大模型由于其在各種任務中的出色表現而引起了廣泛的關注。然而,大模型推理的大量計算和內存需求對其在資源....

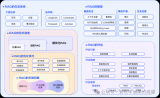
高級的RAG能很大程度優化原始RAG的問題,在索引、檢索和生成上都有更多精細的優化,主要的優化點會集....
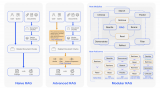
MoE 與 MoT:在專家混合中(左),每個令牌都被路由到不同的專家前饋層。在令牌混合(右)中,每組....
這篇論文試圖解決的問題是大型預訓練模型在下游任務中進行微調時出現的過擬合問題。盡管低秩適應(LoRA....

在選擇k值時,較大的值會使生成的內容更具多樣性,但可能會生成不合理的內容;較小的值則使生成的內容多樣....

斯坦福大學此前提出的FlashAttention算法,能夠在BERT-large訓練中節省15%,將....
對于所有“基座”(Base)模型,–template 參數可以是 default, alpaca, ....
NLP上估計會幫助reduce overfitting, improve generalizatio....
篇論文主要研究了大型語言模型(LLMs)中的一個現象,即在模型的隱藏狀態中存在極少數激活值(acti....

對于語言模型(LLM)幻覺,知識圖譜被證明優于向量數據庫。知識圖譜提供更準確、多樣化、有趣、邏輯和一....

向量數據庫是一組高維向量的集合,用于表示實體或概念,例如單詞、短語或文檔。向量數據庫可以根據實體或概....
Meta 發布的 LLaMA 2,是新的 sota 開源大型語言模型 (LLM)。LLaMA 2 代....
基于1.1中的思想,我們在V2中將原本的內外循環置換了位置(示意圖就不畫了,基本可以對比V1示意圖想....

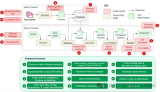
準確解釋用戶查詢以檢索相關的結構化數據是困難的,特別是在面對復雜或模糊的查詢、不靈活的文本到SQL轉....
通過SFT、DPO、RLHF等技術訓練了領域寫作模型。實測下來,在該領域寫作上,強于國內大多數的閉源....
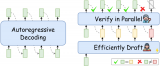
在思維鏈(CoT)提示的幫助下,大語言模型(LLMs)展現出強大的推理能力。然而,思維鏈已被證明是千....
這個問題隨著LLM規模的增大愈發嚴重。并且,如下左圖所示,目前LLM常用的自回歸解碼(autoreg....
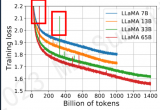
.通常CPT開始的階段會出現一段時間的loss上升,隨后慢慢收斂,所以學習率是一個很重要的參數,這很....
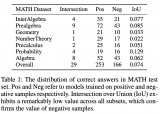
盡管大語言模型能力不斷提升,但一個持續存在的挑戰是它們具有產生幻象的傾向。本文構建了幻象評測基準Ha....
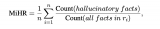
這是任何RAG流程的最后一步——基于我們仔細檢索的所有上下文和初始用戶查詢生成答案。最簡單的方法可能....
單模態大模型,通常大于100M~1B參數。具有較強的通用性,比如對圖片中任意物體進行分割,或者生成任....

這個“gradient”怎么得到的了呢,這是個啥玩意,怎么還有梯度?注意,注意。人家是帶引號的!比喻....
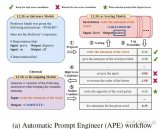
PaLM和GLM130b之前的解決辦法是找到loss spike之前最近的checkpoint,更換....
Reward Model的初始化:6B的GPT-3模型在多個公開數據((ARC, BoolQ, Co....
vLLM 中,LLM 推理的 prefill 階段 attention 計算使用第三方庫 xform....

幾天前,OpenAI「超級對齊」(Superalignment)團隊發布了成立以來的首篇論文,聲稱開....
今天對百川的RAG方法進行解讀,百川智能具有深厚的搜索背景,來看看他們是怎么爬RAG的坑的吧~
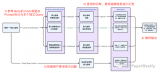
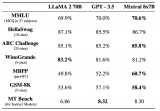
我們都知道,OpenAI 團隊一直對 GPT-4 的參數量和訓練細節守口如瓶。Mistral 8x7....
近期的大語言模型(LLM)在自然語言理解和生成上展現出了接近人類的強大能力,遠遠優于先前的BERT等....

隨著開源預訓練大型語言模型(Large Language Model, LLM )變得更加強大和開放....






 工商網監
工商網監