 電子發燒友App
電子發燒友App


元宇宙時代的來臨對實時3D引擎提出了諸多要求,Unity作為游戲行業應用最廣泛的3D實時內容創作引擎,為應對這些新挑戰,提出了Unity云原生分布式運行時的解決方案。LiveVideoStack 2023上海站邀請到Unity中國的解決方案工程師舒潤萱,和大家分享該方案的實踐案例、面臨的問題、解決方式,并介紹了Unity目前對其他方案的構想。
文/舒潤萱
大家好,我叫舒潤萱,現在在Unity中國擔任解決方案工程師,主要負責開發的項目是Unity云原生分布式運行時。
首先介紹一下Unity。Unity是游戲行業應用最廣泛的3D實時內容創作引擎。截止2021年第4季度,70%以上移動平臺的游戲是使用Unity開發的。
但Unity不止是一個游戲引擎,Unity的業務目前涉及到汽車行業、建筑行業、航空航天行業、能源行業等等各行各業。
Unity的業務在全球都有開展,在18個國家有54個辦公室。在中國,在上海、北京、廣州都有辦公室,在臨港也開了一間新的辦公室。
Unity覆蓋的平臺是最廣泛的,它支持超過20個主流平臺,率先支持了Apple新發布的vision OS。

我今天的分享將從這六個方面進行。
-01-
元宇宙時代的挑戰
首先,實時3D引擎在元宇宙時代會遇到什么挑戰?

Unity認為元宇宙會是下一代的互聯網,它將是實時的3D的、交互的、社交性的,并且是持久的。

元宇宙會是一個規模龐大的虛擬世界,這個虛擬世界里有很多參與者,它將會是一個大量用戶實時交互的場景。同時,元宇宙它必須是一個持續穩定的虛擬世界。
參與者在這個虛擬世界里對它進行的改變將會隨著時間保留下來,并且它是穩定的狀態。這就對實時3D交互造成了很多挑戰。

首先,因為這個虛擬世界將會是一個大規模的高清世界,里面將會有數量龐大的動態元素、靜態元素,所以它對實時3D引擎提出了渲染的挑戰。
其次,它伴隨著大量的網絡傳輸,對引擎的可擴展性和可伸縮性提出了很高要求,所以對運行平臺來說也是一個不小的挑戰。
最后,因為這個虛擬世界會有超大規模的物理仿真,用戶將會在其中進行大量的實時交互,所以這對運算資源也是一個巨大的挑戰。
-02-
Unity分布式運行時
為了應對這些挑戰,Unity提出了分布式運行時的解決方案。

