 電子發燒友App
電子發燒友App


1、總述
近年來醫療數據挖掘發展迅速,然而目前醫療數據結構化處于起步階段,更多的醫療數據仍然以自然語言文本形式出現。自然人的學習能力有限,因此學者們嘗試通過自然語言處理(Natural Language Processing,NLP)輔助完成匯總醫學領域知識的過程,將知識提煉出來,提取其中有用的診療信息,最終形成知識本體或者知識網絡,從而為后續的各種文本挖掘任務提供標準和便利。
2、具體應用
2.1 文本挖掘
1)研究背景:生物醫學文本挖掘可以幫助人們從爆炸式增長的生物醫學自然語言文本數據中抽取出特定的事實信息( 主要是生物實體如基因、蛋白質、藥物、疾病之間的關系) ,對整個生物知識網絡的建立、生物體關系的預測、新藥的研制等均具有重要的意義。
2)典型應用及應用方法
2.1.1命名實體識別
1)研究背景
生物命名實體識別,就是從生物醫學文本中識別出指定類型的名稱,比如基因、蛋白質、核糖核酸、脫氧核糖核酸、疾病、細胞、藥物的名稱等。由于生物醫學文獻的規模龐大,各種專有名詞不斷涌現,一個專有名詞往往有很多同義詞,而且普遍存在大量的縮寫詞,人工識別費時費力,因此如何對命名實體進行識別就變得尤為重要。命名實體識別是文本挖掘系統中的一個重要的基礎步驟,命名實體識別的準確程度是其他文本挖掘技術如信息提取或文本分類等的先決條件。
2)典型應用及應用方法
目前,使用比較多的生物命名實體識別的研究方法主要有以下幾種:基于啟發式規則的方法、詞典匹配的方法以及機器學習的方法,如支持向量機(SVM)、最大熵、條件隨機場 (CRF)以及隱馬爾科夫(HMM) 等。
(1)基于啟發式規則的方法
Fukuda等人 最早利用基于規則的系統判定文檔中的蛋白質名稱;Tsuruoka等人 采用啟發式規則以最小化相關術語的歧義性和變化性,實現了術語名稱的標準化進而提高了查找字典的效率。
優點:利用啟發式信息產生識別命名實體的規則可以靈活地定義和擴展
缺點:規則對領域知識的依賴性很強,修改它們需要 該領域專家參與并花費大量時間。 另外,由于命名實體類型多樣,且新類型的命名實體還在不斷涌現,這使得人們很難建立一套一致的規則。
目前,基于規則的方法一般被整合到基于機器學習的方法的后期處理過程中 。
(2)基于字典的方法
最早采用的方法是基于字典的方法,1998年,Proux等人[9]第一次應用英語詞典來識別基因和蛋白質。
優點:簡單且實用。
缺點:新的命名實體不斷出現,并且很多命名實體的長度較長甚至存在變體,難以建立一個完整的的生物醫學命名實體字典。
因此,基于字典的方法通常以字典特征的形式被整合到基于機器學習的方法中[10]。
(3)基于機器學習的方法
基于機器學習的方法是目前主流的方法,它們利用統計方法從大量數據中估算相關參數和特征進而建立識別模型。
優點:客觀、移植性好。
缺點:需要大量的訓練數據且訓練過程相當耗時。
命名實體識別可以看做是詞的分類問題,因此可以采用基于分類的方法如貝葉斯模型和支持向量機[4]等;同時,它也可以看做是序列分析問題(每個詞語作為序列中的一個詞被打上標簽),因此可采用條件隨機域[6]、隱馬爾可夫模型 等基于馬爾可夫的模型。基于機器學習的方法包括特征選擇、分類方法和后期處理等幾個步驟。
2.1.2 關系抽取
1)研究背景
關系抽取( Relationship extraction,RE) 的目標是檢測一對特定類型的實體之間有無預先假設的關系[39]。生物醫學文本挖掘抽取的就是基因、蛋白質、藥物、疾病、治療之間的關系。
2)典型應用及應用方法
主要有基于模版的方式( 手動、自動) 、基于統計的方式和基于自然語言處理的方式。基于自然語言的方法就是把自然語言分解為可從中提取出關系的結構 。Friedman 等人通過提出了GENIES系統,它從生物學文獻中提取和構建關于細胞途徑的信息。
2.1.3 文本分類
1)研究背景
