFile128 mblk1, mblk2;
mblk1 = macroblk1[row];
mblk2 = macroblk2[row];
sub.abs.ac16( accum, mblk1, mblk2);
} /* row loop */
現(xiàn)在C/C++編譯器將會(huì)產(chǎn)生一條MOVE指令,將數(shù)據(jù)從一般的C數(shù)據(jù)類(lèi)型移到定制的C數(shù)據(jù)類(lèi)型“myRegFile128”,并為新寄存器文件分配寄存器。
8、建立高數(shù)據(jù)帶寬的加載/存儲(chǔ)接口
為了對(duì)高帶寬定制寄存器文件(以及相應(yīng)的單指令流多數(shù)據(jù)流SIMD功能部件)進(jìn)行數(shù)據(jù)存取,處理器應(yīng)當(dāng)具有高帶寬數(shù)據(jù)加載/存儲(chǔ)操作能力。對(duì)可配置處理器而言,設(shè)計(jì)人員能夠說(shuō)明定制加載和存儲(chǔ)操作指令,直接完成對(duì)定制寄存器文件的高帶寬加載/存儲(chǔ)數(shù)據(jù)操作。然后,編譯器自動(dòng)產(chǎn)生與高帶寬加載/存儲(chǔ)接口相應(yīng)的加載/存儲(chǔ)指令。
經(jīng)過(guò)更新后的處理器數(shù)據(jù)通路如圖6所示。硬件生成工具產(chǎn)生高帶寬的定制寄存器文件、與數(shù)據(jù)存儲(chǔ)器相關(guān)的加載/存儲(chǔ)接口以及相應(yīng)的前饋邏輯、控制邏輯和旁通邏輯。硬件工具還產(chǎn)生相應(yīng)的硬件邏輯,用于將數(shù)據(jù)從基準(zhǔn)寄存器文件移到用戶定義的寄存器文件中。
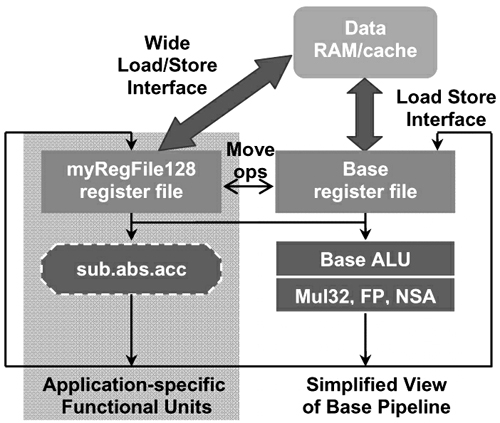
圖6 插入寄存器文件和高帶寬加載/存儲(chǔ)接口的數(shù)據(jù)通路
9、更新地址的同時(shí)進(jìn)行加載
或者存儲(chǔ)操作
Xtensa可配置處理器允許用戶建立另一個(gè)非常有用的功能擴(kuò)展,即建立一條指令,能夠同時(shí)完成地址更新操作和數(shù)據(jù)加載/存儲(chǔ)操作。建立的新的加載/存儲(chǔ)操作指令能夠并發(fā)完成如下功能: Load A1 ← Memory(Addr1);Addr1 = Addr1 + IndexUpdate
該指令能夠完成“背靠背”的加載/存儲(chǔ)操作,而不需要專(zhuān)門(mén)指令對(duì)地址進(jìn)行更新。
10、建立先進(jìn)先出(FIFO)接口
和通用輸入/輸出端口
視頻和音頻均為流媒體,需要對(duì)處理器進(jìn)行快速數(shù)據(jù)訪問(wèn)。傳統(tǒng)的處理器受限于系統(tǒng)總線接口,以及數(shù)據(jù)操作執(zhí)行前對(duì)所以數(shù)據(jù)的加載與存儲(chǔ)訪問(wèn)。
為支持流媒體數(shù)據(jù)/輸出操作,Xtensa可配置處理器允許設(shè)計(jì)人員定義先進(jìn)先出(FIFO)接口以及通用輸入/輸出(GPIO)端口,以便直接對(duì)數(shù)據(jù)通路進(jìn)行讀寫(xiě)訪問(wèn)。FIFO和GPIO端口可以是任意數(shù)據(jù)寬度(可達(dá)1024位),數(shù)量不限(每個(gè)可包含1024個(gè)FIFO和GPIO端口)。這些高帶寬接口可以直接與數(shù)據(jù)通路相連,提供很高的數(shù)據(jù)吞吐量,通過(guò)處理器內(nèi)核對(duì)數(shù)據(jù)進(jìn)行讀、處理和寫(xiě)操作,這對(duì)于多媒體和網(wǎng)絡(luò)應(yīng)用而言是非常重要的。
