選用TMS320DM642作為系統CPU,并采用最新視頻編碼標準H.264壓縮算法,實現基于CDMA網絡傳輸的無線視頻監控和視頻數據存儲系統。
隨著運營商在國內大部分地區推出GRPS和
2010-08-16 10:32:33 1676
1676 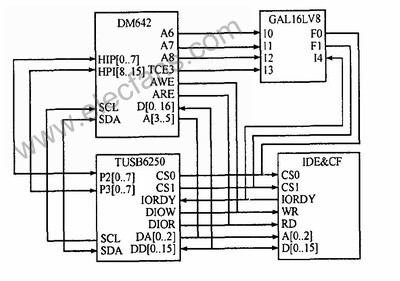
以DM642為核心,設計了一款智能視頻分析系統,支持標清視頻。采用模塊化設計,通過視頻智能分析,對目標實現了檢測、識別、跟蹤及預警功能。
2014-01-09 15:55:421401 
的TMS320DM642器件很好地解決了上述問題,其豐富的外圍接口及專用的視頻處理模塊使得其非常適合日益發展的視頻處理系統。這里,提出了以TMS320DM642為核心,由解碼器TVP5150為視頻輸入解碼處理器
2020-08-04 16:29:001111 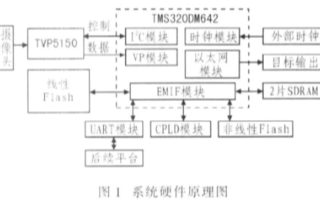
目前,視頻運動控制卡的研究已經成為熱點。本文針對TI公司的視頻高速處理芯片TMS320DM642,設計了對目標物體進行視頻實時跟蹤的運動控制卡。希望通過本文分享DM642平臺應用中的一些經驗。
2020-10-19 10:24:141239 
FLASH存儲器和一路視頻編碼和兩路視頻解碼等,其結構如圖1所示。DM642基于C64X內核,主頻高達600MHz,采用超長指令字(VLIW)結構,每個指令周期可并行處理8條32位的指令,處理能力達
2011-08-10 14:53:53
新手求助,有在dsp上實現meanshift的代碼嗎?新手不知道如何將meanshift從opencv移植到DM642上,求指教
2014-04-01 11:45:29
各位師兄師姐好,我是名學生,老師現在讓我學習DSP,給我提供的開發板是SEED-DEC643,我DSP的基礎就是0,我現在不知道怎么開始學習啊?另外,我想知道DM643與DM642的區別是什么,價錢哪個貴啊?希望有經驗的師兄師姐可以給我指出一個好方法。
2013-08-13 19:00:00
誰可以幫忙發些適合初學者用的DM642的資料啊,非常感謝了!QQ:2363634155
2013-10-19 11:06:04
本帖最后由 人間煙火123 于 2018-6-15 11:43 編輯
要寫個dsp側的程序,開啟中斷,不使用dsp/bios,通過類似642加中斷,定義描述DM642中斷的向量表文件,這里
2018-06-15 00:34:50
CIPS-VIDEO雙向實時圖像處理雙路應用主板,采用專業的多媒體(圖像視頻/音頻)處理芯片(TI 的DSP TMS320DM642)為核心,內嵌自主開發的嵌入式實時多任務操作系統(CIPS),對數字視頻
2008-12-01 11:35:41
DM642高清實時視頻開發平臺 dm642_Schematics[此貼子已經被作者于2009-7-10 10:46:18編輯過]
2009-07-10 10:43:27
視頻監控系統的最大瓶頸。這要求DSP有足夠出色的外部接口能力和較高的內核時鐘,使用高速的緩沖設備和高速的存儲器,并采用各種技術完成超大量視頻數據的采集和處理。 TMS320DM642(簡稱DM642
2011-05-03 11:37:38
本文介紹了一個基于DM642平臺的編碼器的設計與實現。
2021-06-03 07:11:08
要做課程設計,題目就是:基于DSP的MPEG2的視頻編碼器設計與實現,不知道該怎么下手,望高手給個思路,指導一下,學校有ICETEK-DM642-P4-IDK-M試驗箱,要求是使用試驗箱用C語言實現MPEG2視頻編碼。希望高手解答下,或提供點資料,不勝感激!