文本分類( Text classification) 就是將文本自動歸 入預先定義好的主題類別中,是有監督的機器學習 方法,主 要應用于自動索引、文本過濾、詞義消歧 ( WSD) 和 Web 文檔分類等。
2)典型應用及應用方法
目前,文本分類的方法有很多,典型且效果較好 的有樸素貝葉斯分類法( Na Bayes) 、K 最近鄰( K - NN) 、支持向量機( SVM) 、決策樹等,還有基于關聯的分類( CBA) 及基于關聯規則的分類( ARC) 。Eskin E[13]使用 SVM 算法和基因序列 kernel 預測蛋白質在細胞質中的位置,達到了 87 % 的查準率和 71% 的 查全率。
2.1.4 文本聚類
1)研究背景
文本聚類( Text clustering) 是根據文本數據的特征將一組對象集合按照相似性歸納為不同類的過 程,與文本分類的區別是分類的對象有類別標記。
2)典型應用及應用方法
常見的聚類算法可歸納為平面劃分法( 如 K - 均值算法、K - 中心點算法) ,層次聚類法( 可分為凝 聚層 次 聚 類 和 分 割 聚 類) ,基 于 密 度 的 方 法 ( 如 DBSCAN 算法) ,基于網格的方法( 如 STING 算法) ,基于 模 型 的 方 法。
Groth P 等 根據顯型的描述,利用文本聚類 將基因聚類成簇,利用這些簇預測基因功能,采用客觀標準選擇一個子類團,從生物過程次本體中預測GO-術語注釋,得到了 72. 6% 的查準率和 16. 7% 的 查全率。
2.1.5 共現分析
1)研究背景
共現( Co-occurrence) 分析主要是對隱性知識的挖掘,在生物醫學領域主要用于諸如 DNA 序列的數據分析、基因功能相似聚類、基因和蛋白質的功能信息提取、提高遠程同源性搜索、基因與確定疾病關系預測等[15]。如果在大規模語料( 訓練語料) 中,兩個詞經常共同出現( 共現) 在同 一窗口單元( 如一定詞語間隔、一句話、一篇文檔等)中,則認為這兩個詞在語義上是相互關聯的。而且, 共現的頻率越高,其相互間的關聯越緊密。
2)典型應用及應用方法
基于共現關系的假定,通過對訓練語料的統計,計算得到詞與詞之間的互信息( Mutual information) ,就可以對詞與詞之間的相關性進行量化比較,獲得對文本詞匯 語義級別的關聯認識。如Pub-Gene系統使用共現方法建立了一個包含基因和基因交互關系的數據庫 ,實驗結果達到了60%的精確率和51%的召回率。當僅考慮5篇或5篇以上文章中的基因對關系時,精確率上升到72%。
2.2 決策支持系統
1)研究背景
在醫學臨床實踐中,對于醫務人員來說,作為一個理智、情感共存的個體,在醫學實踐中難免會犯錯,這導致了醫患雙方關系的緊張、甚至生命健康的負面影響。為了降低出錯的概率以及提高工作效率,臨床決策支持系統應運而生,它可以對醫務人員進行診療方面的指導。
2)典型應用及應用方法
醫療決策支持系統的建立主要分為以下三個步驟:
2.2.1知識庫的建立
詞庫是自然語言處理的基礎,首先應建立詞庫。使用醫學專業詞匯、頻率極高的謂詞、量詞等詞匯、醫療文書詞匯的常用組合及常用語句等,加上基本的語法庫,形成用于醫學語言處理的知識庫。
另外,作為臨床支持系統,還需要建立作為比較條件的知識庫,使患者的各種診療要素形成一定傾向性的結果輸出。
2.2.2語言處理
按照中文自然語言處理的一般步驟,進行分句、分詞、語義分析、形成文本摘要。
? 分句
分為基本單句的分割,和句群的分割。分句主要以基本的標點符號作為分隔符對語言進行計算機子句分割,完成分句處理。中文主要以句號、問號、省略號等為句群結束符,而醫療文書基本上都是陳述句,故多以句號為句群結束符。
? 分詞
目前主流的分詞算法主要有三種,分別為基于字符串匹配的分詞算法、基于理解的分詞算法和基于統計的分詞算法。從詞庫中詞條或習慣搭配短語的最大長度開始,逐漸縮短,對基本分句進行匹配詞庫中的詞條。最后把醫療文書分割為一個個詞匯或短語。
? 語義分析、文本摘要
根據漢語基本語法,對詞匯進行重組,剔除意義不大的部分,形成摘要。以上述病程記錄進行分句、分詞為例:
第一步、分句:句群:今日查房,患者訴頭昏乏力減輕,腹瀉停止,進軟食。 分句:今日查房 患者訴頭昏乏力減輕 腹瀉停止 進軟食
第二步、 分詞: 今日 \ 查房 患者 \ 訴\ 頭昏\ 乏力\ 減輕 腹瀉\停止 進\ 軟食
2.2.3 臨床決策支持系統
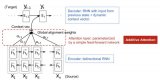
以臨床診療指南、操作規范為參考,在對醫療文書進行語言處理后進行推理、分析,找出其中存在的問題。分析模型是其中的關鍵。如圖1所示,以上述病程記錄為例:依次輸入詞匯、短語。
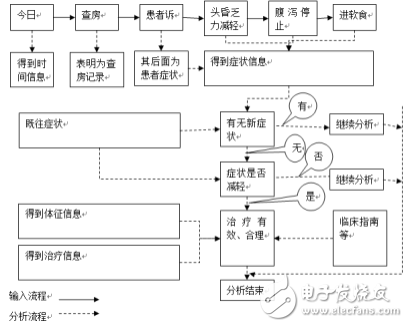
圖1 決策支持系統模型
在分析模型中,比照的是臨床診療指南、操作規范,所以在建立此知識庫時,所用的詞匯、短語應該與語言處理所用的知識庫相對應,否則會增加建立分析模型的難度和復雜性。
2.3 信息提取
1)研究背景
信息抽取(Information Extraction,IE)是指從文本中抽取指定的一類事實信息,形成結構化的數據儲存在數據庫中,以供用戶對信息的查詢或進一步分析利用的過程。 如一位生物醫學科學家要從海量的生物醫學文獻中尋求關于某種疾病的新的治療方案,借助于信息抽取系統抽取出的蛋白質、基因或藥物等的交互關系信息,就有可能從中發現有價值的治療線索或方法。
2)典型應用及應用方法
? 信息抽取技術在電子病歷中的應用
由哥倫比亞大學的Carol Friedman等人設計的MEDLEE系統也是一個很成功的醫學信息抽取系統,作為臨床信息系統(CIS)的一個獨立模塊在紐約長老會醫院使用,它將文本形式的病歷報告轉換成編碼數據以促進乳腺癌研究,有利于病人看護質量的提高 。息抽取技術在電子病歷中的成功,將克服臨床決策支持、臨床路徑管理等前沿醫療信息發展所面臨的諸多瓶頸問題,提升我國醫療信息技術產業的核心競爭力。
? 信息抽取技術在醫學文獻中的應用
國內對生物醫學文獻信息抽取研究相對較多,極大地促進了生物醫學的現代化進程,如從中藥復方的臨床文獻進行復方名稱的抽取 ;利用信息抽取技術從Web形式的中醫藥文獻資料中抽取結構化中醫臨床診療信息的中醫臨床診療垂直搜索系統TCMVSE 。
? 信息抽取技術在生物醫學網絡資源中的應用
針對網絡上分布散亂的生物醫學資源,可以用基于HTML結構的信息抽取方法實現對生物醫學資源的抽取,將其轉換成結構化的數據存儲到數據庫中。
北京中醫藥大學在1989年完成了“中醫方劑信息智能分析支援系統”,收集了對40余萬條方劑信息的解釋,可產生800余萬相關數據,并于1997年得到國家教育部博士點學科專項基金的支持,用Wed_db技術,將方劑數據庫移植到Oracle7for UNIX平臺,在Internet網上實驗性地實現了方劑數據庫的查詢和分析處理 。
2.4 自動問答系統
1)研究背景
隨著大數據時代的到來,對于傳統的信息檢索來說,由于醫學專業的特殊性,面對網絡上質量參差不齊的醫學信息,非醫學專業人員在查找、理解及獲取方面存在諸多困難和障礙。而基于自動問答的醫學信息搜尋模式作為更智能的醫學信息資源獲取工具,不僅對海量數據資源的有效利用具有重大意義,而且在一定程度上可緩解醫患之間信息不對稱、提高醫療資源利用效率,同時能更好地體現“以病人為中心”服務理念的轉變。
2)典型應用及應用方法
2.4.1 基于傳統搜索技術的問答系統
基于傳統搜索技術的問答系統,在問題分析中將問題的關鍵詞和數據資源中的關鍵詞進行匹配,進而獲取可能相關的答案片段。典型的醫學領域自動問答應用具體見表1。

表1 基于傳統檢索技術的自動問答系統相關研究
應用方法如下:
基于傳統搜索技術的問答系統的核心技術包括三個主要組成模塊:問題處理、信息檢索和答案抽取。
2.4.1.1問題處理
(1)問題類型識別
主要有啟發式算法(基于規則的算法)、基于機器學習的算法等。
(2)提取問題關鍵詞
可根據詞語的詞性、tfidf值或對不同重要程度的詞語賦予權重等方法篩選出關鍵詞。
(3)問題關鍵詞拓展?