具有FIFO接口和GPIO端口的數(shù)據(jù)通路如圖7所示。處理器可以進(jìn)行如下操作:首先從兩個(gè)FIFO(在確保兩個(gè)先進(jìn)先出隊(duì)列均不空的情況下)中取出數(shù)據(jù),然后計(jì)算一個(gè)復(fù)操作(例如一個(gè)乘累加舍入操作),最后將計(jì)算結(jié)果壓入輸出FIFO(在確保先進(jìn)先出隊(duì)列不滿的情況下)。然后,硬件生成工具產(chǎn)生相應(yīng)的接口信號(hào)、控制邏輯和旁通邏輯等;為配置的處理器產(chǎn)生完整的RTL代碼。軟件生成工具產(chǎn)生一套完整的編譯器工具,以及時(shí)鐘周期精確的指令集仿真器ISS,用于對(duì)新指令進(jìn)行仿真。注意到,這種由設(shè)計(jì)人員定義FIFO接口和GPIO端口的能力是Xtensa可配置處理器所獨(dú)有的。
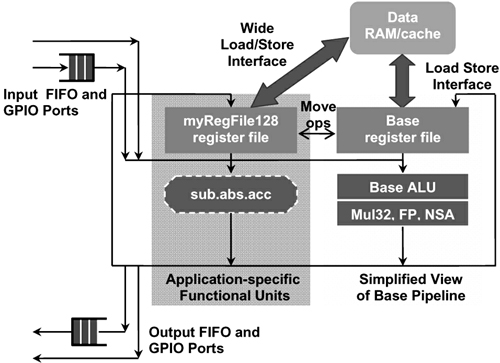
圖7 采用定制先進(jìn)先出(FIFO)接口和通用輸入輸出(IO)端口的高速通信
11、加速?gòu)?fù)雜的控制密集型代碼的執(zhí)行
多媒體應(yīng)用中控制代碼的數(shù)量與復(fù)雜性顯著增長(zhǎng),使得程序中數(shù)據(jù)密集型操作與計(jì)算時(shí)間近似等價(jià)。例如,H.264主程序譯碼器中的關(guān)鍵部分為CABAC(上下文相關(guān)二進(jìn)制算術(shù)編碼)算法。該算法幾乎完全是具有數(shù)據(jù)計(jì)算和數(shù)據(jù)比較的控制流判決樹(shù)。
由于計(jì)算的復(fù)雜性非常高,絕大多數(shù)傳統(tǒng)處理器均采用專(zhuān)用的RTL加速器來(lái)完成CABAC算法。然而,在可配置處理器上可以通過(guò)增加一組專(zhuān)用指令來(lái)更加有效地實(shí)現(xiàn)CABAC算法。這種實(shí)現(xiàn)方法的好處是避免了數(shù)據(jù)在處理器和RTL加速器之間不停地交換數(shù)據(jù)。采用可配置處理器的另一個(gè)好處是采用指令擴(kuò)展技術(shù),由于專(zhuān)用硬件在處理器內(nèi)部,因此可以更好地進(jìn)行硬件和軟件界面劃分。
12、小結(jié)
現(xiàn)代可配置和可擴(kuò)展處理器是構(gòu)建定制視頻和音頻引擎的理想選擇。Tensilica公司提供相關(guān)的視頻和音頻IP作為SOC模塊,包括HiFi 2音頻引擎、鉆石系列標(biāo)準(zhǔn)的38xVDO(視頻)多標(biāo)準(zhǔn)和多分辨率視頻方法。與之匹配的軟件編解碼器是非常重要的。HiFi 2音頻引擎與相關(guān)的軟件一起可完成絕大部分流行的音頻編解碼器,例如MP3、AAC、WMA等。類(lèi)似地,鉆石 38xVDO 視頻加速引擎與相應(yīng)的編碼器和譯碼器軟件可以實(shí)現(xiàn)H.264 (包括Baseline、Main和profiles)、MPEG-4 (SP 和 ASP)、 MPEG-2、VC-1/WM9及其它標(biāo)準(zhǔn)。這些視頻技術(shù)涵蓋了從QCIF 到CIF以及SD各種分辨率,功耗低,面積小。
1、設(shè)計(jì)視頻加速引擎的傳統(tǒng)RTL方法