這個方案由兩部分組成,第一個部分是Unity云原生的分布式渲染,第二個部分是Unity云原生分布式計算。
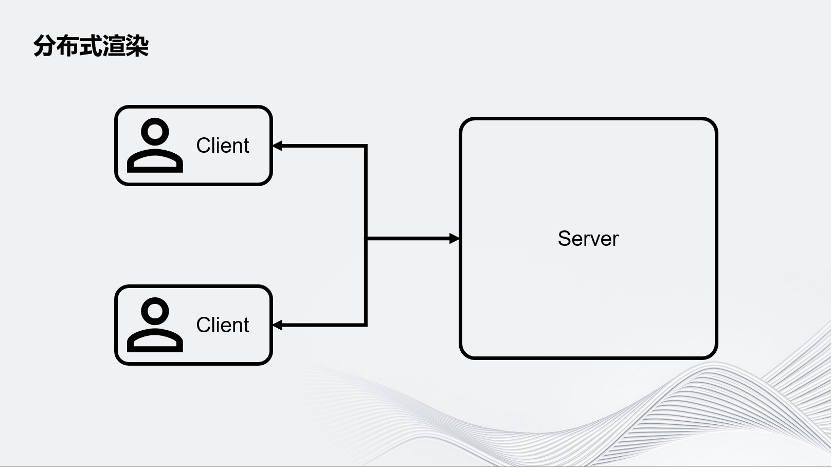
首先介紹分布式渲染。要做一個多人聯網的體驗,可以從最簡單的Server-Client架構入手。如圖所示,在這個架構中有一個中心化的Server,它可以服務于多個Client。這張圖上畫了兩個Client,這是最簡單的架構。
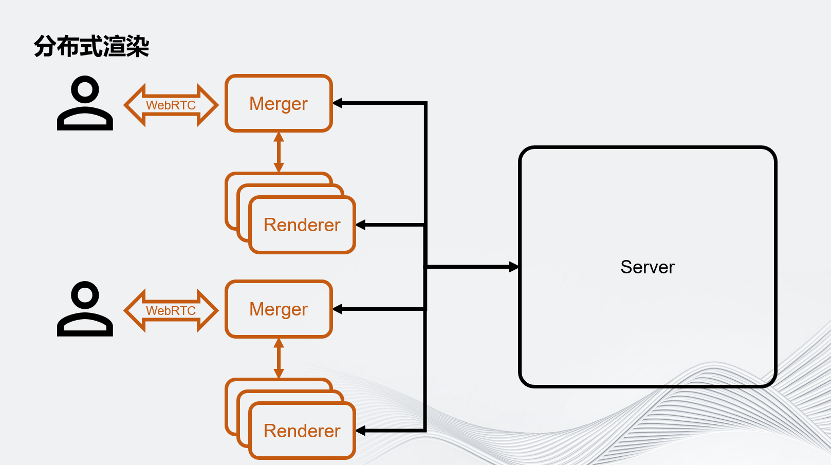
為了對應大規模的渲染壓力,Unity把用戶的Client端拆成了Merger和Renderer。在這里面,一個Merger對應多個Renderer,這些Renderer將會負責虛擬世界的渲染。我們把一幀的渲染任務拆分成很多個子任務,分別交給這些Render進行。Merger負責把Renderer渲染的畫面組合成最終畫面,之后通過WebRTC推流的方案推給用戶的客戶端。要注意,這里除了用戶的客戶端以外,所有的環境都是運行在云上的。
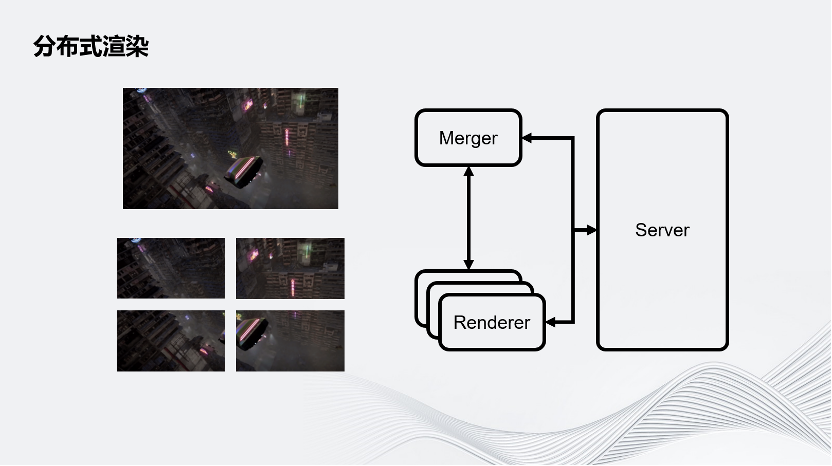
圖示為一個最簡單的屏幕空間拆分,即把一個完整的畫面在屏幕空間上拆成幾個部分。除此之外還有其他拆分方式,例如通過時間拆分:假設有4個Renderer,第一個Renderer渲染第一幀,第二個Renderer渲染第二幀,第三個Renderer渲染第三幀……以此類推,再把它們組合成一個完整的序列。
Unity現在也在實驗一個新的拆分方式:在Merger上渲染一個比較高清的近景,再把遠景拆分到幾個Renderer上。Renderer的幾個畫面可以組成一個天空盒推到Merger上,這樣Merger就可以同時擁有細節比較豐富的近景和遠景。Unity的架構允許開發者根據自己的業務需求定義自己畫面的拆分方式。