2012-07-02 20:34:51
摘要:介紹了采用IXP425作為核心主控單元和3片DM642作為核心數據處理單元的會議電視多點控制單元的硬件設計原理和實現方法。主控制器IXP425模塊完成網絡發送/接收、數據調度、PCI控制等功能
2019-06-28 08:05:49
本文針對自行研制的基于TMS320DM642(以下簡稱DM642)DSP的視頻處理板卡,使其在C64x系列DSP的實時操作系統DSP/BIOS的環境下運行,實現基于類/微驅動模型的視頻采集驅動程序,并進一步描述采用EDMA(增強的直接存儲器存取控制器)的數字視頻圖像信號的實時傳輸。
2021-06-08 07:05:13
本文較詳細地介紹DM642的主要特性和系統應用開發技術,并給出基于DM642的視頻監控應用實例。
2021-06-04 06:33:07
怎么實現基于DM642的視頻監控系統硬件設計?
2021-06-07 06:04:28
本文針對自行研制的基于TMS320DM642(以下簡稱DM642)DSP的視頻處理板卡,使其在C64x系列DSP的實時操作系統DSP/BIOS的環境下運行,實現基于類/微驅動模型的視頻采集驅動程序,并進一步描述采用EDMA(增強的直接存儲器存取控制器)的數字視頻圖像信號的實時傳輸。
2021-06-08 06:07:33
新一代視頻編碼標準H.264在高速DSP平臺上的實現與優化Implementation and Optimization the New Generation Video Coding
2008-06-25 10:35:31
我還想求教一下,我現在用DM642做智能視頻監控,思路大概是這樣,基于SURF特征點的運動補償---->幀差法---->形態學處理---->提取目標位置---->卡爾曼跟蹤,幀率25,畫面640*480,外擴32SDRAM,DM642能夠滿足需要嗎???實時性!!!
2018-06-21 08:09:18
要做一個基于DSP實時圖像處理的項目,老師讓選型。本來看DM642用的較為廣泛,想選用DM642,但老師說實驗室好幾年前就開始使用DM642,而且要求盡可能往小型化的方向發展,麻煩各位推薦一下具體的DSP型號,主要是:小型化、低功耗,運算速率與DM642相近甚至更低都行
2013-12-23 20:24:10
現在正在用DM642進行算法開發,準備使用ti提供的VLIB庫(支持DM642的VLIB庫的版本采用的是2.0和2.2)。現在的問題是VLIB是不是只能在DSP/BIOS下使用?能不能在沒有操作系統
2018-07-25 07:26:55
本帖最后由 一只耳朵怪 于 2018-5-31 16:17 編輯
1、請問DM642可以實現兩路D1格式的mpeg-2的編碼嗎?要求具有實時性2、對于1路時頻頻輸入來說,進行mpeg-2的編碼
2018-05-31 03:22:36
本帖最后由 一只耳朵怪 于 2018-6-22 10:25 編輯
各位大俠,我想問一下在DM642實現千兆視頻傳輸的設計中,我使用了一款PCI接口的千兆以太網控制芯片與DM642相連,我想問一下這種方式下能夠使用NDK嗎?十分著急知道答案,謝謝各位!
2018-06-22 07:25:39
DSP的外設驅動開發模型是怎樣的?怎樣去設計一種DM642芯片視頻驅動程序?