上一代視頻ASIC的設(shè)計(jì)主要對(duì)MPEG-2進(jìn)行編碼和譯碼,因?yàn)檫@是DVD標(biāo)準(zhǔn)。有些視頻ASIC還支持MPEG-1,用于VCD(視頻CD)播放。在多數(shù)情況下,MPEG-2編碼器和譯碼器都采用RTL設(shè)計(jì)方法。一個(gè)典型MPEG-2視頻ASIC體系結(jié)構(gòu)如圖1所示,其中包括由各個(gè)RTL模塊構(gòu)成的視頻子系統(tǒng)、主控制器和片上存儲(chǔ)器。
圖1 MPEG-2視頻ASIC體系結(jié)構(gòu)
采用硬線RTL體系結(jié)構(gòu)支持多種視頻標(biāo)準(zhǔn),然而,這也意味著每個(gè)視頻標(biāo)準(zhǔn)都需要一個(gè)專(zhuān)用的RTL模塊來(lái)實(shí)現(xiàn)。采用硬線RTL模塊實(shí)現(xiàn)一個(gè)多種標(biāo)準(zhǔn)的視頻加速引擎具有一定的局限性。無(wú)論是實(shí)現(xiàn)一個(gè)新的視頻標(biāo)準(zhǔn)、更新已有的標(biāo)準(zhǔn)還是消除其中的故障都需要重新進(jìn)行芯片加工。
2、采用處理器作為視頻加速引擎的優(yōu)勢(shì)
可編程處理器能夠滿足多種視頻標(biāo)準(zhǔn)的靈活性要求。與RTL模塊設(shè)計(jì)方法相比,可編程處理器具有如下幾個(gè)優(yōu)勢(shì):一是易于將編解碼器與處理器接口;二是滿足新的視頻標(biāo)準(zhǔn)要求、更新現(xiàn)有編解碼器或者采用軟件方法在芯片投片后也可以修改故障;三是可以采用軟件更新的方法很容易地提高視頻編解碼器的性能。
然而,傳統(tǒng)的32位處理器存在性能瓶頸,因?yàn)樗鼈兪敲嫦蛲ㄓ么a設(shè)計(jì)的,而不是面向視頻加速引擎設(shè)計(jì)的。嵌入式DSP也并非專(zhuān)門(mén)為視頻量身定做的,而是包括硬件功能部件、指令和接口,專(zhuān)門(mén)應(yīng)用于通用DSP領(lǐng)域。因此,為了在傳統(tǒng)RISC和DSP處理器上實(shí)現(xiàn)視頻編解碼器,就必須使這些處理器運(yùn)行在很高的速度(Mhz)上,需要大量的存儲(chǔ)器空間,因此需要很大的功耗,不適合便攜式應(yīng)用。
通過(guò)研究一個(gè)視頻內(nèi)核程序所需要的計(jì)算量,即可一目了然。比如,一個(gè)絕對(duì)差值累加運(yùn)算SAD,該運(yùn)算是大部分視頻編碼算法中運(yùn)動(dòng)估計(jì)一步常采用的方法。SAD算法將會(huì)在相鄰兩個(gè)連續(xù)視頻幀中找出宏塊的運(yùn)動(dòng)情況,為此,需要計(jì)算兩個(gè)宏塊中每一組對(duì)應(yīng)的像素值之間絕對(duì)差值的累加和。
下面C代碼給出了SAD核心算法的簡(jiǎn)單實(shí)現(xiàn):
for (row = 0; row < numrows; row++) {
for (col = 0; col < numcols; col++) {
accum += abs(macroblk1[row][col] - macroblk2[row][col]);
} /* column loop */
} /* row loop */
SAD核心算法的基本計(jì)算方法如圖2所示。正像圖中所示的那樣,SAD核心算法首先執(zhí)行減法操作,然后取絕對(duì)值,最后對(duì)前面的結(jié)果進(jìn)行累加。
