倍頻程均衡器
2009-09-25 15:32:21 829
829 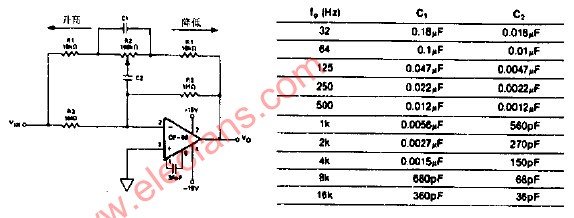
今天我們來深度揭秘一下負載均衡器 LVS 的秘密,相信大家看了你管這破玩意兒叫負載均衡?這篇文章后,還是有不少疑問,比如 LVS 看起來只有類似路由器的轉發功能,為啥說它是四層(傳輸層)負載均衡器呢,今天我們就來逐漸揭開 LVS 的迷霧,本文將會用圖解的方式淺入深地探討 LVS 的工作機制
2024-01-04 12:26:33415 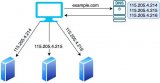
音頻均衡器是一種可以分別調節各種頻率成分電信號放大量的電子設備。它通過對各種不同頻率的電信號的調節來補償揚聲器和聲場的缺陷,修飾和增強各種聲源的效果,以及進行其他特殊作用。在音響器材中,音頻均衡器通常用于調節音頻信號的頻率分布,使得音頻在各種頻段上達到均衡的效果。
2024-02-06 14:58:511616 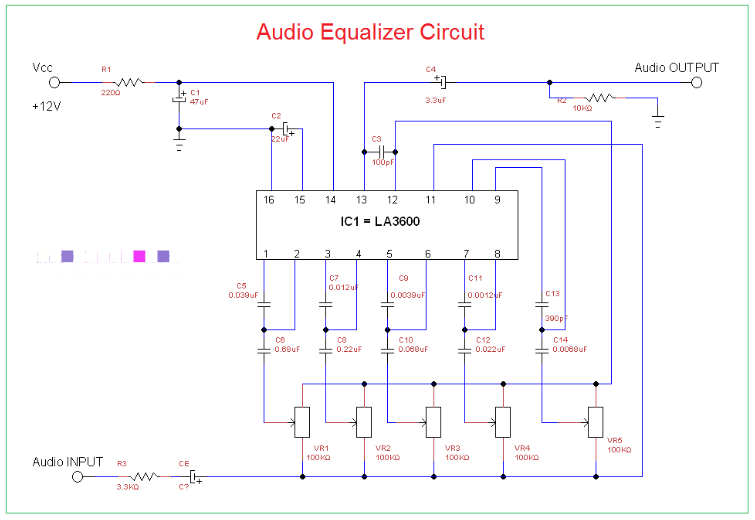
圖形均衡器是一種可以直觀地調整各個頻段增益的音頻處理設備。與參數均衡器不同,圖形均衡器采用固定的頻段和Q值(即頻段的寬度),用戶可以直接通過拖拽按鈕來調整每個頻段的增益,從而實現對音頻信號的頻率分布進行修飾和增強。
2024-02-06 15:13:122431 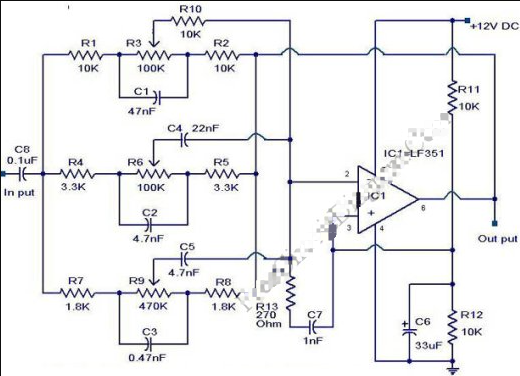
均衡器的基本原理是什么?