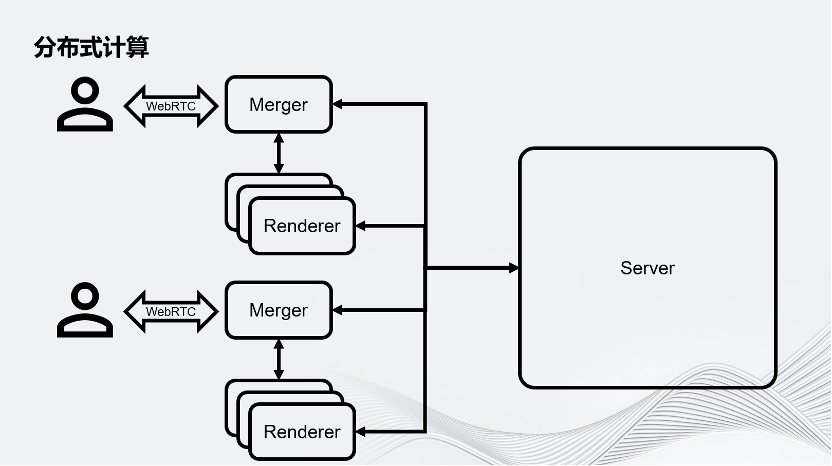
回到這個架構圖,想象在一個大型的虛擬世界里,有成千上萬用戶連入運行時,通過分布式渲染,把原本一個進程服務對應一個用戶的場景,拆分成好幾個進程服務于一個用戶,因此這個場景就會對Server提出巨大的挑戰。為了應對這個挑戰,Unity提出了分布式計算。
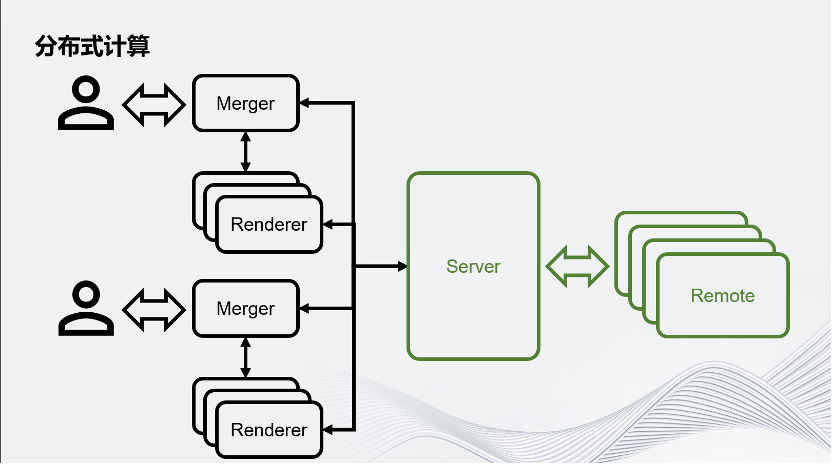
這種分布式計算把Server拆分成了Server和Remote,用 Remote分擔Server的一些運算壓力。
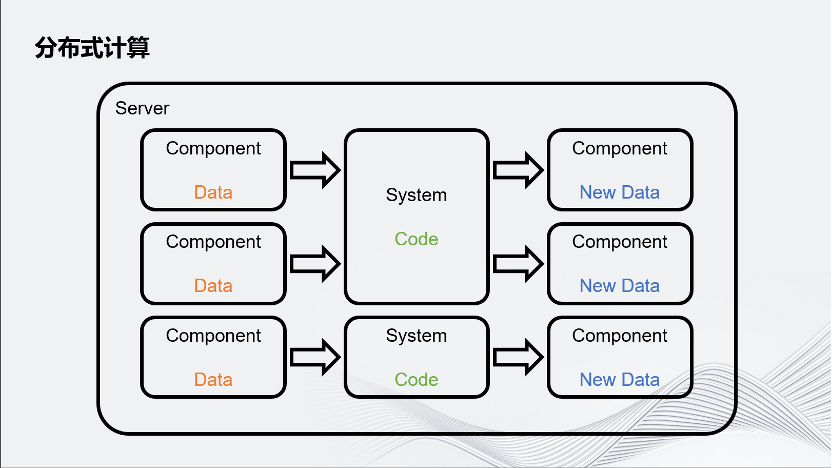
簡要概述一下Unity是怎樣把計算任務分配給Remote的。Unity游戲的業務流程可以簡單拆分成數據和數據處理器,數據叫做Component,數據處理器實際上就是業務邏輯,代碼叫System。每個System有自己感興趣的數據,它會讀取這個感興趣的數據,通過邏輯進行數據更新。
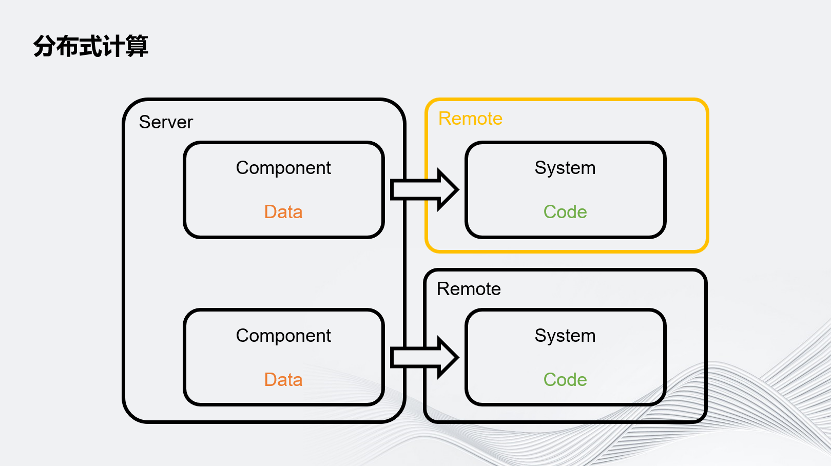
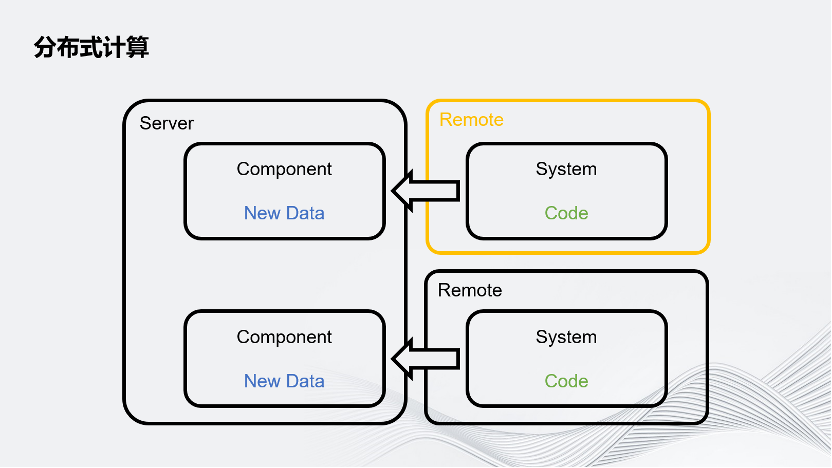
Unity把這個System跑在遠程的機器上,而不是本地,之后把它感興趣的數據通過網絡發送給遠程的機器,它就可以像本地處理一樣處理這個數據,再把更新的數據通過網絡發回給Server。
視頻編解碼與實時渲染
下面進入今天的正題,視頻編解碼與實時渲染。
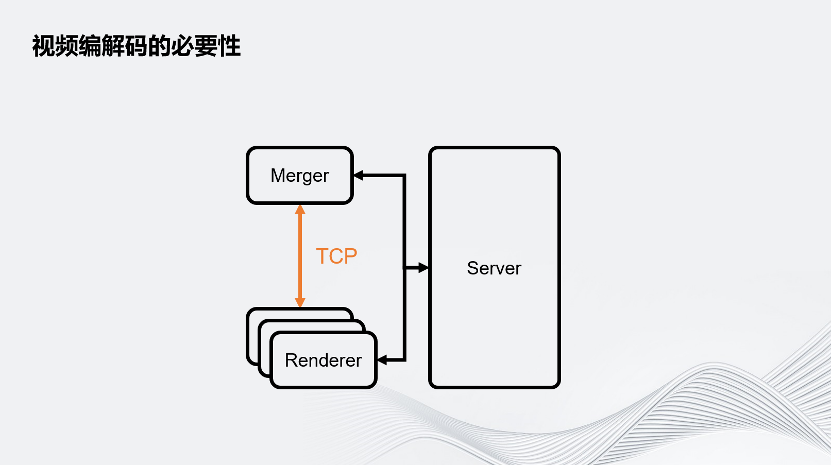
為什么要在分布式渲染中引入視頻編解碼?
可以看這個簡化的分布式渲染架構圖。Merger和Renderer之間的通信是通過網絡TCP傳輸的,即圖像是通過TCP傳輸的。