主要有基于詞典的方法、基于統計的方法和相關反饋的方法。
- 基于詞典的方法可用Wordnet(用于英文問答系統)、Hownet(用于中文問答系統)或其他同義詞詞典來擴展關鍵詞。
- 基于統計的方法需要大量的問題和預料來訓練。每一類問題所對應的答案一般有某種共同的特性,如對于詢問地點的問題,答案中經常會出現“在、位于、地處”等關鍵詞。所以通過統計,我們找到這些詞后就可以把它們加到問句中。
- 相關反饋的方法是用檢索返回的相關文檔對關鍵詞進行擴展。
2.4.1.2 信息檢索
問答系統中的信息檢索模塊利用問題處理模塊輸出的關鍵詞以及其拓展來搜索相關的段落。
主要有基于統計的方法和基于語義的方法。
基于統計的方法主要根據用戶查詢與數據全集中數據的統計量來計算相關性。目前較流行的有:布爾模型、概率模型和向量空間模型。
基于語義的方法是對用戶查詢和數據全集中的數據進行一定程度的語法語義分析,也就是在對用戶查詢和數據全集中的內容進行理解的基礎上進行兩者的相關計算。
2.4.1.3 答案抽取
主要有根據命名實體、推理、上下文的方法。
2.4.2 基于語義技術的問答系統
基于語義技術的問答系統,對自然語言問題進行語義處理,實現從語義層面理解用戶提出的問題。相關的應用研究如表2,但目前相關的應用研究較少。

表2 基于語義技術問答系統相關研究
應用方法如下:
基于語義技術的問答系統在基于傳統搜索技術的問答系統的基礎上,可在問題處理模塊和答案抽取模塊加入對句子的結構進行分析(即句法分析)的方法。
在問題處理模塊里需要通過對問句結構進行分析,根據問句的結構確定問句的類型,同時抽取句子關鍵詞。
在答案抽取階段,可對答案的候選句子進行結構分析,進行句子相似度的計算,去除重復或相近的候選答案,最后根據問題類型抽取出答案實體。
2.5 醫學影像的信息提取和分析
1)研究背景
醫學影像報告是電子健康病歷 (electronic health record,EHR)中包含大量數字信息的重要組成部分。醫學影像中使用NLP的總體目標是挖掘診斷報告中結構化信息,并將其應用于臨床診治過程。
2)典型應用及應用方法
根據信息提取的對象和目的不同,NLP可用于患者個體信息分析、患者群體信息分析和醫學影像流程信息分析等。
1. 患者個體影像診斷信息提取和分析,對患者個體疾病處理提供幫助
(1)提示“危急發現(critical findings)”:NLP檢出影像報告中描述的、可能導致嚴重后果的影像征象,提醒處理該患者的醫師注意。目前NLP可提示的危急情況有闌尾炎、急性肺損傷、肺炎、血栓栓塞性疾病及各類潛在惡性病變等 。
(2)提示隨訪建議:NLP檢出報告中應提示臨床進行后續操作的內容,自動生成隨訪建議,提示后續檢查或治療 。
2. 患者群體影像診斷信息提取和分析,構建患者隊列,用于流行病學研究、行政管理等
(1)流行病學研究隊列的構建:使用NLP可高效率地分析大數量、患者群體的影像報告,得到群體的特征性數據,從而提高流行病學研究效率,為循證影像醫學研究提供幫助。
3. 醫學影像流程信息的提取和分析,用于醫學影像報告質量評價和改進
(1)報告質量評價和報告規范的建立:NLP可識別醫學影像學的流程和質量指標,判斷影像報告是否符合相關指南或診斷規則 。同時可用于評價報告的完整性和規范,是否給出正確的建議,是否及時進行危急情況的預警,報告信息是否用于疾病的診斷等方面 。
(2)影像檢查全流程的改進:NLP可對各類影像的綜合信息進行分析,將報告中的檢查結果和建議等信息與全面的臨床信息相互關聯,如檢查適應證、疾病種類、患者年齡、性別、申請 科室、申請醫師及患者類型(住院或門診)等。這種大規模的數據分析在經過驗證后,可得到預測模型,形成適合本地情況的臨床決策支持系統(clinical decision support system,CDSS),應可應用到計算機醫囑系統(computerized physician order entry,CPOE)中去。













 工商網監
工商網監
評論