2021-05-20 06:45:44
高速移動下OFDM均衡器的FPGA實現
2012-08-17 10:48:23
我聽到有些人說,"所有的均衡器聽起來都一樣";或者保守的表示:"所有的數字均衡器聽起來都一樣"。如果你認識的人曾經說過這種話,請讓他們到Audified網站
2021-05-10 19:58:04
Antares在今年6月發布了這款均衡器,起初一直是Auto-Tune Unlimited訂閱版的一部分,現在推出了永久版授權。廠家宣稱在2022年9月6號-10月6號限時銷售永久版,零售價格為
2022-09-11 08:29:42
闡述和圖標等,此處不贅述了。不過通篇論文只在關注其幅頻響應,沒有關注到相頻響應。這幾年來,陸續有人開始關注EQ均衡器的線性相位方法實現。最直接的手段就是FIR濾波器。不過FIR濾波器也存在缺陷,不光是其
2019-02-20 06:35:22
本帖最后由 射頻技術 于 2020-2-13 16:41 編輯
M23544電纜均衡器產品介紹M23544報價M23544代理M23544M23544現貨, M23544是一種多速率、高集成度
2018-09-10 09:56:30
`MEQ10-50AU無源MMIC均衡器是補償RF /微波和高速數字系統中低通濾波效果的理想解決方案。該均衡器可提供從DC到50 GHz的正斜率,其DC衰減值為10dB,并且在整個工作范圍內都保持
2021-03-29 14:33:18
您調整參數,結果立即反映在模擬中。例如,在模擬運行時將“Center Frequency1”的滑塊向右移動會增加第一個參數均衡器雙二階濾波器的中心頻率。您可以通過在幅度響應圖中立即注意到更改來驗證這一點。
2018-07-28 13:37:52
關于視頻均衡器1.什么是靜音輸出,有什么作用?2.什么是旁路均衡,有什么作用?3.什么是直流恢復,有什么作用?4.什么是載波檢測,有什么作用?
2019-08-20 09:37:46
在移動通信和高速無線數據通信中,多徑效應和信道帶寬的有限性以及信道特性的不完善性導致數據傳輸時不可避免的產生碼間干擾,成為影響通信質量的主要因素,而信道的均衡技術可以消除碼間干擾和噪聲,并減少誤碼率。其中判決反饋均衡器(DFE)是一種非常有效且應用廣泛得對付多徑干擾得措施。
2019-08-28 06:07:31
使用LT1256運算放大器的可調節視頻電纜均衡器電路。基于LT1256視頻推子的電壓控制電纜均衡器。該電路具有易于調整,簡單和遠程控制的能力
2020-06-09 13:06:25
急急急,哪位大神有音樂均衡器的設計啊,虛擬儀器的大作業,下周就要交了,還要寫PPT上去講。。。。
2016-11-01 13:52:34
什么是時變信道中OFDM系統均衡器?均衡器算法的FPGA實現
2021-04-29 07:29:45
自適應電纜均衡器是什么?自適應均衡器設計面臨哪些技術挑戰?如何提高自適應均衡器的性能?
2021-05-18 06:04:25
針對高速無線數據通訊的實時性要求,提出采用FPGA來實現可配置均衡器的設計,在設計過程中采用自頂而下劃分的設計方式,即方便了設計的需要,同時又滿足了性能的要求,在實際項目中收到很好的效果。
2021-04-29 06:48:32
差分隊是啥?均衡器如何能解決插入損耗所帶來的問題
2021-05-19 06:03:18
我想制作一款數字均衡器,有這方面專家能幫到我嗎?我只有想法,想有專業人士幫我實現夢想
2019-09-10 13:34:41
機械調控和數控均衡器 &
2008-09-17 09:04:33
求大神介紹一種基于FPGA的高速通信系統,通過電纜驅動器和接收均衡器,拓展了LVDS信號的傳輸距離。
2021-04-30 06:50:19
則是 DS32EV100,即所謂的可編程單一均衡器。這兩類均衡器之間有什么區別,是否能用一種均衡器替換另一種?下面我來說明一下。在通過傳輸介質(線纜或 PCB 線跡)發送信號時,存在兩種類型的損耗
2018-09-19 14:48:48
音樂均衡器EQ如何調試看了就知道
2020-11-06 06:02:15
牽涉到對三段均衡器特性的認識,在一般的調音臺上中頻參量均衡器是一個高Q值、窄頻帶的帶通濾波器,它是一個峰值頻率特性曲線,頻帶很窄,但是頻率可以左右移動。與這個掃頻旋鈕配合使用的是一個提升和衰減旋鈕,而
2016-03-23 15:00:10
用MATLAB仿真遞推最小二乘算法自適應均衡器 (用代碼實現) 另外能用simulink模塊構建的話是最好不過了小弟在此謝謝了
2012-04-07 00:03:20
無線通信中,信號在非理想信道傳輸時總是存在失真,具體表現為碼間干擾[1,2]。為降低干擾,通常在接收端采用自適應均衡器進行失真補償。自適應均衡器一般由橫向濾波器組成,這是自適應均衡器中最易實現的形式,也是實際應用比較廣泛的一種方法[3-5]。
2020-03-06 08:30:33
采用BA3822集成的五點立體聲圖形均衡器電路可以設計出非常簡單高效的立體聲圖形均衡器。
BA3822五點立體聲圖形均衡器電路有兩個通道,每個通道的五個中心頻率使用外部電容器獨立設置
2023-08-31 18:24:26
鈺泰ETA3000電池均衡器IC ETA3000是電池平衡ic,一個ic是兩節的,可以通過級聯,實現3節,4節,5節等等的電池組的平衡,而且是主動平衡的,平衡電流可以達到2A是一種基于ETA是專利待
2019-12-04 19:58:35
求助~~~~怎樣用labview設計出一個音樂均衡器!!!
