 電子發(fā)燒友App
電子發(fā)燒友App


? 自20世紀80年代以來,語音識別技術(shù)的研究取得了許多突破性進展,特別是基于隱馬爾可夫模型(HMM)的語音識別技術(shù),目前已趨成熟,成為語音識別的主流。然而基本型的HMM模型也存在一些固有缺陷,這些缺陷除體現(xiàn)在狀態(tài)的持續(xù)時間沒有直接在模型參數(shù)中反映出來外,還表現(xiàn)在:
(1)采用狀態(tài)輸出獨立假設,每個時刻的輸出僅與所處的狀態(tài)有關(guān),而與以前的輸出沒有關(guān)系,然而實際語音信號卻有很強的時間相關(guān)性,這就影響了HMM模型描述語音信號幀間相關(guān)性的能力。
(2)連續(xù)HMM模型假定狀態(tài)輸出概率密度函數(shù)為混合高斯分布函數(shù),而實際的語音信號分布是非常復雜的,很難用簡單的高斯分布的組合形式來表征。為了彌補這些缺陷,許多改進的方法被提出來。
語音識別技術(shù)是近年來高速發(fā)展的一項技術(shù),由于其重要的理論價值與廣闊的應用前景,受到人們的廣泛重視。語音是一個復雜的非線性過程,基于線性系統(tǒng)理論的語音識別方法的局限性越來越凸顯。近年來,隨著人工神經(jīng)網(wǎng)絡、模糊邏輯、粒子群優(yōu)化算法等非線性理論研究和應用的逐漸深入,這些理論已經(jīng)開始獨立或者相互交叉應用到語音識別領(lǐng)域中。
語言是人類獲取信息的主要來源之一,不僅是人類與外界交流信息最方便、最有效、最自然的手段,而且也是人與機器之間進行通信的重要工具。無論是人與人之間還是人與之間的語言通信,語音信號處理,特別是語音信號數(shù)字處理,都具有特別重要的作用。
隨著計算機技術(shù)的快速發(fā)展,用現(xiàn)代手段研究語音信號處理技術(shù),使得人們能更加有效的產(chǎn)生、傳輸、存儲和獲得語音信息,這對于促進社會的發(fā)展具有十分重要的意義
數(shù)字語音信號處理,包括三方面內(nèi)容,即語音信號的數(shù)字表示法,語音信號數(shù)字處理理論的各種方法和技術(shù)及數(shù)字語音處理理論和技術(shù)在各領(lǐng)域中的實際應用。
模糊神經(jīng)網(wǎng)絡在語音識別中的應用
神經(jīng)網(wǎng)絡是在現(xiàn)代科學研究成果的基礎上提出來模擬人腦結(jié)構(gòu)機制的一門新興科學,它不是人腦真實的全面描述,而是這類生物神經(jīng)網(wǎng)絡的抽象、模擬和簡化,其目的在于探索人腦的信息加工、存儲和搜索機制,從而為人工智能和信息處理等學科的研究開辟新途徑。人工神經(jīng)網(wǎng)絡就是采用物理可實現(xiàn)的系統(tǒng)來模擬人腦神經(jīng)細胞的結(jié)構(gòu)和功能的系統(tǒng)。它是由很多處理單元有機地連接起來進行并行的工作,它的處理單元雖十分簡單,但其工作卻是“集體”進行的,它的信息傳播、存儲方式與神經(jīng)網(wǎng)絡相似,它沒有運算器、存儲器、控制器等這些現(xiàn)代計算機的基本單元,而是相同的簡單處理器的組合,其信息處理是存儲在處理單元的連接上
模糊邏輯是模仿人腦的不確定性概念判斷、推理思維方式,對于模型未知或不能確定的描述系統(tǒng),以及非線性、大滯后的控制對象,應用模糊集合和模糊規(guī)則進行推理,表達過渡性界限或定性知識經(jīng)驗,模擬人腦方式,實行模糊綜合判斷,推理解決常規(guī)方法難于對付的規(guī)則型模糊信息問題。模糊邏輯善于表達界限不清晰的定性知識與經(jīng)驗,它借助于隸屬度函數(shù)概念,區(qū)分模糊集合,處理模糊關(guān)系,模擬人腦實施規(guī)則型推理,解決因“排中律”的邏輯破缺產(chǎn)生的種種不確定問題。
