使用BLIP-2 零樣本“圖生文”
現代計算機視覺和自然語言模型在能力越來越強大的同時,模型尺寸也隨之顯著增大。由于當前進行一次單模態模....
LeCun新作:全面綜述下一代「增強語言模型」
最近圖靈獎得主Yann LeCun參與撰寫了一篇關于「增強語言模型」的綜述,回顧了語言模型與推理技能....
深入淺出Prompt Learning要旨及常用方法
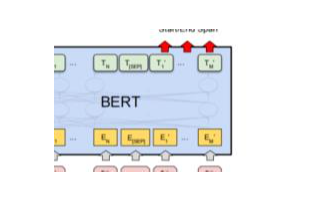
第三范式:基于預訓練模型 + finetuning 的范式,如 BERT + finetuning ....
SimANS:簡單有效的困惑負樣本采樣方法
為訓練該稠密檢索模型,已有方法通常基于一對比學習訓練目標,即拉近語義一致的Query和Documen....
LLaMA論文研讀:小參數+大數據的開放、高效基礎語言模型閱讀筆記
這些努力都是基于這樣的假設:更多的參數會帶來更好的性能。然而,Hoffmann等人(2022)最近的....
小程序:ChatGPT-Plus助手發布啦!
在智能客服系統中,ChatGPT技術可以用于自動化的問題解答,為用戶提供更加智能、高效的服務。例如,....
Language Model Reasoning是什么意思?
那么,前面總是提到推理 (Reasoning) 這個詞,什么是推理?我嘗試用自己的語言來解釋“推理”....
復旦大學NLP實驗室《自然語言處理導論》 網絡初版發布
復旦大學自然語言處理實驗室張奇教授、桂韜研究員以及黃萱菁教授從2020年起著手教材的規劃,結合自己對....
AI超級幫手的用法大全
它可以根據提供的關鍵詞或主題生成相關領域的文本,并提供有關行業趨勢,市場規模和其他相關信息。此外,它....
什么是query理解?query理解目前的主要作用
但需要強調的,是為什么我們要去做query理解,因為它存在的意義才是我們持續討論他在后續chatgp....
介紹一種基于Transformer的大語言模型
大模型的研究者和大公司出于不同的動機站位 LLM,研究者出于對 LLM 的突現能力 (emergen....
介紹NMT模型魯棒性對抗訓練的三部曲
本文的問題引入為一個小實驗,即將機器翻譯的源句進行微小擾動(同義詞替換),69.74%的翻譯句子也隨....
以transformers框架實現中文OFA模型的訓練和推理
OFA是阿里巴巴發布的多模態統一預訓練模型,基于官方的開源項目,筆者對OFA在中文任務上進行了更好的....
介紹一種信息抽取的大一統方法USM
信息抽取任務具有多樣的抽取目標和異構的結構,而傳統的模型需要針對特定的任務進行任務設計和標簽標注,這....
chatgpt下非端到端方案是否還有意義
其實端到端和非端到端的競爭,早在前幾年就有了,DSTC對話系統的比賽,榜單上就已經分為了端到端和非端....
詳細分析14種可用于時間序列預測的損失函數
在處理時間序列預測問任務時,損失函數的選擇非常重要,因為它會驅動算法的學習過程。以往的工作提出了不同....
性別偏見探索和緩解的中文數據集-CORGI-PM
大規模語言模型(LMs)已經成為了現在自然語言處理的關鍵技術,但由于訓練語料中常帶有主觀的性別偏見、....
解讀ChatGPT背后的技術重點:RLHF、IFT、CoT、紅藍對抗
我們先來看看基于語言模型的會話代理的全景。ChatGPT 并非首創,事實上很多組織在 OpenAI ....
一個真實閑聊多模態數據集TikTalk
隨著大量預訓練語言模型在文本對話任務中的出色表現,以及多模態的發展,在對話中引入多模態信息已經引起了....
一文淺談Graph Transformer領域近期研究進展
本文提出了幾種自動生成子圖表示的方法,并從理論上表明,生成的表示至少與子圖表示具有相同的表達能力。該....
一種靈活有效的事件抽取數據增強框架-Mask-then-Fill
事件抽取,即從非機構化文本中抽取指定的事件的觸發詞及其事件要素,為了減輕人工標注,常采用數據增強方法....
深度學習頂級學術會議ICLR 2023錄用結果已經公布!
在機器學習社區中,ICLR 是較為「年輕」的學術會議,它由深度學習巨頭、圖靈獎獲得者 Yoshua ....
視覺-語言預訓練入門指南
視覺-語言 (Vision-Language, VL) 是計算機視覺和自然語言處理這兩個研究領域之間....
有了Fine-tune-CoT方法,小模型也能做推理,完美逆襲大模型
如果給語言模型生成一些 prompting,它還向人們展示了其解決復雜任務的能力。標準 prompt....
具有Event-Argument相關性的事件因果關系提取方法
事件因果關系識別(ECI)旨在檢測兩個給定文本事件之間是否存在因果關系,是事件因果關系理解的重要任務....
Prompt Tuning相比于Fine Tuning在哪些場景下表現更好?
第三范式:基于「預訓練模型 + finetuning」的范式,如 BERT + finetuning....
文本分割技術的應用場景
這些文本通常都非常長,需要利用文本分割技術來處理這些文本,將它們按照主題的轉移或變化劃分為若干主題段....
基于預訓練語言模型的行業搜索的應用和研究
面向產業和消費互聯網的搜索本質都是一樣的:用戶有信息獲取需求,同時有信息資源庫,通過搜索引擎把兩者橋....





 工商網監
工商網監