2013-04-30 17:30:17
本文簡述了判決反饋均衡器的基本原理和實現方式,為滿足實現均衡器的可配置需要,專門針對判決反饋均衡器的復雜結構,提出一種采用自下而上的模塊化設計方法,對系統的各個
2009-11-30 16:16:55 13
13 MAFL-011128-DIE均衡器,12 dB 20 GHzMAFL-011128 均衡器是寬帶匹配的,具有出色的功率處理能力。在可焊線芯片中提供一流的射頻性能。 特征12 分貝均衡器寬帶:20 GHz低插入損耗:
2023-04-23 14:06:28
MAFL-011127-DIE均衡器,9 dB 20 GHzMAFL-011127 均衡器是寬帶匹配的,具有出色的功率處理能力。在可焊線芯片中提供一流的射頻性能。 特征9 分貝均衡器寬帶:20 GHz低插入損耗:
2023-04-23 14:08:26
MAFL-011126-DIE均衡器,6 dB 20 GHzMAFL-011126 均衡器是寬帶匹配的,具有出色的功率處理能力。在可焊線芯片中提供一流的射頻性能。 特征6 分貝均衡器寬帶:20 GHz低插入損耗:
2023-04-23 14:10:13
適合補償射頻/微波和高速數字系統中的低通濾波效應。它提供從 DC 到 7 GHz 的正斜率,整個頻帶衰減 6 dB。MMIC 均衡器具有獨特的設計,可提供出色的回波
2023-05-12 14:04:41
/微波和高速數字系統中的低通濾波效應。它提供從 DC 到 7 GHz 的正斜率,整個頻帶衰減 3 dB。MMIC 均衡器具有獨特的設計,可提供出色的回波損耗。它采用
2023-05-12 14:19:09
基于濾波多音調制系統的輔助判決均衡器:提出的輔助判決均衡器在用于濾波多音調制系統時,可克服判決反饋均衡器在多徑信道下的地板效應.同時結合因子圖理論給出了輔助判決
2010-03-18 16:15:3417 摘要:針對單載波頻域均衡系統MMSE均衡器存在殘留碼間干擾的缺點,提出MMSE-RISIC判決反饋均衡器消除殘留碼間干擾。MMSE-RISIC均衡器采用傳統MMSE均衡后的判決數據,對殘留碼間干擾
2010-05-30 08:50:2322 Qorvo QPC7334可變均衡器Qorvo QPC7334可變均衡器是高線性度均衡器,工作頻率帶寬范圍為5MHz至684MHz。這些均衡器具有低功耗、16dB斜率范圍和低插入損耗。QPC7334
2024-02-26 19:11:26
Qorvo QPC7335可變均衡器Qorvo QPC7335可變均衡器是高線性度均衡器,工作頻率帶寬范圍為45MHz至1002MHz。這些均衡器具有低功耗、18dB斜率和低插入損耗。QPC7335
