完善資料讓更多小伙伴認(rèn)識你,還能領(lǐng)取20積分哦,立即完善>
電子發(fā)燒友網(wǎng)技術(shù)文庫為您提供最新技術(shù)文章,最實(shí)用的電子技術(shù)文章,是您了解電子技術(shù)動態(tài)的最佳平臺。
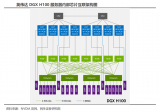
DXG 服務(wù)器配備 8 塊 H100 GPU,6400億個(gè)晶體管,在全新的 FP8 精度下 AI 性能比上一代高 6 倍,可提供 900GB/s 的帶寬。...
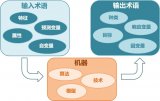
AI是計(jì)算機(jī)科學(xué)的分支領(lǐng)域,專注在創(chuàng)建擁有人類智能行為的系統(tǒng)或機(jī)器,其目標(biāo)為模擬人類的各種認(rèn)知功能,包含學(xué)習(xí)、推理、解決問題、感知、語言理解等等。AI涵蓋了各種技術(shù)領(lǐng)域,如機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、自然語言處理、計(jì)算機(jī)視覺、機(jī)器人等。...
在監(jiān)督式學(xué)習(xí)下,輸入數(shù)據(jù)被稱為“訓(xùn)練數(shù)據(jù)”,每組訓(xùn)練數(shù)據(jù)有一個(gè)明確的標(biāo)識或結(jié)果,如對防垃圾郵件系統(tǒng)中“垃圾郵件”“非垃圾郵件”,對手寫數(shù)字識別中的“1“,”2“,”3“,”4“等。...
從評測能力上來看,由于目前的評測數(shù)據(jù)集主要是利用人類試題及其標(biāo)準(zhǔn)答案進(jìn)行評測,這種評價(jià)方式更偏向?qū)ν评砟芰Φ脑u估,存在評估結(jié)果和模型真實(shí)能力有?定偏差。...
作為通用序列模型的骨干,Mamba 在語言、音頻和基因組學(xué)等多種模態(tài)中都達(dá)到了 SOTA 性能。在語言建模方面,無論是預(yù)訓(xùn)練還是下游評估,他們的 Mamba-3B 模型都優(yōu)于同等規(guī)模的 Transformer 模型,并能與兩倍于其規(guī)模的 Transformer 模型相媲美。...

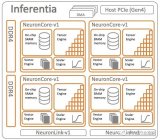
Trainium1 芯片于 2020 年 12 月發(fā)布,并以兩個(gè)不同的實(shí)例(Trn1 和 Trn1n)發(fā)貨。我們當(dāng)時(shí)對 Trainium1 和2021 年 12 月的這些實(shí)例進(jìn)行了盡可能多的分析,坦率地說,AWS 沒有提供大量有關(guān)這些本土 AI 計(jì)算引擎的數(shù)據(jù)。...
作者對Transformer Block移除了各種參數(shù),減少了15%參數(shù)量,提高了15%的訓(xùn)練速度,各個(gè)環(huán)節(jié)都有做充分的實(shí)驗(yàn),但一些經(jīng)驗(yàn)性得到的結(jié)論也并沒有直接回答一些問題(如LN為什么影響收斂速度)。...
本文對比了多種基線方法,包括無監(jiān)督域自適應(yīng)的傳統(tǒng)方法(如Pseudo-labeling和對抗訓(xùn)練)、基于檢索的LM方法(如REALM和RAG)和情境學(xué)習(xí)方法(如In-context learning)。...

以太網(wǎng)是一種廣泛使用的網(wǎng)絡(luò)協(xié)議,但其傳輸速率和延遲無法滿足大型模型訓(xùn)練的需求。相比之下,端到端IB(InfiniBand)網(wǎng)絡(luò)是一種高性能計(jì)算網(wǎng)絡(luò),能夠提供高達(dá) 400 Gbps 的傳輸速率和微秒級別的延遲,遠(yuǎn)高于以太網(wǎng)的性能。這使得IB網(wǎng)絡(luò)成為大型模型訓(xùn)練的首選網(wǎng)絡(luò)技術(shù)。...

在傳統(tǒng)“小”模型方法中,需要對訓(xùn)練數(shù)據(jù)進(jìn)行構(gòu)建,例如訓(xùn)練一個(gè)分類模型,以便將用戶的問題分類為不同的意圖。同樣,回答用戶問題的方式也需要模型的處理,因?yàn)槭酆髥栴}的多樣性,有的需要直接回答,有的需要引導(dǎo)用戶執(zhí)行一系列步驟來解決。...
使用了LLaMA-13B來訓(xùn)練模型和獎勵模型,使用BAD模型作為有害內(nèi)容檢測模型。...

Copilot 最初是由 GitHub/Microsoft 和 OpenAI 合作推出的開發(fā)項(xiàng)目,致力于輔助軟件開發(fā)人員編寫代碼,提供諸如將代碼注釋轉(zhuǎn)換為可運(yùn)行代碼、自動完成代碼塊、代碼重復(fù)部分以及整個(gè)方法和/或函數(shù)等功能。...