2021-06-04 06:03:44
fixed-point DSP generation in the TMS320C6000™ DSP platform. The TMS320DM642 (DM642) device is based on the second-generation high-performan
2008-08-07 21:18:22 117
117 數字信號處理器TMS320DM642在多媒體通信領域有著廣泛的應用。以利用XDAIS算法在DM642上實現網絡視頻編碼器為例,研究了DM642在網絡視頻傳輸系統開發中的一般過程,介紹了系統的硬件
2009-03-17 11:49:2430 本文闡述了DM642視頻監控系統硬件設計的過程和工作原理。
2009-04-02 11:47:4019 分析了DM642 的芯片和外圍接口,提出了基于TI 公司的DSP 芯片- TMS320DM642 的人臉檢測追蹤方法。首先采用了YUV 模型在視頻流中進行檢測,得到膚色圖像,然后求出各連通區域的外接
2009-06-04 08:57:4122 本文介紹了一種基于TMS320DM642 和Philips 視頻編解碼芯片的視頻處理系統,給出了系統的硬件設計、視頻接口連接圖、以及軟件配置。通過實際應用證明該方案具有高速視頻輸入輸出能
2009-06-16 10:56:1634 介紹了一種基于TI TMS320DM642 的實時、四路MPEG4視頻壓縮PCI 板卡的設計與實現。對系統軟硬件構成以及MPEG4視頻編碼和優化進行了分析,試驗結果表明該板卡可以實時對視頻流進行壓縮
2009-07-08 14:30:3822 TMS320DM642 DSP 是TI 公司新近推出的一款高性能數字多媒體處理器,它的兩級高速緩存(Cache)結構為高復雜度視頻編碼算法的高效率實現提供了有力的保證。綜合考慮視頻編碼算法特
2009-08-07 09:35:4427 結合TI 公司C64 系列DSP 芯片指令并行處理的特點,在自主開發的以TMS320DM642 為核心的嵌入式MPEG-4 視頻監控平臺上,通過對編碼軟件進行C 語言級、線性匯編級的優化,實現了高效運行
2009-08-27 12:19:1019 高可靠性產品數字媒體 DM642 DSP DSP 1 C64x DSP MHz (Max) 720 CPU 32-/64-bit Ethernet MAC 10
2022-12-14 14:40:53
在視頻監控系統和視頻會議系統以及流媒體等應用中,數字視頻編碼成為最重要和最基本的技術手段,論文作者針對視頻監控系統,論述了基于TMS320DM642 媒體處理器DSP 平臺,實現H.26
2009-08-29 11:05:579 設計并實現了基于DSP 芯片TMS320DM642 的H.264 編碼器。詳細介紹了H.264 算法在DSP上的移植和優化。為使編碼器達到實時應用的要求,采用基于C64x CPU 的軟件優化技術,對H.264的一些核
2009-09-03 14:30:3423 闡述了低碼率視頻編碼國際標準H.264的主要內容,重點討論了H.264編碼在DSP TMS320DM642上的實現和優化。關鍵詞: H.264;TM320DM642;代碼優化 &
2009-09-11 10:54:0226 在分析H.264 編碼器的結構和復雜度之后,提出了結合TMS320DM642 性能特點的一些優化方法。這些方法提高了程序代碼的并行性和存儲器的訪問效率,其中重點介紹了算法中比較耗時的
2009-11-30 12:06:3915 本文將對以TMS320C64x/DM64xDSP為基礎的通用視頻編碼器優化技術進行介紹。基于DM64x的視頻編碼優化結合了多種技術,其中包括算法/系統優化、存儲器緩沖優化、EDMA及高速緩存利用率優
2009-12-02 16:03:1518 本文概述了 H.264 視頻壓縮編碼標準的主要特性,簡要介紹了當前H.264 的幾種開源軟件。詳細分析了其中 X264 參考程序的具體結構,并針對TMS320DM642 平臺建議了可能的優化方向。