2024-02-26 19:12:33
重要參數 增益均衡器,高性能,DC-40GHzAPITech Inmet品牌增益均衡器為您的系統斜坡問題提供簡單的解決方案。可以構建負、正或拋物線斜率單元,以滿足您在DC-40GHz頻率
2024-03-20 20:25:15
本文利用模糊系統,針對非線性信道,結合恒模均衡算法和遞推最tJ、--乘算法設計半盲均衡器.與一般均衡算法比較,結合模糊系統特性的新算法具有高的準確率和更快速的
2010-09-11 16:29:2113 均衡器電路(五段)
2008-01-19 10:30:5113332 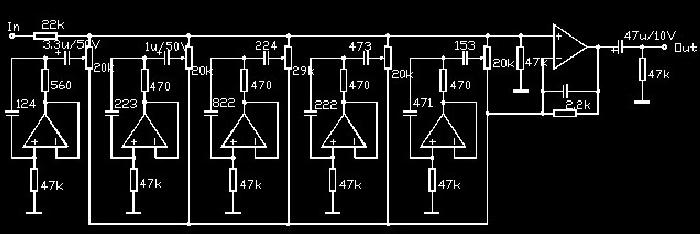
由跨導運放和普通運放共同構成的壓控均衡器
2008-02-25 23:15:181203 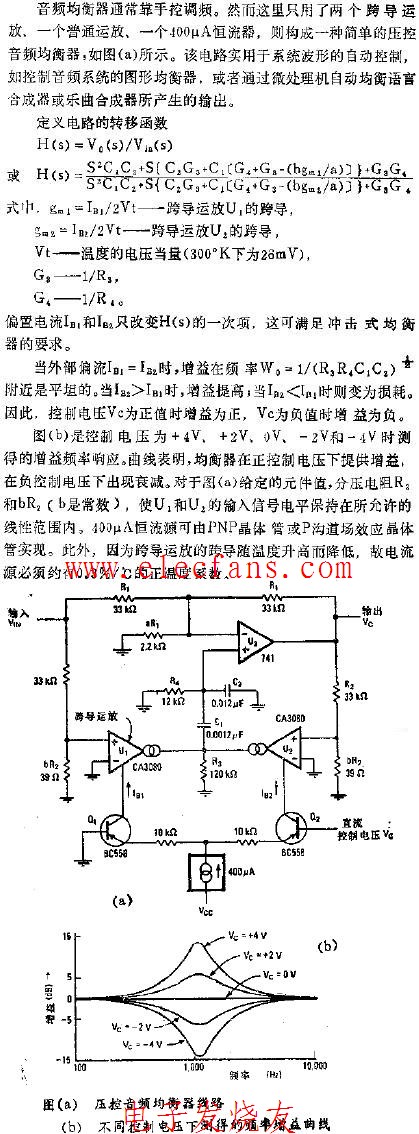
延時線輸出振幅均衡器電路圖
2009-06-25 11:43:38489 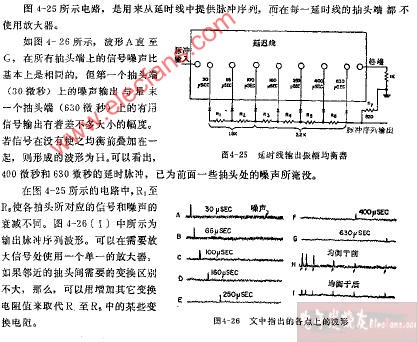
頻率均衡器的調控技巧
均衡器(EQUALSER)是對聲信號頻率響應反應及振幅進行調整的電聲處理設備。它可以改變聲與諧波的成份比、
2009-12-12 10:09:173195 均衡器的使用誤區
均衡器的全稱是房間均衡器。在音響系統中有廣泛的應用,但大多數場合,它并沒有發揮應有的作用。現舉例說明
2009-12-12 10:10:311765 均衡器的調整方法
超低音:20Hz-40Hz,適當時聲音強而有力。能控制雷聲、低音鼓、管風琴和貝司的聲音。過度提升會使音樂變得混濁
2009-12-12 10:14:176783 5波段圖形均衡器 (5-Band Graphic Equalizer)
2009-12-26 13:01:524517 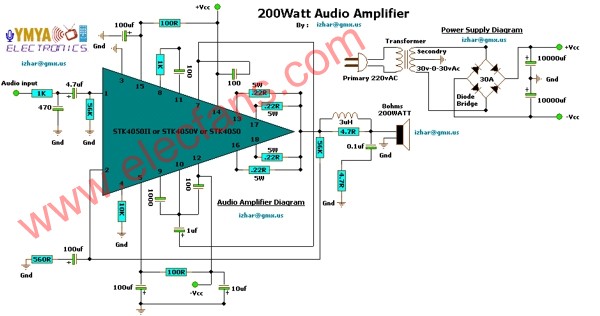
MAX3987 8.5Gbps四通道均衡器和預加重驅動器
MAX3987是4通道接收和發送均衡器(EQ),用于補償FR4帶狀線/微帶線和/或高速電纜中的傳輸介質損耗。器件可以
2010-01-15 15:35:171102 什么是均衡器 均衡器簡介
均衡器是一種可以分別調節各種頻率成分電信號放大量的電子設備,通過對各種不同頻率的電信號的調節來補償揚聲器和
2010-02-05 17:52:392737 功率均衡器,功率均衡器原理是什么?