隨著模糊信息處理技術(shù)和神經(jīng)網(wǎng)絡技術(shù)研究的不斷深入,將模糊技術(shù)與神經(jīng)網(wǎng)絡技術(shù)進行有機結(jié)合,從而構(gòu)造出一種可“自動”處理模糊信息的神經(jīng)網(wǎng)絡或自適應模糊系統(tǒng),以成為模糊技術(shù)與神經(jīng)網(wǎng)絡技術(shù)深入研究和發(fā)展的一種必然趨勢。神經(jīng)網(wǎng)絡技術(shù)和模糊技術(shù)各自有自己的優(yōu)點,前者以生物神經(jīng)網(wǎng)絡為模擬基礎,試圖在模擬推理及自動學習方面向前發(fā)展一步,使人工智能更接近人腦的自組織和并行處理功能,它在模式識別、聚類分析和專家等多方面己顯示了新的前景和新的思路。后者以模糊邏輯為基礎,抓住了人類思維的模糊性特點,以模仿人的模糊綜合判斷推理來處理常規(guī)的方法難以解決的模糊信息處理的難題。而將模糊技術(shù)和神經(jīng)網(wǎng)絡技術(shù)相結(jié)合,可以有效的發(fā)揮各自的優(yōu)勢并彌補不足。模糊技術(shù)的特長在于拓展神經(jīng)網(wǎng)絡處理信息的范圍和能力,使其不僅能處理精確的信息也能處理模糊信息和其他不精確的信息,不僅能夠?qū)崿F(xiàn)精確的聯(lián)想及映射,還可以實現(xiàn)不精確的聯(lián)想和映射,特別是模糊聯(lián)想和模糊映射仁。
語音識別在實現(xiàn)過程中通常涉及多種因素,需要同時考慮。由于計算量很大,再加上語音信號的隨機性,以及我們對人類聽覺機理了解甚淺,因此,目前機器自動識別語音的能力要比人類差得多,尤其是對非特定人的連續(xù)語音識別更是如此。用模糊神經(jīng)網(wǎng)絡模型作為分類器或聚類器,發(fā)展出一些新的語音識別方法。
由于模糊神經(jīng)網(wǎng)絡不僅具有模糊系統(tǒng)中的知識抽取和表達能力,適合于表達模糊或定性的知識,能夠運用類似人的思維模式來進行推理,也擁有神經(jīng)網(wǎng)絡有并行計算、分布式信息存儲、容錯能力強以及具備自適應學習功能的一系列能力。將模糊神經(jīng)網(wǎng)絡模型用于語音識別系統(tǒng),該系統(tǒng)具有以下特點:。
1、能夠盡量多的利用了樣本集中的有用信息以實現(xiàn)多因素綜合評定,發(fā)揮神經(jīng)網(wǎng)絡的優(yōu)勢。
2、能夠很好的引入領(lǐng)域?qū)<业慕?jīng)驗知識,利用模糊規(guī)則來指導網(wǎng)絡的訓練,使網(wǎng)絡的訓練能夠更符合人的推理習慣。
3、對輸入、輸出形式進行特殊的模糊化處理后,可以用有限樣本集含有的信息比較好的、近似真實分布的反映原有知識