2009-12-02 16:34:1721 本文介紹了 TMS320C6416 DSP 和MPEG-4ASP (Advanced Simple Profile )視頻編碼器在SP基礎上新增的工具,詳細闡述了基于該平臺實現MPEG-4ASP 視頻編碼器的軟件優化方法,最后通過實驗結果的比較展
2009-12-02 17:07:1215 H.264 實時編碼器的研究和實現是目前視頻通信研究領域的一個熱點問題,本文介紹了基于TMS320DM642 平臺的H.264 編碼器的優化,重點介紹了基于DM642 的整數DCT 變換、量化和匹配
2009-12-18 12:13:3719 為提高基于H.264 算法的x264 開源代碼的運行效率,提出了一系列優化實現方法。首先結合TMS320DM642 硬件特點提出了對編碼器結構進行調整,然后使用內聯函數和DSP匯編語言對x264 開
2009-12-23 16:07:1826 以TI 公司的TMS320DM642 為主處理器,采用基于DSP/BIOS 的設備類/微型驅動模型,開發其視頻口的驅動程序,并結合PHILIPS 公司的SAA7113H 解碼芯片,實現了視頻處理系統的采集模塊,最后
2010-01-13 15:27:59107 基于DM642 的X264 開源代碼實現的研究
摘要本文概述了 H.264 視頻壓縮編碼標準的主要特性,簡要介紹了當前H.264 的幾種開源軟件。詳細分析了其中 X264 參考
2010-02-10 14:29:3049 DSP 網絡視頻監控
DSP 網絡視頻監控及OpenCV在DSP平臺的移植摘要本系統使用DM642 網絡圖像處理開發平臺和OpenCV 來構建網絡視頻監控程序。系統采用客戶機
2010-04-07 14:35:3732 AVS-M是具有自主知識產權的視頻壓縮標準,具有很好的壓縮性能。DM642處理器是TI公司研制的一款專門面向多媒體應用的專用數字信號處理芯片,具有很強視頻處理能力,是AVS-M標準DSP
2010-08-04 15:24:4512 本文介紹了基于TMS320DM642和Philips視頻編解碼芯片的視頻處理系統,給出了視頻接口的連接圖。在分析I2C總線協議的基礎上,文中詳細敘述了DM642通過I2C模塊對視頻編解碼芯片的寄存器
2010-08-05 15:39:0449 本文完成了視頻服務器的硬件設計,針對如何充分發揮DM642硬件平臺的處理能力,提出了關于AVS-M算法的編碼優化方案,該方案是對軟件框架流程進行仔細考慮后提出的,避免了冗余
2010-08-05 16:22:220 網絡攝像機是當今網絡視頻應用的一大熱點,根據這方面的應用需求提出了一種全新的解決方案。該方案的實現是基于TMS320DM642處理器的,并且采用JPEG編碼標準,最終實現了一個成
2010-09-28 10:30:4754 基于TMS320DM642 DSP、視頻處理技術和無線傳輸技術設計并實現了一種嵌入式鐵路路障視頻報警系統。給出了系統的總體結構和各個組成模塊,分析了圖像采集、圖像處理和無線報警部
2010-11-11 15:59:1929 針對構建高穩定性、高魯棒性的多媒體數字監控系統設計并實現了一款基于TMS320DM642型數字信號處理器的四路實時MPEG-4視頻采集兼壓縮處理PCI板卡。詳細介紹TMS320DM642的硬件架
2010-12-03 16:22:1880
The TMS320C64x™ DSPs (including the TMS320DM642 device) are the highest-performance
2010-12-05 22:57:4821
The TMS320C64x™ DSPs (including the TMS320DM642 device) are the highest-performance
2010-12-05 23:04:096 1 前言
DM642 (TMS320DM642)型處理器是TI最新推出的面向多媒體處理領域的數字信號處理器(DSP).給多媒體設備的實現提供了另一種有效的手段。 DM642建立在C64x DSP核基礎上.