熔融拉錐型光纖耦合器和PLC(平面光波導)光功率分配器近年來已獲得長足發展。但無論光纖型或波導型器件現
2010-04-02 16:28:242119 均衡器
通信系統中傳輸的信號都是由許多不同頻率的正弦分量組成的,并且它們的幅度或相們之間具有確定的關系。為保證傳輸信號的質量,要求在傳輸過
2010-04-15 16:48:318316 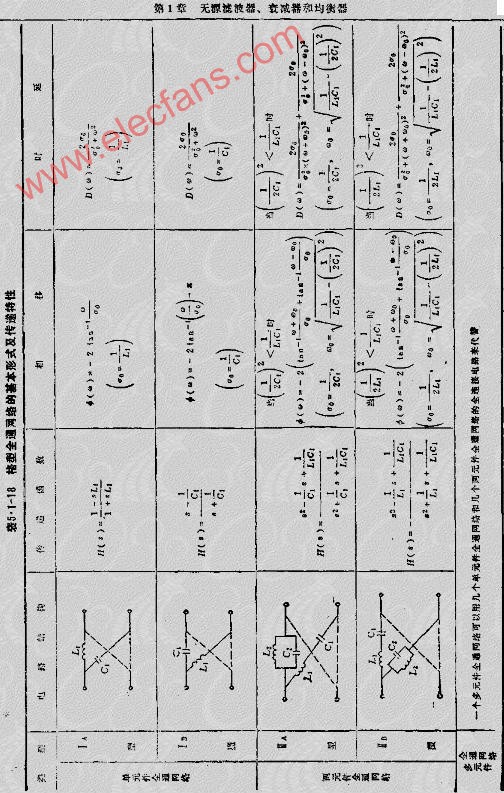
調音臺之信號處理設備之均衡器和激勵器詳解
均衡器和
2010-04-19 15:07:094710 數字電視地面傳輸中單載波均衡器的FPGA設計與實現
2011-10-09 17:49:450 無線信道仿真和均衡器的FPGA設計與實現
2011-10-09 18:11:3740 在分析傳統線性均衡器的基礎上, 提出了一種基于Harr 小波的均衡器結構, 并用一組小波來表示均衡器. 之后, 給出了自適應算法, 并對算法性能做了分析.理論分析與實驗結果表明, 與傳統
2011-11-25 13:40:2526 一種新型6_25Gb_sCTLE均衡器的設計_蘇鵬洲
2017-01-07 22:23:130 均衡器在高速數字傳輸系統當中扮演了關鍵角色。均衡器可以分為兩類:放在發送端的De-emphasis,放在接收端的CTLE,FFE以及DFE。 我們將會介紹均衡器的工作原理以及如何正確的設置均衡器,以達到優化高速數字傳輸系統的目的。
2017-09-01 15:40:1734 均衡器(Equalizer),是一種可以分別調節各種頻率成分電信號放大量的電子設備,通過對各種不同頻率的電信號的調節來補償揚聲器和聲場的缺陷,補償和修飾各種聲源及其它特殊作用,一般調音臺上的均衡器
2017-09-20 19:12:451 使用FPGA芯片和Verilog HDL設計實現了自適應均衡器并仿真驗證了新方法的有效性。 信道均衡技術(Channel equalization)是指為了提高衰落信道中的通信系統的傳輸性能而采取的一種抗衰落措施。它主要是減小信道的多徑時延帶來的碼間串擾
2017-10-26 10:24:5813 自適應電纜均衡器是串行數字視頻(SDV)廣播和串行電信設備接收器前端的基本組成部分,它們還可以用于其它類型的有線通信系統。均衡器直接與傳輸線接口,恢復由電纜造成信號幅度及帶寬的損耗。由于均衡器直接
2017-11-14 11:29:310 基于System Generator軟件,在xc7z020-1clg484芯片上設計了一種高速盲均衡器。該盲均衡器由延遲模塊、濾波模塊、誤差計算模塊和系數更新模塊構成,采用MCMA算法,使用并行
2017-11-18 05:06:011880 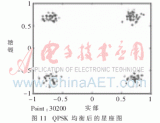
均衡器,是一種可以分別調節各種頻率成分電信號放大量的電子設備,通過對各種不同頻率的電信號的調節來補償揚聲器和聲場的缺陷,補償和修飾各種聲源及其它特殊作用,一般調音臺上的均衡器僅能對高頻、中頻、低頻三段頻率電信號分別進行調節。