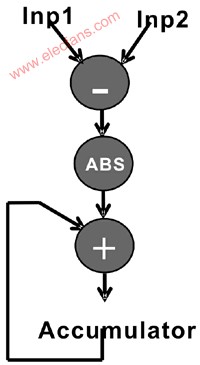
圖2 差值絕對(duì)值累加(SAD)主要計(jì)算方法
在一個(gè)RISC處理器上計(jì)算一個(gè)由兩個(gè)16x16宏塊組成的SAD運(yùn)算需要256次減法運(yùn)算、256次絕對(duì)值運(yùn)算和256次累加運(yùn)算,共需要768次算術(shù)運(yùn)算,這還不包括因數(shù)據(jù)轉(zhuǎn)移需要的取數(shù)和存數(shù)操作。由于這需要對(duì)每一幀的所有宏塊進(jìn)行操作,因此,隨著分辨率的提高引起視頻幀增加,使得計(jì)算成本極度昂貴。
事實(shí)上,對(duì)于一個(gè)一般的通用RISC處理器而言(包括一些DSP指令,如乘法指令和乘累加指令),執(zhí)行一個(gè)H.264基準(zhǔn)譯碼算法需要250 MHz的性能(CIF分辨率),而執(zhí)行一個(gè)H.264基準(zhǔn)編碼算法則需要超過(guò)1 GHz的性能(CIF分辨率)。完成上述運(yùn)算,僅處理器內(nèi)核就需要500mW的功耗,更不要說(shuō)由訪存和視頻SOC的其它部件所用的功耗。
3、可配置處理器方法
在一個(gè)處理器上實(shí)現(xiàn)SAD核心算法的一個(gè)更加有效的途徑是建立 “減法-絕對(duì)值-加法”專(zhuān)用指令。這將大大降低算術(shù)運(yùn)算的開(kāi)銷(xiāo),對(duì)一個(gè)16x16宏塊而言,運(yùn)算次數(shù)將從768次降為256次。而且,由于采用一個(gè)功能部件就可以實(shí)現(xiàn)多個(gè)簡(jiǎn)單算術(shù)運(yùn)算的融合操作,因此上面的運(yùn)算只需一個(gè)指令周期就可以完成,這相當(dāng)于原來(lái)的256個(gè)周期。 用戶不能往一個(gè)標(biāo)準(zhǔn)的32位RISC處理器中添加指令,但是,完全可以往一個(gè)可配置處理器中添加專(zhuān)用指令。可配置處理器允許設(shè)計(jì)人員從可配置選項(xiàng)菜單中選擇相關(guān)配置命令來(lái)擴(kuò)展處理器功能,包括增加專(zhuān)用指令、寄存器文件和接口等。
下面是現(xiàn)代可配置處理器(例如Tensilica公司的 Xtensa處理器)提供的配置和擴(kuò)展選項(xiàng),這對(duì)于傳統(tǒng)的固定模式處理器而言是做不到的。
(i) 配置選項(xiàng):選項(xiàng)菜單包括下面幾項(xiàng):
a. 設(shè)計(jì)人員需要或者不需要的指令。例如,16x16的乘法或者乘累加、移位、浮點(diǎn)指令等等。
b. 零開(kāi)銷(xiāo)循環(huán)、五級(jí)或者七級(jí)流水線、局部數(shù)據(jù)加載或者存儲(chǔ)部件個(gè)數(shù)等。
c. 是否需要存儲(chǔ)器保護(hù)、存儲(chǔ)器地址轉(zhuǎn)換或者存儲(chǔ)器管理部件(MMU)
d. 包含或者不包含系統(tǒng)總線接口
e. 系統(tǒng)總線寬度和局部存儲(chǔ)器接口寬度
f. 局部(緊密耦合)存儲(chǔ)器大小和數(shù)量。
g. 中斷數(shù)量及中斷類(lèi)型和中斷優(yōu)先級(jí)。
(ii) 擴(kuò)展選項(xiàng):增加設(shè)計(jì)人員自己定義的功能部件,包括:
a. 寄存器和寄存器文件。
b. 多周期、仲裁復(fù)雜指令功能部件。
c. 單指令流多數(shù)據(jù)流SIMD功能部件。
d. 將單發(fā)射處理器變?yōu)槎喟l(fā)射處理器。
e. 用戶定制接口,可以直接對(duì)數(shù)據(jù)通路進(jìn)行讀寫(xiě)操作,例如,類(lèi)似GPIO(通用輸入/輸出)引腳的處理器內(nèi)核端口或者引腳,用于擴(kuò)展先進(jìn)先出FIFO隊(duì)列的隊(duì)列接口(可以與其它邏輯或者處理器內(nèi)核進(jìn)行接口)。
配置選項(xiàng)的好處是讓設(shè)計(jì)人員通過(guò)僅選擇與其應(yīng)用有關(guān)的選項(xiàng),就可以構(gòu)建一個(gè)規(guī)模適度的處理器,并能夠滿足其特定應(yīng)用。擴(kuò)展選項(xiàng)的好處是讓設(shè)計(jì)人員根據(jù)應(yīng)用定制處理器,包括建立專(zhuān)用指令、寄存器文件、功能部件和相關(guān)接口,用于加速系統(tǒng)應(yīng)用算法的執(zhí)行。
4、自動(dòng)化軟件開(kāi)發(fā)工具套件支持
可配置和可擴(kuò)展的關(guān)鍵是不僅能夠自動(dòng)產(chǎn)生預(yù)先經(jīng)過(guò)驗(yàn)證的RTL代碼,用于設(shè)計(jì)人員定制處理器(包括所有系統(tǒng)擴(kuò)展功能),而且還能夠自動(dòng)產(chǎn)生完整的軟件工具,包括一個(gè)與處理器相匹配并經(jīng)過(guò)優(yōu)化的開(kāi)發(fā)工具套件、一個(gè)基于時(shí)鐘周期的指令集仿真器以及系統(tǒng)模型。
這種自動(dòng)化意味著編譯器知道設(shè)計(jì)人員所添加的新指令、相關(guān)的寄存器以及寄存器文件。因此,編譯器能夠?qū)τ脩舳x的指令進(jìn)行調(diào)度,并執(zhí)行寄存器分配操作。類(lèi)似地,軟件開(kāi)發(fā)人員在調(diào)試時(shí)除了處理器本身的基本寄存器,還能夠了解設(shè)計(jì)人員定義的寄存器和寄存器文件;同時(shí),軟件開(kāi)發(fā)人員能夠利用指令集仿真器對(duì)設(shè)計(jì)人員定義的新指令進(jìn)行仿真。與處理器相關(guān)的實(shí)時(shí)操作系統(tǒng)RTOS端口和系統(tǒng)模型也能夠自動(dòng)產(chǎn)生。Tensilica的軟件工具能夠在一個(gè)小時(shí)內(nèi)自動(dòng)產(chǎn)生上述軟件工具,這是對(duì)使用可配置處理器用戶的核心承諾,能夠執(zhí)行諸如SAD運(yùn)算,而不必采用RTL那樣的實(shí)現(xiàn)方法。
5、采用可配置處理器構(gòu)建視頻加速引擎建立多操作功能部件
將SAD這樣的融合操作加到一個(gè)可配置處理器中是一件麻煩的事情。一條稱(chēng)為“sub.abs.ac”的新指令可以完成“減法-絕對(duì)值-累加”運(yùn)算操作。這條新指令能夠?qū)D2中的操作變成圖3中的復(fù)操作。
圖3 使用新指令計(jì)算“減法-絕對(duì)值-累加”操作
將該指令添加到處理器中后,C編譯器能夠識(shí)別這條新的“sub.abs.ac”指令,并調(diào)度相關(guān)指令;調(diào)度器將顯示“sub.abs.ac”功能部件所使用的內(nèi)部信號(hào);匯編器能夠處理這條新指令;指令集仿真器ISS能夠按照時(shí)鐘周期模式進(jìn)行仿真。
