完善資料讓更多小伙伴認識你,還能領取20積分哦,立即完善>
電子發燒友網技術文庫為您提供最新技術文章,最實用的電子技術文章,是您了解電子技術動態的最佳平臺。
Transformer模型在強化學習領域的應用主要是應用于策略學習和值函數近似。強化學習是指讓機器在與環境互動的過程中,通過試錯來學習最優的行為策略。...

2023年迎來“知識生產力變革”第一浪,以大語言模型為核心,實現知識工程的生產力變革,類似于中世紀的印刷革命。大語言模型具有超高速學習能力,可在人機協同模式下顯著提高知識學習、搜索、傳播速度和準確性。...

LangChain通過Loader加載外部的文檔,轉化為標準的Document類型。Document類型主要包含兩個屬性:page_content 包含該文檔的內容。meta_data 為文檔相關的描述性數據,類似文檔所在的路徑等。...
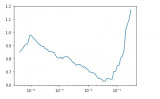
還有一個與批次大小有關的數量,它們在一個有趣的點上相交。這個點不取決于硬件之外的任何因素。舉例來說,在 A10G 和 A100 上,硬件可以實現的總浮點運算次數的兩倍除以內存帶寬為 400。...
偏置(bias)是什么?這很好理解,偏置是當前模型的平均預測結果與我們需要預測的實際結果之間的差異。當模型的偏置較高時,說明其不夠關注訓練數據。...

因為大部分人使用的模型都是預訓練模型,使用的權重都是在大型數據集上訓練好的模型,當然不需要自己去初始化權重了。只有沒有預訓練模型的領域會自己初始化權重,或者在模型中去初始化神經網絡最后那幾個全連接層的權重。...
借助對比學習和元學習的方法。增加對比學習的loss,對比學習通過增強模型區分能力,來增強RM的對好壞的區分水平。元學習則使獎勵模型能夠維持區分分布外樣本的細微差異,這種方法可以用于迭代式的RLHF優化。...

TurboTransformers算是比較早期指出輸入變長需要新的Batching方法的論文。在2020年上半年,我開始思考如何把變長輸入Batching方法擴展到Decoder架構中。...
“操作系統管理著計算機的資源和進程,以及所有的硬件和軟件。計算機的操作系統讓用戶在不需要了解計算機語言的情況下與計算機進行交互。”這是我們對計算機系統的最初理解。...

AI可以被用來進行自動化網絡攻擊,這種攻擊更加隱蔽、快速和難以防御。例如,AI可以快速識別和利用軟件漏洞,或者通過機器學習來提升釣魚攻擊的成功率。...
數據基礎設施是從數據要素價值釋放的角度出發,在網絡、算力等設施的支持下,面向社會提供一體化數據匯聚、處理、流通、應用、運營、安全保障服務的一類新型基礎設施,是覆蓋硬件、軟件、開源協議、標準規范、機制設計等在內的有機整體。...
重要的是如何計算輸出矩陣中的每個單獨元素,這可以歸結為兩個非常大的向量的點積 - 在上面的示例中,大小為 12288。這由 12288 次乘法和 12277 次加法組成,它們累積成一個數字– 輸出矩陣的單個元素。...

David Bourgin 表示他一直在慢慢寫或收集不同模型與模塊的純 NumPy 實現,它們跑起來可能沒那么快,但是模型的具體過程一定足夠直觀。每當我們想了解模型 API 背后的實現,卻又不想看復雜的框架代碼,那么它可以作為快速的參考。...
長期來看,國產CPU、GPU、AI芯片廠商受益于龐大的國內市場,疊加國內信創市場帶來國產化需求增量,我們預期國內AI芯片的國產化比例將顯著提升,借此機會進行產品升級,逐漸達到國際先進水平,突破封鎖。...

當下智算時代雖然在初級階段,依托AI大模型形成的新一代算力基礎設施和AI應用已經在諸多領域嶄露頭角。 數字中國愿景的實現,基石在于夯實數字化基礎設施建設。...

微軟在全球擁有超過10.5萬名安全和威脅情報專家,為政府提供關于網絡安全的寶貴見解。該公司每天合成64萬億個信號,使用復雜的數據分析,并擁有人工智能算法來抵御網絡威脅。...
大模型的參數量主要取決于隱藏層的維度和構成模型的Block的數量,我們假定隱藏層的維度為 h,Block 的數量為 i,那么,大模型的參數量為 。...
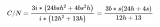
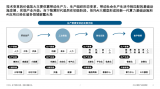
AI賽道投資火熱,基建與應用兩端爆發 當前中國資本市場對于AI領域的主要關注在兩端:前端基礎設施部署及后端應用開發;AI相關應用開發正由虛轉實,落地實體經濟的場景應用結合AI原生應用的組合布局初見端倪。...
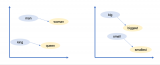
許多早期的機器學習算法需要人工標記訓練示例。例如,訓練數據可能是帶有人工標簽("狗"或"貓")的狗或貓的照片。人們需要標記數據的需求使得創建足夠大的數據集來訓練強大的模型變得困難且昂貴。...
關注我們的微信

下載發燒友APP

電子發燒友觀察

版權所有 ? 湖南華秋數字科技有限公司
長沙市望城經濟技術開發區航空路6號手機智能終端產業園2號廠房3層(0731-88081133)
電子發燒友 (電路圖) 湘公網安備43011202000918 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1