2017-12-20 10:00:41272045 均衡器的全稱是房間均衡器。在音響系統中有廣泛的應用,但大多數場合,它并沒有發揮應有的作用。是一種可以分別調節各種頻率成分電信號放大量的電子設備,通過對各種不同頻率的電信號的調節來補償揚聲器和聲場的缺陷,補償和修飾各種聲源及其它特殊作用
2017-12-20 10:27:1974684 使用myDAQ制作一個音頻均衡器,labVIEW,DAQ助手
2017-12-22 15:07:1355 經常聽到技術提到負載均衡這個詞,還有F5、F5負載均衡等之類的,從網上找了點資料做個知識普及,希望能幫到想了解這方面知識的朋友。負載均衡和F5是什么呢?f5負載均衡器有什么主要功能?f5負載均衡器是如何配置的,下面一起來看看。
2017-12-29 11:25:1034669 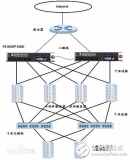
短波信道具有多徑、衰落和時變特性,在均衡過程中,線性均衡器收斂速度慢、收斂精度低,而分數間隔均衡器具有更好的均衡效果。為此,根據短波猝發通信中使用的波形結構,針對短波信道的特點,提出基于最小均方誤差
2018-03-20 10:45:361 本文首先介紹了四款電腦均衡器軟件,分別是電腦均衡器V2.0 綠色版、均衡器學習軟件 V1.0 綠色版、電腦均衡器 2.0 官方最新版以及電腦均衡器V2.1 免費多語安裝版,其次闡述了電腦均衡器怎么設置才好聽的步驟教程,具體的跟隨小編一起來了解一下。
2018-05-24 10:41:4978782 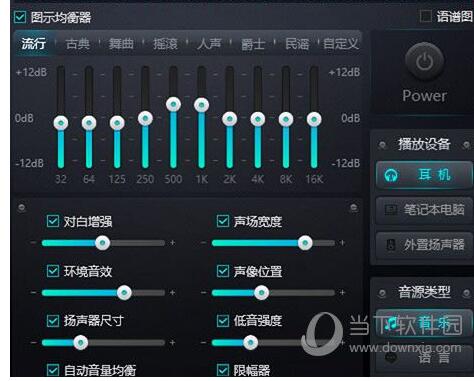
本文介紹了均衡器的作用及各頻段音色特點,其次介紹了均衡器頻率的特性與補償聲音的特點,另外還介紹了激勵器作用與激勵器補償聲音的特點。
2018-05-24 11:19:218836 本文首先解答了均衡器數字代表的是什么,其次闡述了均衡器的調整方法,分別從平衡悅耳的聲音以及頻率的音感特征方面來詳細介紹的,具體的跟隨小編一起來了解一下。
2018-05-24 14:21:5146653 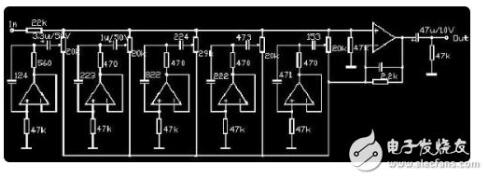
本文首先介紹了電視聲音均衡器調節方法,其次闡述了聲音均衡器調整方法,最后介紹了聲音均衡器調整注意事項,具體的跟隨小編一起來了解一下。
2018-05-24 15:11:46101365 本文首先闡述了激勵器和均衡器之間的區別,其次介紹了激勵器工作原理及作用,最后介紹了均衡器原理與作用。
2018-05-29 10:10:4919438 在高速移動下,OFDM系統載波閫正交性被破壞,出現裁波問干擾(ICI),嚴重影響系統性能,必須采用適當的均衡技術以補償ICI。為了保證通信的有效性和實時性要求,使用FPGA實現了一種低復雜度的最小
2021-01-27 15:52:0011 速度的提高.為此,筆者從LMS算法中的梯度運算出發,解決了誤差與均衡器輸入向量之間的時序對應關系的協調,從而提出了一種適合于FPGA實現的高速判決反饋均衡器結構,最后給出了在FPGA上的具體實現結果,其表明了該算法對于提高判決
2021-02-05 17:00:0113 多波段圖形均衡器-下載生產代碼