傳統(tǒng)的語音識別和采用模糊神經(jīng)網(wǎng)絡的語音識別是有區(qū)別的。在傳統(tǒng)的語音識別方法中,模式匹配法是在對語音做過預處理之后,通過特征參數(shù)的提取及模式匹配完成識別。由于語音信號的高度多變性,輸入模式要與標準模式完全匹配是幾乎不可能的。因此,識別時要預先制定好計算輸入的語音特征模式與各特征模式的類似或距離的規(guī)則,距離最小者就是最類似的模式。而句法模式識別法當認為輸入的位置模式屬于某個對象時,就要檢查一下輸入模式與識別對象的結(jié)構(gòu),當與對象模式結(jié)構(gòu)相同或在某范圍內(nèi)結(jié)構(gòu)一致時,則判定該未知模式就是識別對象的語音。模糊神經(jīng)網(wǎng)絡的語音識別方法與傳統(tǒng)方法的差異在于提取了語音的特征參數(shù)后,不像傳統(tǒng)方法那樣有輸入模式與標準模式的比較匹配,而是靠模糊神經(jīng)網(wǎng)絡根據(jù)專家知識或者先驗知識,先對輸入特征數(shù)據(jù)進行模糊化產(chǎn)生對不同規(guī)則的隸屬度,然后根據(jù)標準來調(diào)節(jié)網(wǎng)絡中大量的連接權(quán)對輸入模式進行非線性運算,產(chǎn)生最大興奮的輸入點就代表了輸入模式對應的分類。
模糊控制于20世紀六十年代萌芽于美國,七十年代誕生于歐洲,八十年代當西方人不太喜歡“模糊理論”時,它卻在日本發(fā)展并廣泛用于家電的自動控制,九十年代與神經(jīng)網(wǎng)絡以來,才得到全球的廣泛認可并成為智能系統(tǒng)的一個重要分支。雖然模糊神經(jīng)網(wǎng)絡的研究沒有神經(jīng)網(wǎng)絡長,但由于它結(jié)合了模糊控制和神經(jīng)網(wǎng)絡的優(yōu)點,現(xiàn)在以廣泛的用于各個領(lǐng)域。目前模糊神經(jīng)網(wǎng)絡在語音信號處理中的應用研究十分活躍,其中以在語音識別方面的應用已經(jīng)取得較大的進步。同神經(jīng)網(wǎng)絡相似,模糊神經(jīng)也主要是從聽覺神經(jīng)模型中得到啟發(fā),以便構(gòu)成一些具有類似能力的人工系統(tǒng),使它們在解決語音信號處理(特別是識別)問題時能得到較好的性能。研究模糊神經(jīng)網(wǎng)絡以探索人的聽覺神經(jīng)機理,改進現(xiàn)有語音語音識別系統(tǒng)的性能,是當前語音識別研究的一個重要方向。
模糊神經(jīng)元
模糊神經(jīng)網(wǎng)絡是全部或部分采用模糊神經(jīng)元構(gòu)成的一類可處理模糊信息的神經(jīng)網(wǎng)絡系統(tǒng)。模糊神經(jīng)元除具有普通鉀經(jīng)元的功能外,還具有處理模糊信息的能力。模糊神經(jīng)元按功能可分為
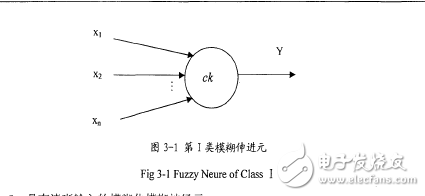
1.由模糊規(guī)則“工f-then”規(guī)則描述的模糊神經(jīng)元。該規(guī)則常用于表示專家知識,此類神經(jīng)元由此規(guī)則描述。
If x, and x2 and…x, then Y
這里x,,x2,。。。)x。是當前輸入,Y是神經(jīng)元的當前輸出。此模式中神經(jīng)元的經(jīng)驗存儲在模糊關(guān)系中,其中輸出由當前和過去的經(jīng)驗組成。
2.具有清晰輸入的模糊化模糊神經(jīng)元。
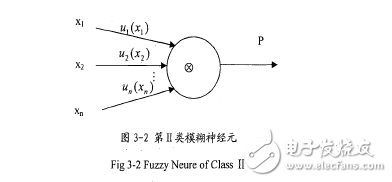
此神經(jīng)元有N個非模糊輸入,加權(quán)操作由隸屬度函數(shù)代替。每個加權(quán)操作的結(jié)果是模糊集中相應輸入的隸屬度值。由⑧表示的積累過程可利用MIN, MAX以及其它任意的T一范數(shù)或T一余范數(shù)。數(shù)學表示如下:
P(xl,x2,…,xn)=u, (x,)⑧U2 (X2)⑧,二⑧un (x,)(4. I)