我們使用LLAMA2-7B作為實(shí)驗(yàn)的基礎(chǔ)模型。我們主要評估將舊知識更新為新知識的能力,因此模型將首先在舊知識上進(jìn)行為期3個(gè)時(shí)期的微調(diào)。表1中F-Learning中設(shè)置的超參數(shù)λ分別取值為0.3、0.7、0.1和1.5。...

PanopticNeRF-360是PanopticNeRF的擴(kuò)展版本,借助3D粗標(biāo)注快速生成大量的新視點(diǎn)全景分割和RGB圖,并引入幾何-語義聯(lián)合優(yōu)化來解決交叉區(qū)域的類別模糊問題,對于數(shù)據(jù)標(biāo)注領(lǐng)域有一定價(jià)值。...

在研究人員選擇的模型中,GPT-3 davinci(非指令微調(diào))、GPT-3 textdavinci-001(指令微調(diào))和GPT-3 textdavinci-003(InstructGPT)都是以前觀察到過涌現(xiàn)能力的模型。這一選擇主要是出于模型可用性的考慮。...
大模型當(dāng)前以生成類應(yīng)用為主,多模態(tài)是未來重點(diǎn)發(fā)展方向 企業(yè)用戶是從應(yīng)用視角出發(fā),分成生成類應(yīng)用、決策類應(yīng)用和多模態(tài)應(yīng)用。 受限于模型能力、應(yīng)用效果等因素,當(dāng)前階段以生成類應(yīng)用為主。...

未來全球服務(wù)器市場規(guī)模有望超萬億。長遠(yuǎn)來看,在國內(nèi)外數(shù)據(jù)流量迅速增長以及公有云蓬勃發(fā)展的背景下,服務(wù)器作為云網(wǎng)體系中最重要的算力基礎(chǔ)設(shè)施,未來存在巨大的成長空間,預(yù)計(jì)2027年市場規(guī)模將超萬億元(1891.4億美元)。...

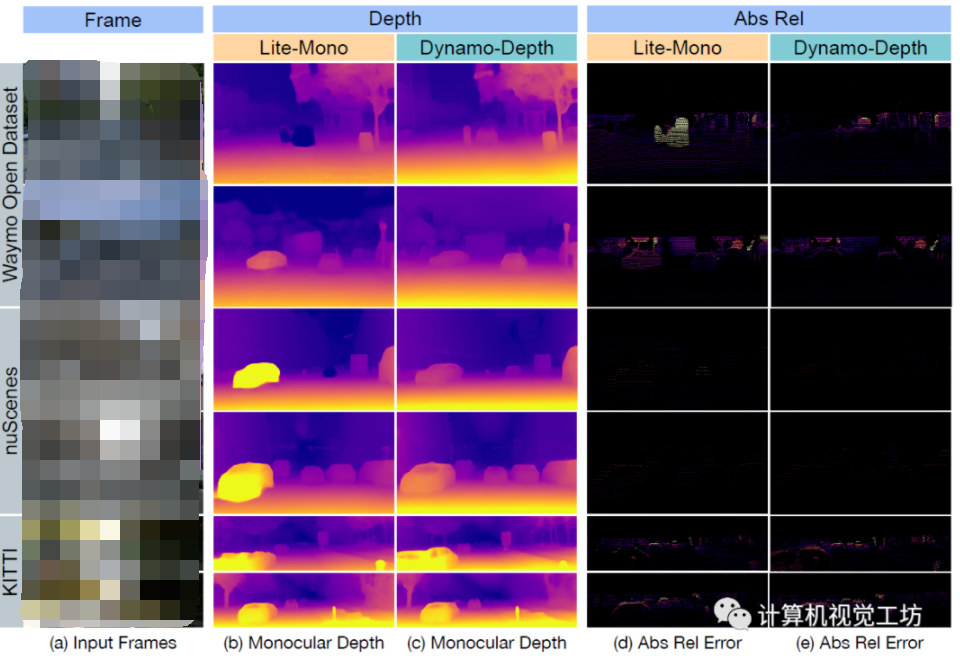
自監(jiān)督單目深度估計(jì)的訓(xùn)練可以在大量無標(biāo)簽視頻序列來進(jìn)行,訓(xùn)練集獲取很方便。但問題是,實(shí)際采集的視頻序列往往會有很多動態(tài)物體,而自監(jiān)督訓(xùn)練本身就是基于靜態(tài)環(huán)境假設(shè),動態(tài)環(huán)境下會失效。...
AI服務(wù)器按芯片類型可分為CPU+GPU、CPU+FPGA、CPU+ASIC等組合形式,CPU+GPU是目前國內(nèi)的主要選擇(占比91.9%);AI服務(wù)器的成本主要來自CPU、GPU等芯片,占比25%-70%不等,對于訓(xùn)練型服務(wù)器其80%以上的成本來源于CPU和GPU。...

關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1