這個做法有兩個問題:
一是會遇到網絡帶寬瓶頸,在實時3D交互的場景下,一般至少要Target到1080p60幀。而如果傳的是8 bits RGBA的圖像格式,需要的帶寬是4Gbps,遠遠超出了常見的千兆帶寬1 Gbps,很多機房沒有辦法接受。即使對Raw Data進行YUV420的簡單壓縮,它也要占用約1.6 Gbps的帶寬,超過了千兆。
其次是性能問題。因為Unity的畫面是從GPU渲染出來的,為了通過網絡傳輸這個畫面,要先把GPU顯存上的圖像數據先回傳到CPU端。這個回讀就會導致需要暫停渲染的流水線,因為目前Unity優化較好的實時3D引擎的渲染都是流水線形式的,即CPU產生場景數據,再把這個場景數據交給GPU渲染,同時CPU可以進行下一幀的計算。但是如果數據是反過來從GPU回到CPU,意味著需要把流水線暫停,包括GPU、CPU上的所有任務都要等待回讀完成之后才能繼續工作。
這里截取了一張Unity的回讀指令,它消耗的時間是7.22毫秒,在實時交互的場景下,希望做到的是60幀的體驗,即16毫秒,因此用7.22毫秒的時間把這張圖片讀回來是無法接受的。
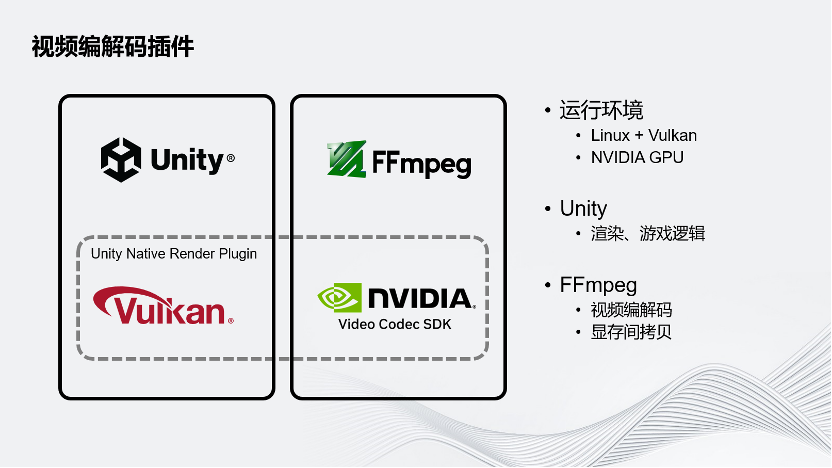
為了解決這兩個問題,Unity為分布式渲染的方案開發了Unity Native Render Plugin。Unity的目標運行環境是云端,Linux和Vulkan的圖形API。云端一般配備的是NVIDIA GPU,希望采用NVIDIA GPU進行硬件的視頻編解碼。在這個方案下面,Unity還是負責虛擬世界的渲染和邏輯。FFmpeg負責視頻的編解碼以及把Unity的圖像在顯存內部拷貝給NVIDIA的Video Codec SDK,Unity的插件就是連接這兩個部分以實現目標。
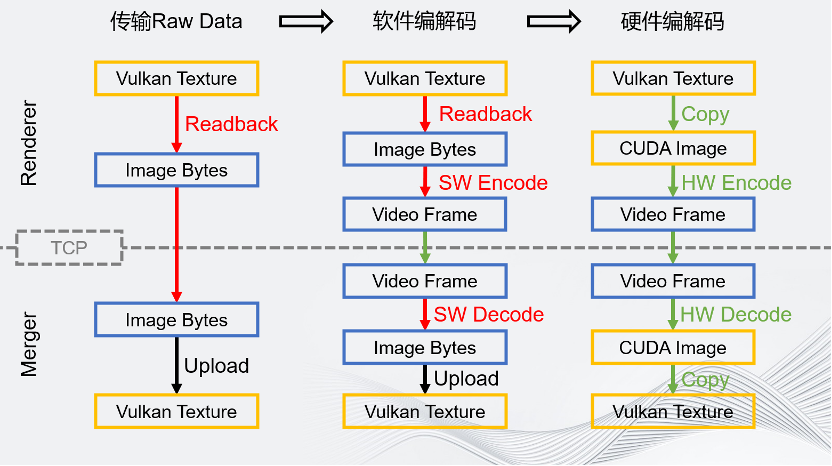
這幾個流程圖展示了Unity一定要硬件編解碼的原因。橙色的框為顯存上的數據,藍色的框為CPU端內存上的數據。
最左邊的流程圖是最簡單的。如果要傳輸一個Raw Data的方案,在GPU上把圖像渲染完成之后,要通過回讀把它讀到CPU端,這是非常耗時的操作。在讀完這個圖像之后,把它通過TCP發送給Merger,占用帶寬非常大,這是不可接受的。
如果引入的是一個軟件編解碼的場景,需要圖像的數據在CPU端存在。所以回讀還是無法避免,操作仍然十分耗時。在軟件編解碼時進行的編碼和解碼操作,同樣非常耗時。雖然這對視頻來說沒問題,但是對于60幀的實時場景是不太能接受的。但是這個方案的帶寬其實優化了很多,因為視頻碼率至少比4 Gbps、1.5 Gbps好很多。這是軟件面板的情況,它最多只是優化了帶寬。
最后是硬件編解碼。硬件編解碼是在渲染完成之后,通過顯存間的拷貝,把渲染的結果拷貝到Media的CUDA端,然后做硬件編碼和硬件解碼。雖然是一次拷貝,但是因為是在一張顯卡的顯存上,所以拷貝過程非常快。硬件編碼完成之后,視頻幀數據會自動回到CPU端。雖然其本質上也是一次回讀,但是它和流水線無關,相當于是在另一條線上完成的,所以這個回讀消耗的只有從PCIE到CPU到內存的帶寬的速度,回讀的不是一個完整的圖像,而是壓縮好的視頻幀,它的數據量也大大減小,所以回讀非常快。之后通過TCP發送視頻幀,帶寬非常小,在Merger端解碼上傳的Buffer也比原來小,解碼也很快。最后把解碼完成后的Image,Copy 到Vulkan Texture,這也是在同一塊GPU內顯存里的操作。
可以看到,硬件編解碼的流程優化了很多,每一步都能得到很高的提升。