新的專(zhuān)用視頻功能部件插入處理器后的數(shù)據(jù)通路簡(jiǎn)圖如圖4所示。注意到,除了產(chǎn)生功能部件邏輯外,硬件生成工具還能夠自動(dòng)插入前饋通路、控制邏輯以及旁路邏輯,以便將新的功能部件與數(shù)據(jù)通路中的其它邏輯互連。
圖4 插入sub.abs.ac視頻專(zhuān)用功能部件后的簡(jiǎn)化數(shù)據(jù)通路示意圖
包含新指令的C代碼描述的SAD算法如下:
for (row = 0; row < numrows; row++) {??for (col = 0; col < numcols; col++) {
sub.abs.ac( accum, macroblk1[row][col], macroblk2[row][col]);
} /* column loop */
} /* row loop */
正如前面提到的,對(duì)于一個(gè)16x16宏塊而言,增加新指令后程序主循環(huán)中的操作數(shù)減少到256個(gè)(即numrows = numcols = 16)。
6、建立單指令流多數(shù)據(jù)流SIMD功能部件
前面的SAD程序還可以進(jìn)一步優(yōu)化。程序中的內(nèi)循環(huán)將宏塊中16列做相同的運(yùn)算。這對(duì)于SIMD(單指令多數(shù)據(jù))功能部件而言是理想選擇,相應(yīng)的指令“sub.abs.ac16”針對(duì)16個(gè)像素同時(shí)完成sub.abs.ac操作,如圖5所示。
圖5 對(duì)16個(gè)像素同時(shí)進(jìn)行sub.abs.ac指令的單指令流多數(shù)據(jù)流計(jì)算操作
相應(yīng)的C語(yǔ)言過(guò)程名為sub.abs.ac16,利用此過(guò)程名重新改寫(xiě)的SAD內(nèi)核C程序代碼如下:
for (row = 0; row < numrows; row++) {
sub.abs.ac16( accum, macroblk1[row], macroblk2[row]);
} /* row loop */
通過(guò)改寫(xiě)后的SAD內(nèi)核程序從768個(gè)算術(shù)操作減少為僅16個(gè)算術(shù)操作。
然而,僅僅只有上述C程序代碼是不夠的。因?yàn)橹噶顂ub.abs.ac16需要從兩個(gè)宏塊中讀取128位的數(shù)據(jù),這需要兩個(gè)方面的支持:一個(gè)128位的寄存器文件和一個(gè)寬數(shù)據(jù)位的取數(shù)/存數(shù)接口,可配置處理器均支持這些功能。
7、建立用戶定制的寄存器文件
在Xtensa可配置處理器中,說(shuō)明一個(gè)任意寬度的定制寄存器文件就像寫(xiě)一行程序那么簡(jiǎn)單。例如,稱(chēng)為“myRegFile128”的過(guò)程語(yǔ)句建立一個(gè)寬度為128位的寄存器文件,長(zhǎng)度為4,并建立一個(gè)相應(yīng)的新的C數(shù)據(jù)類(lèi)型,“myRegFile128”能夠用于C/C++程序代碼說(shuō)明變量。軟件工具也建立“MOVE”操作,用于將各種C數(shù)據(jù)類(lèi)型轉(zhuǎn)換為新的定制數(shù)據(jù)類(lèi)型。因此,采用sub.abs.ac16過(guò)程和新寄存器文件后的SAD內(nèi)核C程序代碼如下:
for (row = 0; row < numrows; row++) {
myRegFile128 mblk1, mblk2;
mblk1 = macroblk1[row];
mblk2 = macroblk2[row];
sub.abs.ac16( accum, mblk1, mblk2);
} /* row loop */
現(xiàn)在C/C++編譯器將會(huì)產(chǎn)生一條MOVE指令,將數(shù)據(jù)從一般的C數(shù)據(jù)類(lèi)型移到定制的C數(shù)據(jù)類(lèi)型“myRegFile128”,并為新寄存器文件分配寄存器。
8、建立高數(shù)據(jù)帶寬的加載/存儲(chǔ)接口
為了對(duì)高帶寬定制寄存器文件(以及相應(yīng)的單指令流多數(shù)據(jù)流SIMD功能部件)進(jìn)行數(shù)據(jù)存取,處理器應(yīng)當(dāng)具有高帶寬數(shù)據(jù)加載/存儲(chǔ)操作能力。對(duì)可配置處理器而言,設(shè)計(jì)人員能夠說(shuō)明定制加載和存儲(chǔ)操作指令,直接完成對(duì)定制寄存器文件的高帶寬加載/存儲(chǔ)數(shù)據(jù)操作。然后,編譯器自動(dòng)產(chǎn)生與高帶寬加載/存儲(chǔ)接口相應(yīng)的加載/存儲(chǔ)指令。
經(jīng)過(guò)更新后的處理器數(shù)據(jù)通路如圖6所示。硬件生成工具產(chǎn)生高帶寬的定制寄存器文件、與數(shù)據(jù)存儲(chǔ)器相關(guān)的加載/存儲(chǔ)接口以及相應(yīng)的前饋邏輯、控制邏輯和旁通邏輯。硬件工具還產(chǎn)生相應(yīng)的硬件邏輯,用于將數(shù)據(jù)從基準(zhǔn)寄存器文件移到用戶定義的寄存器文件中。
圖6 插入寄存器文件和高帶寬加載/存儲(chǔ)接口的數(shù)據(jù)通路
9、更新地址的同時(shí)進(jìn)行加載
或者存儲(chǔ)操作
Xtensa可配置處理器允許用戶建立另一個(gè)非常有用的功能擴(kuò)展,即建立一條指令,能夠同時(shí)完成地址更新操作和數(shù)據(jù)加載/存儲(chǔ)操作。建立的新的加載/存儲(chǔ)操作指令能夠并發(fā)完成如下功能: Load A1 ← Memory(Addr1);Addr1 = Addr1 + IndexUpdate
該指令能夠完成“背靠背”的加載/存儲(chǔ)操作,而不需要專(zhuān)門(mén)指令對(duì)地址進(jìn)行更新。
10、建立先進(jìn)先出(FIFO)接口
和通用輸入/輸出端口
視頻和音頻均為流媒體,需要對(duì)處理器進(jìn)行快速數(shù)據(jù)訪問(wèn)。傳統(tǒng)的處理器受限于系統(tǒng)總線接口,以及數(shù)據(jù)操作執(zhí)行前對(duì)所以數(shù)據(jù)的加載與存儲(chǔ)訪問(wèn)。
為支持流媒體數(shù)據(jù)/輸出操作,Xtensa可配置處理器允許設(shè)計(jì)人員定義先進(jìn)先出(FIFO)接口以及通用輸入/輸出(GPIO)端口,以便直接對(duì)數(shù)據(jù)通路進(jìn)行讀寫(xiě)訪問(wèn)。FIFO和GPIO端口可以是任意數(shù)據(jù)寬度(可達(dá)1024位),數(shù)量不限(每個(gè)可包含1024個(gè)FIFO和GPIO端口)。這些高帶寬接口可以直接與數(shù)據(jù)通路相連,提供很高的數(shù)據(jù)吞吐量,通過(guò)處理器內(nèi)核對(duì)數(shù)據(jù)進(jìn)行讀、處理和寫(xiě)操作,這對(duì)于多媒體和網(wǎng)絡(luò)應(yīng)用而言是非常重要的。