x、是神經(jīng)元的第i個輸入,。(。)是第i個權(quán)值的隸屬度函數(shù),P為神經(jīng)元輸出,⑧表示累積算子。
3.具有模糊輸入的模糊化模糊神經(jīng)元。
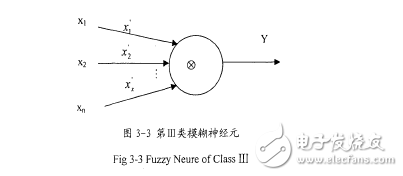
二類神經(jīng)元不同,這里的加權(quán)操作不是一個隸屬度函數(shù),而是對每個模糊輸入進行修正的操作。數(shù)學表示如下:
Y=x,⑧x2⑧…⑧xn(4.2)
x,=G; (x;)1=1)2,…,n (4.3)
這里Y是表示模糊神經(jīng)元輸出的模糊集,x,和瓦是加權(quán)操作之前和之后的第i個輸入。G;是第i個和突觸連接上的加權(quán)操作。
一個自適應神經(jīng)元可以通過權(quán)的修正來進行學習改進其性能,在模糊神經(jīng)元中還可以利用所謂“軀體”修正,即對神經(jīng)元體的結(jié)構(gòu)進行修改;可改變規(guī)則(If-then);改變分配給模糊子集的隸屬度函數(shù);改變表示規(guī)則的方式等。
模糊神經(jīng)網(wǎng)絡模型
目前,模糊神經(jīng)網(wǎng)絡模型絕大多數(shù)都是多層前向網(wǎng)絡結(jié)構(gòu),這與模糊推理的單向性質(zhì)有關(guān),由于神經(jīng)元的不同以及融入模糊成分的不同,使出現(xiàn)了不同性質(zhì)的模糊神經(jīng)網(wǎng)絡。各種模糊神經(jīng)網(wǎng)絡的主要區(qū)別在于隸屬函數(shù)、模糊加權(quán)算子、模糊激勵函數(shù)和輸入輸出的形式,以及結(jié)構(gòu)與參數(shù)的設定和調(diào)整方法。模糊神經(jīng)網(wǎng)絡的原理結(jié)構(gòu)圖,如圖4-4。
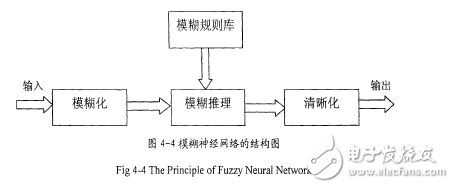
該網(wǎng)絡先通過模糊函數(shù)將輸入數(shù)據(jù)模糊化,然后對照專家知識形成的模糊規(guī)則庫對網(wǎng)絡進行模糊推理,最后對模糊推理的結(jié)果進行清晰化處理,得到最終的網(wǎng)絡輸出。由圖4-4的原理結(jié)構(gòu)圖可以得到基本的網(wǎng)絡構(gòu)成,如圖4-50
第一層:輸入層。輸入層的節(jié)點代表輸入語言變量,其作用是將輸入值傳送到下一層。
第二層:模糊化層。模糊化層是一個可將前提條件中的模糊變量的狀態(tài)轉(zhuǎn)化為基本狀態(tài)的網(wǎng)絡層,這種轉(zhuǎn)化的依據(jù)是定義在前提模糊變量定義域上的模糊子空間。這些模糊子空間與模糊推理前提條件中的基本模糊狀態(tài)相對應。
第三層:模糊推理層。模糊推理層聯(lián)系著模糊理論的前提與結(jié)論,準確的說是模糊推理的前提變量的基本模糊狀態(tài)和結(jié)論變量的基本狀態(tài)。其網(wǎng)絡參數(shù)即模糊推理過程中
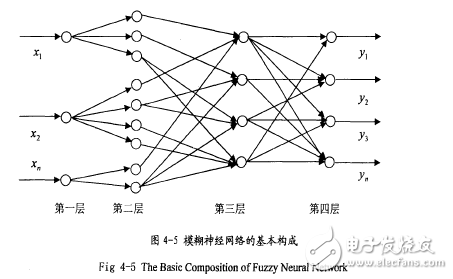
前提變量的基本模糊狀態(tài)和結(jié)論變量的基本模糊狀態(tài)之間的模糊關(guān)系,它們由具體問題所確定。
第四層:去模糊化層(即清晰化層)。去模糊化層是將推理結(jié)論變量的分布型基本模糊狀態(tài)轉(zhuǎn)化成確定狀態(tài)的網(wǎng)絡層。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論