介紹一下Unity是怎樣配置FFmpeg的CodecContext的。Unity使用了兩個CodecContext,Video Context是真正用來做視頻編解碼的Context,它是一個TYPE CUDA的Hwdevice。第二個CodecContext用的是Vulkan的Context,這個Context的作用是
和Unity的Vulkan Context進行交互,所以在初始化時不會使用到它默認的API,而是從Unity的Vulkan Instance里面取出了所有必要的信息,把它交給FFmpeg的Vulkan Context,最后通過這種方式,就可以讓FFmpeg的環境和Unity的環境存在于同一個Vulkan的運行環境中。

Video Context做初始化時,沒有用到它默認的Hwdevice Context create的API,用到的是create derived的API。這個API需要傳入另一個Hwdevice Context,它能保證做初始化時和另一個Hwdevice Context使用的是同一個物理GPU,這樣才能真正地做顯存間拷貝。這里選取的邊界碼的格式是H.264,8 bit,NV 12。 為什么要選用這個格式呢?其實是受硬件限制,因為目前NVIDIA硬件不支持10 bit的H.264的解碼。H.265則耗時較大,不太滿足60幀的需求,所以不得不選取這個格式。同時Unity是Zero Latency的配置,GOP的Size是0,保證視頻每一幀都是Intra Frame。這有兩個好處,一是它的延遲非常低。其次,因為分布式渲染在管理的時候可能會隨機丟棄幀,如果有預測幀則不好丟棄,在全是I幀的情況下可以隨機丟棄。
-05-
畫質與性能優化
接下介紹Unity在畫質方面和性能方面對插件進行的一些優化。

