完善資料讓更多小伙伴認識你,還能領取20積分哦,立即完善>
電子發燒友網技術文庫為您提供最新技術文章,最實用的電子技術文章,是您了解電子技術動態的最佳平臺。
隨機實驗的所有可能結果都是隨機變量。一個隨機變量集合用 表示。 如果實驗可能的結果是可數的,那么它被稱為離散隨機變量。例如,如果你拋硬幣 10 次,你能得到的正面數可以用一個數字表示。...
定位準確性:與六種最新的里程計和SLAM方法進行比較,包括KISS-ICP、LeGO-LOAM、SC-LeGO-LOAM、MULLS、CT-ICP和GeoTransformer。在SemanticKITTI、KITTI-360和MulRan數據集上比較了DeepPointMap與這些方法的定位準確性...

在今年 5 月的 Google I/O 大會上,皮查伊首次透露了 Google 正在研發一款多模態基礎模型 Gemini,下一步 Google 所有產品都將基于它們,包括 Google Bard、搜索、云。...

處理傳感器信息并實時計算當前幀在激活地圖中的姿態。同時該模塊也決定了是否將當前幀作為關鍵幀。在視覺-慣性模式下,通過在優化中加入慣性殘差來估計剛體速度和 IMU 偏差。...
在本問題 如何通俗易懂地解釋卷積?中排名第一的馬同學在中舉了一個很好的例子(下面的一些圖摘自馬同學的文章,在此表示感謝),用丟骰子說明了卷積的應用。...
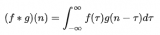
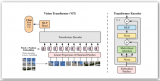
AlexNet:在第一個卷積中使用了11x11卷積,第一次使用Relu,使用了NormLayer但不是我們經常說的BN。使用了dropout,在兩個GPU上進行了訓練,使用的訓練方式是模型并行、...

在深度學習出現之前,自然圖像中的對象識別過程相當粗暴簡單:定義一組關鍵視覺特征(“單詞”),識別每個視覺特征在圖像中的存在頻率(“包”),然后根據這些數字對圖像進行分類。這些模型被稱為“特征包”模型(BoF模型)。...
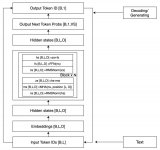
LLM 中非常重要的一個概念是 Token,我們輸入給 LLM 和它輸出的都是 Token。Token 在這里可以看做語言的基本單位,中文一般是詞或字(其實字也是詞)。比如:”我們喜歡 Rust 語言“,Token 化后會變成類似 ”我們/喜歡/Rust/語言“ 這樣的四個詞,可以理解為四個 Tok...
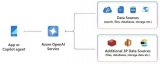
通過豐富數據,生成式 AI 應用程序可以提供上下文感知交互。 LLM 驅動的功能通常依賴于特定的專有數據。簡化從多個來源引入數據對于創建平滑有效的模型至關重要。為了使擴充更加動態,引入模板可能是有益的。...
人工智能這個詞的含義非常廣泛。它代表了算法和信息處理策略的集合。其中許多概念已經存在了很長一段時間,有些可以追溯到20世紀40年代。由巨大的處理能力支持的新應用策略組合創造了我們現在正在目睹的革命...
AdaBoost(自適應增強)是機器學習歷史上第一個將各種弱分類器組合成單個強分類器的增強算法。它主要致力于解決二元分類等分類任務。...
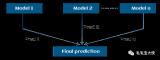
大模型在語言理解、決策制定以及泛化能力等方面展現出強大的潛力,成為代理構建過程中的關鍵角色,而代理的進展也為大模型提出了更高的要求。...
由于深度學習,圖像識別和計算機視覺任務的性能得到了顯著提高。由于在龐大的數據集上訓練深度神經網絡,計算機現在可以可靠地分類和理解圖像,從而開辟了廣泛的應用。 智能手機應用程序可以從照片中快速確定狗的品種,以及采用計算機視覺算法檢測行人、交通標志和其他路障以實現安全導航的自動駕駛汽車,是實踐中的兩個例...
筆者考慮了兩種方案。 一是徹底解決網絡問題,但難度有點大。這屬于 OpenAI 服務器問題,即使是部署在國外的服務器也會出現超時的情況。 二是利用自動重試解決問題。通過調整超時的時間,提升響應速度,方案可行。...
AWS最新推出的Trainium2 AI訓練引擎在re:Invent 2023主機上首次亮相,引起廣泛關注,通過與AWS實驗室的Gadi Hutt的交流和對技術文檔的挖掘,可以試圖深入了解Trainium2與之前Inferentia系列的關系以及對Trainium2的期望。...

AI算力需求的提升給中國本土芯片廠商的發展提供了較大的空間,帶來新的機遇。IDC預計,2023年中國人工智能芯片出貨量將達到133.5萬片,同比增長 22.5%。...
在大型語言模型(LLMs)的應用中,提示工程(Prompt Engineering)是一種關鍵技術,用于引導模型生成特定輸出或執行特定任務。通過精心設計的提示,可以顯著提高LLMs的性能和適用性。本文將介紹提示工程的主要方法和技巧,包括少樣本提示、提示壓縮和提示生成。...
三維集成電路最近慢慢開始熱起來,摩爾定律一直在發展,而且發展的過程中密度越來越高。現在5nm工藝可以在一個平方毫米上集成大概1.1億只晶體管,也就是2800個邏輯門。我們的集成能力已經大于能夠實現的芯片了。...
許多DGX H100服務器又可以組成所謂的SuperPOD,其中各個獨立服務器中的加速器仍可使用NVLink傳輸數據,但耦合程度較低。每個SuperPOD使用以太網和Infiniband連接到另一個SuperPOD。服務器之間的網絡拓撲也會影響計算集群的整體性能。...

GPT 想必大家已經耳熟能詳,當我們與它進行對話時,通常只需關注自己問出的問題(輸入)以及 GPT 給出的答案(輸出),對于輸出內容是如何產生的,我們一無所知,它就像一個神秘的黑盒子。?...

關注我們的微信

下載發燒友APP

電子發燒友觀察

版權所有 ? 湖南華秋數字科技有限公司
長沙市望城經濟技術開發區航空路6號手機智能終端產業園2號廠房3層(0731-88081133)
電子發燒友 (電路圖) 湘公網安備43011202000918 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1