2010-09-15 14:36:331791 
DM642作為高性能的視頻處理芯片,被廣泛應用到視頻處理的很多領域,但是DM642的I2C應用容易遇到I2C、VP等死鎖,以及
2010-11-27 10:52:001623 
摘要:在DM642 EVM平臺上實現了 H.264視頻編碼器,并從內存分配、Cache優化、代碼優化以及匯編程序級優化等幾個方面對編碼
2011-01-10 14:12:143203 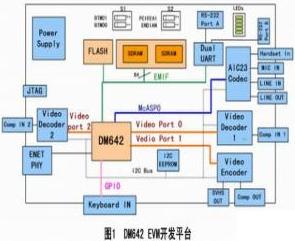
系統研究并實現了一個通用的基于DM642的視頻處理系統。該系統已經調試成功,它可以完成視頻信號的輸入與輸出,可以應用于視頻圖象采集和處理的各種場合中
2011-03-23 11:49:274373 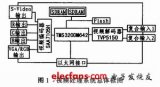
為提高基于H.264算法的x264開源代碼的運行效率,提出了一系列優化實現方法。首先結合TMS320DM642硬件特點提出了對編碼器結構進行調整,然后使用內聯函數和DSP匯編語言對x264開源代碼進
2011-04-03 23:30:5029 本文基于單片TI DM642 設計實現了四路MPEG
2011-06-21 10:54:0542 本文介紹了5/3提升小波變換及其在DM642上的實現。在通用的DSP芯片上實現該算法具有很好的可擴展性、可升級性與易維護性。用這種方式靈活性強,完全能滿足各種處理需求。
2011-08-09 11:25:241214 
TMS320DM642是TI公司推出的一款針對視頻和圖像處理領域應用的數字多媒體處理芯片,具有處理能力強和集成度高等特點,是目前實現H.264視頻編碼器的理想芯片之一。很多國內外公司都在
2011-08-17 11:51:431682 
本文主要介紹的就是基于DM642的視頻采集處理系統中I2C模塊的正確初始化,以及通過I2C總線正確地對視頻解碼芯片SAA7115的寄存器讀/寫程序。
2011-09-23 11:38:241482 
介紹了一種基于DM642DsP與PcI總線的多路MPEG一4多媒體實時壓縮板卡系統;該系統由視頻解碼sAA7144H采集視頻數據,由PcMl80lu采集音額,多蝶捧數據采集到DM642DsP,完成硬件壓縮、位瀛復合
2011-09-29 17:18:2939 本論文以MS320DM642數字信號處理器為核心,搭建了聲源定位及攝像頭自動控制的平臺。論文中論述了:McASP的原理和應用方法;聲波的A/D變換及采樣模塊設計以及該模塊與DSP的接口設計
2012-02-15 11:14:48115 主要介紹了DM642存儲空間和EDMA控制器的特點,給出了EDMA在視頻實時編碼系統中圖像數據傳輸的具體控制和實現方法。實測結果表明,靈活使用EDMA不僅能夠提高圖像數據傳輸效率,而且可以充
2012-03-21 15:19:1113 該文針對圖像信號的特點以及DM642視頻接口原理,設計了多DM642處理系統中視頻接口的有效擴展。設計中利用FPGA進行數字視頻信號的預處理,并根據具體的系統實現了視頻數據的分流,同
2012-03-21 15:20:1035 為滿足現代實時網絡視頻應用的需求,提出并實現了一種基于TI公司多媒體DSP芯片TMS320DM642的實時網絡視頻系統,給出了網絡視頻節點的硬件及軟件的詳細設計方案。結果證明,該系統能
2012-04-05 15:24:1943 為了實現基于DSP的H.264視頻編碼器的實時性能,提出了一系列優化實現方法。首先結合TMS320DM6437硬件特點,描述了X264代碼向TMS320DM6437平臺的移植過程和優化方法,重點介紹了整數DCT變換
2012-05-22 15:10:2563 介紹了一種新型的多媒體DSP處理器DM642的結構和功能,總結了開發DM642系統的應用技術和方法,并給出了基于DM642的視頻監控系統實例。
2012-05-28 14:39:071237 
TI芯片 DM642 基于NDK的DSP網絡編程