首先是Tone-Mapping。Unity之所以這樣做是因為遇到了Color-Banding問題,這個問題由兩個因素導致:
首先,傳輸的圖像不是一個普通的SDR圖像,而是HDR圖像;
其次,選取的格式只有8 bit,它導致了顏色精度和范圍都是受限的。
為了理解為什么Unity傳輸的是HDR圖像,我給大家簡單介紹一下渲染里面的一幀是怎么生成的。圖示為簡化的渲染過程,真正的渲染過程要比這復雜很多。
渲染過程可以簡單分為三部分:
第一個部分叫Pre-Pass,它的作用是生成后續渲染階段所需要的Buffer,在這一階段里會預先生成Depth,即預先生成深度緩沖。深度緩沖預先生成最主要的好處就是可以減少Over-Draw,很多被遮擋的物體直接被剔除掉,后續步驟中就可以不用畫。
第二步是渲染中最主要的一個步驟,我把它叫做Lighting Pass,主要的作用是計算光照,生成物體的最終顏色。這種Pass的實現方式有很多種,例如前向渲染、延遲渲染等。無論是使用哪種實現方式,它的最終目的都是生成一張Color Buffer,即顏色數據。
最后一個步驟一般成為后處理Post-Processing。這個步驟的主要作用是對輸出的Color Buffer進行圖像處理。經過Post-Processing產生的圖像,顏色比單純的Color Buffer自然很多。Post-Processing里面的效果大部分都是屏幕空間效果,例如要做一個輝光的效果,畫面中有一盞燈非常亮,在它的邊緣會有一些柔和的光效溢出,這個效果基本上就是通過Post-Processing實現的。
屏幕空間效果會有什么問題?在分布式渲染中,渲染任務是被拆分開的,所以真正做渲染的Render的機器,實際上是沒有全屏信息的,它沒有辦法做后處理。
對此Unity的解決方案是將后處理交由Merger進行。Renderer渲染到Color Buffer生成之后,就把Color Buffer傳給Merger,Merger先把這個Color Buffer合起來,再總體做一次后處理。
那么,為什么這一過程中傳的Colour Buffer是HDR的?因為在渲染中,光照模型一般都是物理真實的,所以為了之后做后處理,Colour Buffer本身是HDR的。
如圖所示,這是把Black Point和White Point分成設置成0和1的效果,但是實際上這張圖最高的值可以到90以上。如果是室外的場景,最高值可以到一萬多,所以這張圖的動態范圍是非常高的。
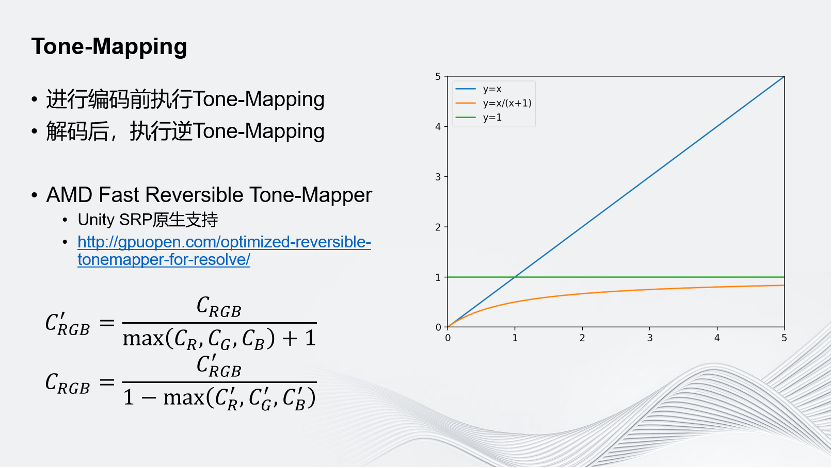
同時,因為傳的是動態很高的HDR圖像,加上使用的是8bit的編碼,所以必須找到一個方法把HDR的Corlor Buffer映射為SDR的Buffer。對于這一映射也有一些要求,其一,它需要可逆;其二,它需要保留更大的表示范圍,并且盡量減少精度損失。
Unity在這方面采用的是AMD提出的Fast Reversible Tone-Mapper,它有許多好處: 首先它是Unity SRP原生支持的,是Unity的可編程的渲染管線;其次它是可逆的,如圖是它的公式;再次,它保留的數字范圍更大,精度損失更小。如圖上這一圖像,y=x可以理解為原始顏色,經過Tone-Mapper處理后,它的取值范圍永遠在0~1之間,同時當它的值越小時,斜率越大,代表它能表示的數字越多,可保留的精度越高。有時在渲染中會遇到顏色值非常高的情況,但這種情況少之又少,更多的還是保留在0~1的范圍區間內。因此Tone-Mapper能夠幫助我們在0~1這個區間范圍內保留更多的精度;最后它非常快,在AMD的GCN架構的顯卡下,MAX RGB會被編譯為一個指令,整個運算中只有3個指令,Max、加法和除法,所以它是非常快的。