2021-06-05 20:25:555 具有能夠跟蹤信道變化從而自動調節抽頭系數的能力,因此成為通信系統中一項重要技術。本
研究以FPGA 為設計平臺,以Verilog 為編程語言,研究并實現了基于LMS 算法的自適應均衡器。
2022-05-27 16:18:4110 增益均衡器(gain equalizer),簡單理解,就是調節工作頻帶內增益平坦度的器件。當我們的設計的系統,增益平坦度達不到要求的時候,經常會用到這種電路。
2022-11-25 13:59:251035 電子發燒友網站提供《Aduino均衡器開源分享.zip》資料免費下載
2022-12-01 09:37:270 在這篇文章中,我們討論了一個參數均衡器電路,它可用于將音樂輸出增強到出色的水平,比任何標準的圖形均衡器輸出都要好得多。
2023-03-19 10:42:571874 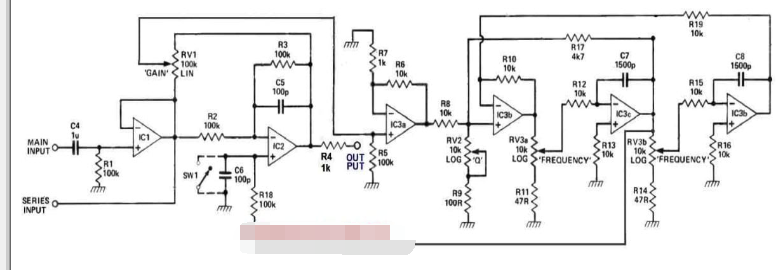
均衡器(Equalizer),是一種可以分別調節各種頻率成分電信號放大量的電子設備,通過對各種不同頻率的電信號的調節來補
償揚聲器和聲場的缺陷,補償和修飾各種聲源及其它特殊作用,一般調音臺
2023-05-30 10:32:370 minicircuits射頻均衡器TAT-4R8DC-1+
2021-11-12 11:25:181808 
minicircuits射頻均衡器TAT-10R5DC-1+
2021-11-12 11:31:001055 
電子發燒友網站提供《基于FPGA的自適應均衡器的研究與設計.pdf》資料免費下載
2023-11-07 10:33:281 Channel怎么來匹配?發射端均衡器和接收端均衡器有怎么樣的玩法? 匹配是指在通信系統中,發射端和接收端之間的信號傳遞路徑之間的適配。在數字通信系統中,匹配是非常重要的,它可以最大限度地提高信號
2023-11-07 10:26:09228 均衡器是一種用于調節音頻頻譜的設備,它可以增強或削弱特定頻率范圍內的聲音。
2023-12-29 18:06:36636
正在加载...
 電子發燒友App
電子發燒友App



 為N點快速傅里葉逆變換矩陣;,n(i)為信道噪聲矢量,定義方差是σ2的高斯白噪聲(AWGN);H(i)是一個N×N的時域轉移矩陣,其元素為
為N點快速傅里葉逆變換矩陣;,n(i)為信道噪聲矢量,定義方差是σ2的高斯白噪聲(AWGN);H(i)是一個N×N的時域轉移矩陣,其元素為
 。進行下一組運算,CIR是該算法的核心,即矩陣迭代求逆的運算,CPE模塊是一個簡單的矩陣運算模塊完成
。進行下一組運算,CIR是該算法的核心,即矩陣迭代求逆的運算,CPE模塊是一個簡單的矩陣運算模塊完成 的運算。
的運算。
 ,采用迭代的方法計算出
,采用迭代的方法計算出 ,用FPGA實現這個模塊的端口如圖3所示。
,用FPGA實現這個模塊的端口如圖3所示。
 后,只有trag被置為高電平才會進行下一次運算。取Q=2時,
后,只有trag被置為高電平才會進行下一次運算。取Q=2時,











 工商網監
工商網監
評論