2016-05-19 13:41:1910 DM642 EVM原理圖,又需要的 下來看看
2016-08-05 18:37:5718 DM642 EVM原理圖,有需要的下來看看
2016-08-19 17:04:5325 DM642的原理圖和PCB的源文件,下來看看
2016-12-25 00:43:2651 基于DM642的H.264編碼算法優化與實現
2017-05-18 09:22:581 TMS320DM6446的H.264視頻編碼算法的移植與優化
2017-10-26 14:17:572 DM642機器視覺系統的設計
2017-10-30 15:19:1710 摘要:采用兩片TI公司的專用視頻處理芯片TMS320DM642設計了一種多路視頻監控系統。其中,DSP1與視頻采集芯片SAA7113共同完成多路視頻的采集,并拼接成一路視頻圖像輸出;DSP2完成
2017-10-30 17:03:374 能力使得DM642可以進行實時多視頻圖像處理。它的增強型直接內存存取 (EDMA)對DSP圖像處理系統是非常重要的,它可以在沒
2017-12-02 18:23:28500 這個應用報告描述了軟件開發工具的不同之處。DM642 DSP器件和新只在達芬奇?等平臺之間DM648或DM6437。特別是新的、新的駕駛和訪問方法在設備之間比較外圍設備。部分源代碼示例介紹了外圍接入
2018-04-18 16:04:1911 電子發燒友網為你提供TI(ti)SM320DM642-HIREL相關產品參數、數據手冊,更有SM320DM642-HIREL的引腳圖、接線圖、封裝手冊、中文資料、英文資料,SM320DM642-HIREL真值表,SM320DM642-HIREL管腳等資料,希望可以幫助到廣大的電子工程師們。
2018-10-15 16:50:59

。同H.264相比,MPEG4具有軟硬件開發成本低和更容易實現的優勢,是目前視頻編碼應用的主流。本文提出了一種基于TMS320DM642 DSP的MPEG4視頻編碼器的實現方法,該方案可用于遠程視頻監控、視頻會議等諸多領域。
2019-07-29 08:14:002457 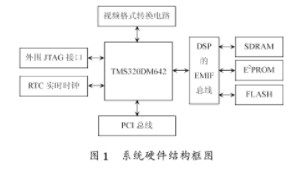
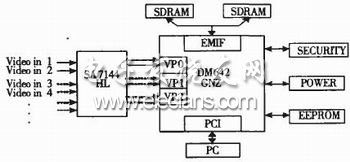
關鍵詞:DM642 , 監控硬件 , 嵌入式 , 無線視頻 選用TMS320DM642作為系統CPU,并采用最新視頻編碼標準H.264壓縮算法,實現基于CDMA網絡傳輸的無線視頻監控和視頻
2019-01-31 00:11:01413 ,基于DSP的海量視頻數據的實時處理的關鍵則是實時、合理的視頻數據采集。本文針對自行研制的基于TMS320DM642(以下簡稱DM642)DSP的視頻處理板卡,使其在C64x系列DSP的實時操作系統DSP/BIOS的環境下運行,實現基于類/微驅動模型的視頻采集驅動程序,并進一步描述采
2019-02-03 00:09:01412 采集驅動的原理。 結合TMS320DM642芯片類/微型驅動模型,提供了按幀采集ITU-R BT.656數據驅動的實現方法,并詳細討論視頻采集驅動的硬件配置及軟件設計中的幀緩存管理、同步及數據搬運
2019-02-03 00:13:02359 本文以TMS320C6000系列DSP中的一款TMS320DM642多媒體芯片為例,來具體說明如何設計嵌入式DSP數字視頻監控系統的硬件電路。
2021-03-17 09:44:192845 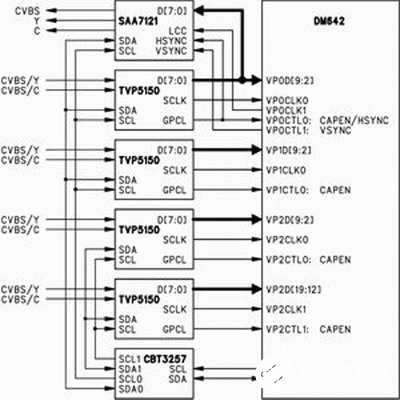
視頻編碼工作原理大致為:輸入的模擬視頻信號經TVP5150(支持PAL和NTSC兩種制式)被數字化為YUV4:2:2的數字視頻格式,經由I2C總線被送至輸入緩沖區(采用三緩沖機制), DM642
2021-03-17 11:50:181921 
 電子發燒友App
電子發燒友App











 工商網監
工商網監
評論