完善資料讓更多小伙伴認識你,還能領取20積分哦,立即完善>
電子發燒友網技術文庫為您提供最新技術文章,最實用的電子技術文章,是您了解電子技術動態的最佳平臺。
數據集的任何變化都將提供一個不同的估計值,若使用統計方法過度匹配訓練數據集時,這些估計值非常準確。一個一般規則是,當統計方法試圖更緊密地匹配數據點,或者使用更靈活的方法時,偏差會減少,但方差會增加。...

最快的存儲器類型是SRAM,但每個SRAM單元需要六個晶體管,因此SRAM在SoC內部很少使用,因為它會消耗大量的空間和功率。...

使用卷積神經網絡(CNN)、支持向量機(SVM)、K近鄰(KNN)和長短期記憶(LSTM)神經網絡等四種不同的分類方法對三種步態模式進行自動分類。...

這些偏見特征可能導致模型在沒有明確提及這些偏見的情況下,系統性地歪曲其推理過程,從而產生不忠實(unfaithful)的推理。...

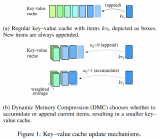
DMC通過一個決策變量(α)來有效地對輸入序列進行分段,每個段落可以獨立地決定是繼續追加還是進行累積。這允許模型在不同段落之間動態調整內存使用。...
RZ/V2L還與RZ/G2L封裝和引腳兼容。這使得RZ/G2L用戶可輕松升級至RZ/V2L,以獲得額外的人工智能功能,而無需修改系統配置,從而保持低遷移成本。...
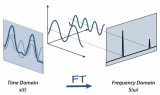
連續傅里葉變換(CFT)和離散傅里葉變換(DFT)是兩個常見的變體。CFT用于連續信號,而DFT應用于離散信號,使其與數字數據和機器學習任務更加相關。...
訓練經過約50次左右迭代,在訓練集上已經能達到99%的正確率,在測試集上的正確率為90.03%,單純的BP神經網絡能夠提升的空間不大了,但kaggle上已經有人有卷積神經網絡在測試集達到了99.3%的準確率。...
通用大型語言模型(LLM)推理基準:研究者們介紹了多種基于文本的推理任務和基準,用于評估LLMs在不同領域(如常識、數學推理、常識推理、事實推理和編程)的性能。這些研究包括BIG-bench、HELM、SuperGLUE和LAMA等。...

基于神經網絡技術,僅利用相對于傳統態層析方法50%的測量基數目,即可實現平均保真度高達97.5%的開放光量子行走的完整混合量子態表征。...
GEAR框架通過結合三種互補的技術來解決這一挑戰:首先對大多數相似幅度的條目應用超低精度量化;然后使用低秩矩陣來近似量化誤差。...

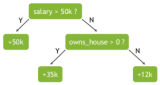
隨機森林使用名為“bagging”的技術,通過數據集和特征的隨機自助抽樣樣本并行構建完整的決策樹。雖然決策樹基于一組固定的特征,而且經常過擬合,但隨機性對森林的成功至關重要。...
一對其余其實更加好理解,每次將一個類別作為正類,其余類別作為負類。此時共有(N個分類器)。在測試的時候若僅有一個分類器預測為正類,則對應的類別標記為最終的分類結果。...
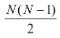
深度學習的效果在某種意義上是靠大量數據喂出來的,小目標檢測的性能同樣也可以通過增加訓練集中小目標樣本的種類和數量來提升。...

不同于上述工作從待干預模型自身抽取引導向量,我們意在從LLMs預訓練過程的切片中構建引導向量來干預指令微調模型(SFT Model),試圖提升指令微調模型的可信能力。...
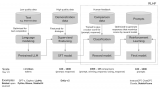
在大模型的發展史上,Scaling Law(規模律)發揮了核心作用,它是推動模型性能持續提升的主要動力。Scaling Law揭示了這樣一個現象:較小的語言模型只能解決自然語言處理(NLP)中的部分問題,但隨著模型規模擴大——參數數量增加至數十億甚至數百億,曾經在NLP領域中的棘手難題往往能得到有效...

首先看吞吐量,看起來沒有什么違和的,在單卡能放下模型的情況下,確實是 H100 的吞吐量最高,達到 4090 的兩倍。...
Nvidia是一個同時擁有 GPU、CPU和DPU的計算芯片和系統公司。Nvidia通過NVLink、NVSwitch和NVLink C2C技術將CPU、GPU進行靈活連接組合形成統一的硬件架構,并于CUDA一起形成完整的軟硬件生態。...

人工智能在早期誕生了一個“不甚成功”的流派,叫做“人工神經網絡”。這個技術的思路是,人腦的智慧無與倫比,要實現高級的人工智能,模仿人腦就是不二法門。...
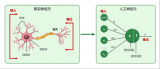
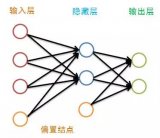
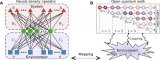
人工神經網絡模型 AI芯片的核心原理基于人工神經網絡,其中芯片內部的處理單元模擬了生物神經元的工作機制。每一個處理單元能夠獨立進行復雜的數學運算,例如權重乘以輸入信號并累加,形成神經元的激活輸出。...
關注我們的微信

下載發燒友APP

電子發燒友觀察

版權所有 ? 湖南華秋數字科技有限公司
長沙市望城經濟技術開發區航空路6號手機智能終端產業園2號廠房3層(0731-88081133)
電子發燒友 (電路圖) 湘公網安備43011202000918 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1