如圖,可以對比使用Tone-Mapping前后的效果。最左邊是未經任何處理的原始圖像;中間是不使用任何Tone-Mapping,經過8 bit的編解碼、網絡傳輸,再解碼回來的情況;最右邊是應用了Fast Reversible Tone-Mapping的情況。可以看到里面的背景有很多細節紋理,代表其中高頻的信息比較多。在高頻信息較多的場景下,應用了Fast Reversible Tone-Mapping之后的效果和原始圖像的效果對比,已經看不出什么區別了。
但是如果場景里低頻的信息較多,例如漸變較多,即使運用了Tone-Mapping,也沒有辦法完全解決這個問題。可以看到,原始圖像上的漸變非常柔和,在無Tone-Mapping的情況下,色帶肉眼可見。但是即使引入了Fast Reversible Tone-Mapping,也只能減緩色帶問題,比起原始圖像而言還是差了很多,目前沒有更好的辦法解決這一問題。

Unity對插件進行性能優化的另一個方式是Vulkan同步。因為涉及GPU內部的顯存拷貝,而且它是Vulkan拷貝到CUDA的操作,所以它是一個GPU-GPU的異步操作。異步操作要求開發人員對于操作做好同步,即在編碼時,要保證Unity渲染完成之后才進行編碼,解碼時要保證解碼完成之后,才能把這張圖像Copy給Unity,讓Unity把它顯示在屏幕上。

Unity Vulkan Native Plugin Interface提供了一種同步方式。這里主要關注框出的兩個Flag:
上面的Flush Command Buffer,指在Unity調用自定義渲染事件時,Unity會先把它已經錄制好的渲染指令提交到GPU上,這時GPU就可以開始執行這些指令了。
下面的Sync Worker Threads,指在Unity調用自己定義的Plugin Render Event時,會等待GPU上所有的工作全部完成之后才會調用。

這兩個方式組合起來確實能滿足需求,確實可以做到同步,但是這種方式也打斷了渲染流水線。使用這種同步方式,在調用Plugin Event之前,所有程序要全部停下,等待GPU完成操作。因此這個方式雖然能實現同步,但非常耗時。
如圖展示的就是在這個同步方式下的情況。在簡單的場景下,它耗時5.6毫秒。所以這種方式雖然能同步,但是性能非常差。