具有FIFO接口和GPIO端口的數(shù)據(jù)通路如圖7所示。處理器可以進(jìn)行如下操作:首先從兩個(gè)FIFO(在確保兩個(gè)先進(jìn)先出隊(duì)列均不空的情況下)中取出數(shù)據(jù),然后計(jì)算一個(gè)復(fù)操作(例如一個(gè)乘累加舍入操作),最后將計(jì)算結(jié)果壓入輸出FIFO(在確保先進(jìn)先出隊(duì)列不滿的情況下)。然后,硬件生成工具產(chǎn)生相應(yīng)的接口信號(hào)、控制邏輯和旁通邏輯等;為配置的處理器產(chǎn)生完整的RTL代碼。軟件生成工具產(chǎn)生一套完整的編譯器工具,以及時(shí)鐘周期精確的指令集仿真器ISS,用于對(duì)新指令進(jìn)行仿真。注意到,這種由設(shè)計(jì)人員定義FIFO接口和GPIO端口的能力是Xtensa可配置處理器所獨(dú)有的。
圖7 采用定制先進(jìn)先出(FIFO)接口和通用輸入輸出(IO)端口的高速通信
11、加速?gòu)?fù)雜的控制密集型代碼的執(zhí)行
多媒體應(yīng)用中控制代碼的數(shù)量與復(fù)雜性顯著增長(zhǎng),使得程序中數(shù)據(jù)密集型操作與計(jì)算時(shí)間近似等價(jià)。例如,H.264主程序譯碼器中的關(guān)鍵部分為CABAC(上下文相關(guān)二進(jìn)制算術(shù)編碼)算法。該算法幾乎完全是具有數(shù)據(jù)計(jì)算和數(shù)據(jù)比較的控制流判決樹(shù)。
由于計(jì)算的復(fù)雜性非常高,絕大多數(shù)傳統(tǒng)處理器均采用專(zhuān)用的RTL加速器來(lái)完成CABAC算法。然而,在可配置處理器上可以通過(guò)增加一組專(zhuān)用指令來(lái)更加有效地實(shí)現(xiàn)CABAC算法。這種實(shí)現(xiàn)方法的好處是避免了數(shù)據(jù)在處理器和RTL加速器之間不停地交換數(shù)據(jù)。采用可配置處理器的另一個(gè)好處是采用指令擴(kuò)展技術(shù),由于專(zhuān)用硬件在處理器內(nèi)部,因此可以更好地進(jìn)行硬件和軟件界面劃分。
12、小結(jié)
現(xiàn)代可配置和可擴(kuò)展處理器是構(gòu)建定制視頻和音頻引擎的理想選擇。Tensilica公司提供相關(guān)的視頻和音頻IP作為SOC模塊,包括HiFi 2音頻引擎、鉆石系列標(biāo)準(zhǔn)的38xVDO(視頻)多標(biāo)準(zhǔn)和多分辨率視頻方法。與之匹配的軟件編解碼器是非常重要的。HiFi 2音頻引擎與相關(guān)的軟件一起可完成絕大部分流行的音頻編解碼器,例如MP3、AAC、WMA等。類(lèi)似地,鉆石 38xVDO 視頻加速引擎與相應(yīng)的編碼器和譯碼器軟件可以實(shí)現(xiàn)H.264 (包括Baseline、Main和profiles)、MPEG-4 (SP 和 ASP)、 MPEG-2、VC-1/WM9及其它標(biāo)準(zhǔn)。這些視頻技術(shù)涵蓋了從QCIF 到CIF以及SD各種分辨率,功耗低,面積小。












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論