Unity只提供了上述的同步方式,因此我們只能轉向Vulkan自帶的同步原語。Timeline Semaphore是Vulkan在1.2版本的SDK里提出的新型的Semaphore,它非常靈活,而且是FFmpeg原生支持的。這里是FFmpeg的Vulkan Context的Frame,它通過Timeline Semaphore同步。在FFmpeg里,它主要被用于GPU-CPU同步,但它也可以用于GPU-GPU同步。
Unity提供的同步方式只有上述兩個Flag,它無法直接使用底層的同步原語,但是它允許我們Hook Vulkan的任何一個API,即在 Hook之后,Unity在調用Vulkan的API時,它其實調用的是我們自己定義的Hook的版本,因此我們使用了Vulkan Hook介入Unity的渲染,在Unity把一幀的渲染提交給GPU之前,通過Hook提交的API,把FFmpeg的Semaphore 塞到提交里面,就可以保證在渲染完成之后會通知Timeline Semaphore,FFmpeg會等Semaphore被通知之后再執行。通過這種方式,這個同步也能達成目的,而且不會打斷渲染流水線。
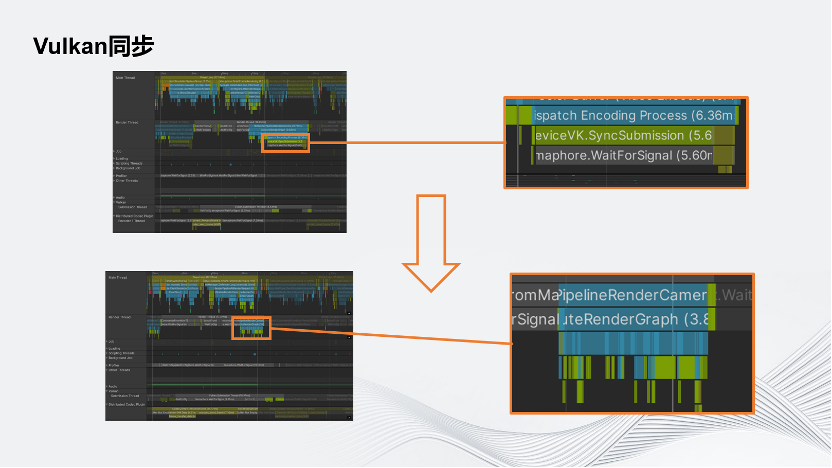
如圖所示,上面為5.6毫秒耗時的情況,下面則完全把這一耗時消除了。因為在這個情況下,不需要在調用Render Event之前就提交渲染指令,而是在GPU上通過Timeline Semaphore和FFmpeg的Command進行同步,因此把這一部分完全省去了。在這個簡單場景中大概有5.6毫秒左右的提升,經過測試,在復雜場景中則會有10~20毫秒不等的提升。
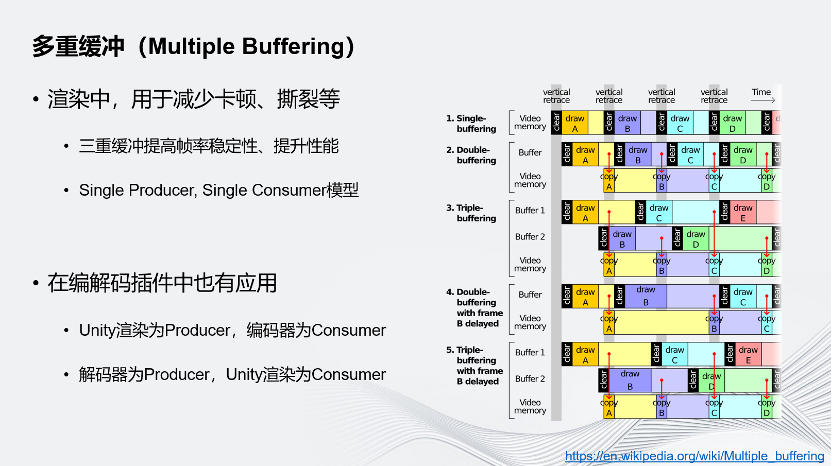
另一個性能優化方案是多重緩沖,這是渲染中非常常用的技巧。在渲染中,常常會用多重緩沖來減少畫面的卡頓、撕裂等情況,三重緩沖還能夠提高幀率的穩定性、提高渲染性能。
多重緩沖的引入會把渲染變成Single Producer, Single Consumer的流水線模型,即渲染流水線。正是因為有多重緩沖,才能形成流水線,讓GPU往一個緩沖中寫入時,CPU可以開始準備下一個緩沖,GPU可以同時往另一緩沖區寫入下一幀數據。
在編解碼的插件中,Unity也引入了多重緩沖來提高性能,使用硬件編解碼代替圖像上屏操作。渲染的圖像沒有顯示在屏幕上,而是通過網絡發走,這是通過多重緩沖的方式實現的,和渲染有同樣的效果。在引入多重緩沖后,Unity的渲染和編解碼器會分別作為Producer和Consumer進行渲染和編解碼的流水線。
-06-
總結與未來展望

在分布式渲染的解決方案中會遇到網絡帶寬和性能問題。
首先,通過引入視頻編解碼可以解決了網絡帶寬的問題,采取硬件編解碼避免GPU-CPU的回讀,避免打斷渲染的流水線。為了實現這個目標,Unity開發了Unity Native Rendering Plugin來對接Unity和FFmpeg底層的Vulkan和NVIDIA Codec 的SDK。
因為選取的編解碼格式,方案中還遇到了色帶問題,因此在方案中我們引入Tone-Mapping優化畫質,通過FFmpeg自帶的Timeline Semaphore,把Unity的渲染指令和FFmpeg的拷貝指令和編解碼指令進行同步,保證編解碼結果正確。
最后,Unity通過引入多重緩沖提升性能,減少幀率不穩的情況。
目前Unity還在探索一些其他的方案。
首先,Unity希望嘗試Vulkan自己推出的Vulkan Vider Extensions。它在2023年1月左右才真正進入Vulkan的SDK,成為一個正式的功能。這個Extension非常新,所以到目前為止Unity還沒有機會進行嘗試,但一直在關注。如果使用這一Extension,就可以完全避免前文所述得到顯存間拷貝、同步等問題。因為這一應用程序沒有引入別的GPU端的運行環境,完全在Vulkan內部運行,因此我們不需要拷貝,直接使用Unity的結果即可。
其次,Unity在對接其他GPU的硬件廠商,嘗試其他硬件編碼。Unity目前正在和一些國產的GPU廠商對接,他們表示他們的硬件編解碼能力會有所提升,支持的格式不再限制于8 bits了。
最后,Unity還希望嘗試一些要使用GPUDirect RDMA、CXL共享內存等特殊硬件的方案。GPUDirect RDMA允許直接把GPU顯存里的東西直接通過網絡發走,能夠減少回讀。CXL共享內存,顧名思義是個共享內存,相當于很多臺機器共享一個遠程的內存池,因此它的帶寬和延遲都是內存級別。這一方案至少允許我們在分布式渲染的環境下不進行視頻編解碼,可以使用Raw Data的方式,把Raw Data存在遠程內存中。
編輯:黃飛



















 工商網監
工商網監
評論